




In-Database Time Series Clustering.pdf
100墨值下载
In-Database Time Series Clustering
YUNXIANG SU, Tsinghua University, China
KENNY YE LIANG, Tsinghua University, China
SHAOXU SONG
∗
, BNRist, Tsinghua University , China
Time series data are often clustered repeatedly across various time ranges to mine frequent subsequence
patterns from dierent periods, which could further support downstream applications. Existing state-of-the-art
(SOTA) time series clustering method, such as K-Shape, can prociently cluster time series data referring
to their shapes. However, in-database time series clustering problem has been neglected, especially in IoT
scenarios with large-volume data and high eciency demands. Most time series databases employ LSM-Tree
based storage to support intensive writings, yet causing underlying data points out-of-order in timestamps.
Therefore, to apply existing out-of-database methods, all data points must be fully loaded into memory and
chronologically sorted. Additionally, out-of-database methods must cluster from scratch each time, making
them inecient when handling queries across dierent time ranges. In this work, we propose an in-database
adaptation of SOTA time series clustering method K-Shape. Moreover, to solve the problem that K-Shape
cannot eciently handle long time series, we propose Medoid-Shape, as well as its in-database adaptation
for further acceleration. Extensive experiments are conducted to demonstrate the higher eciency of our
proposals, with comparable eectiveness. Remarkably, all proposals have already been implemented in an
open-source commodity time series database, Apache IoTDB.
CCS Concepts: • Information systems
→
Database query processing; • Computing methodologies
→
Machine learning.
Additional Key Words and Phrases: time series clustering, database query processing
ACM Reference Format:
Yunxiang Su, Kenny Ye Liang, and Shaoxu Song. 2025. In-Database Time Series Clustering. Proc. ACM Manag.
Data 3, 1 (SIGMOD), Article 46 (February 2025), 26 pages. https://doi.org/10.1145/3709696
1 Introduction
Time series clustering is of great importance for analysis. For example, time series clustering
could assist pattern mining of daily stock prices in nance [
33
], serve anomalous subsequence
detection for yearly climate analysis in meteorology [
21
], facilitate the analysis of the characteristics
associated with sleep apnea [
25
] and so on. The state-of-the-art (SOTA) time series clustering
method K-Shape [
31
,
32
] can prociently cluster time series by shapes and achieve signicantly
better accuracy than other existing time series clustering methods.
However, K-Shape unfortunately faces challenges when meeting IoT scenarios, where extensive
time series data stored in databases pose serious challenges for time series clustering. On the one
hand, the arrival of IoT data is often out-of-order, due to transmission issues or sensor failures [
15
].
Most commodity time series databases employ Log Structured Merged Tree (LSM-Tree) [
30
] to
∗
Shaoxu Song (https://sxsong.github.io/) is the corresponding author.
Authors’ Contact Information: Yunxiang Su, Tsinghua University, China, suyx21@mails.tsinghua.edu.cn; Kenny Ye Liang,
Tsinghua University, China, liangy24@mails.tsinghua.edu.cn; Shaoxu Song, BNRist, Tsinghua University , China, sxsong@
tsinghua.edu.cn.
This work is licensed under a Creative Commons Attribution International 4.0 License.
© 2025 Copyright held by the owner/author(s).
ACM 2836-6573/2025/2-ART46
https://doi.org/10.1145/3709696
Proc. ACM Manag. Data, Vol. 3, No. 1 (SIGMOD), Article 46. Publication date: February 2025.
46:2 Yunxiang Su, Kenny Ye Liang, and Shaoxu Song
!"#$%&'(
'#)
*+,'%#(
,#-.&$/
0#1.
2&3#
!
!"#
!
!"#
#
$!"#%
45&'#(6&7#)8
*#-.$+9)7 "
!
&
!
'
#
&
#
'
$
$
*:$$#-.8;33$#3&.9+-
!
&
()&
!
'
$()&%
$
$
!
$%&
#
&
$()&%
#
'
$()&%
#
&
#
'
$
$
;)<&=#-.
#
*
#
*
!
*
#
+
$()&%
#
+
$()&%
!
+
$()&%
!
# $ # % &
;%%82&3#78
>$&"#$7#)
!"#$%&&'(&)*+,-$,.$/01*+21($3)&(4 !5#$6+-)1$7(401*
?')&.#)8;33$#3&.9+-
!
*
()&
+
#
,
!
#
*
()&
+
!
,
!
#
,
!
!
,
!
+$
#
*
()&
#
))'
!
*
()&
!
))'
!8#$/+551($7(401*
%
&
%
-
%
.
%
/
!)#$9+:($;('+(4$4*,'(5$+-$/01*+21($3)&(4$
*+,'%#.#84#@
A-=+,'%#.#84#@
0:,B#$
>9,#
!"#$%&''#)
*+,'%#,#-.&$/
&
C&9%#)84#@
2+779B%#8>9,#8D&-3#7
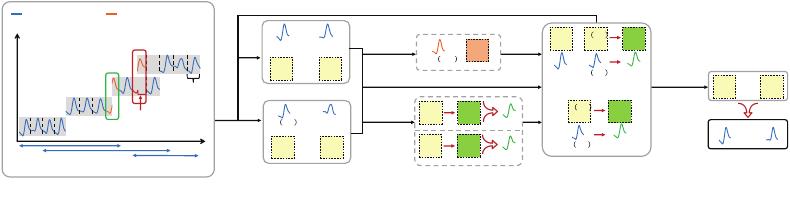
Fig. 1. The workflow of in-database K-Shape
handle such out-of-order arrivals, where data points are batched into les with possibly overlapped
time intervals on disk. Therefore, applying the existing K-Shape algorithm typically involves loading
all the data outside databases and sorting chronologically. Unfortunately, it is obviously inecient
in terms of I/O and incurs extra time.
On the other hand, time series clustering often needs to be performed multiple times over
dierent time ranges in IoT databases to discover various patterns across dierent time periods. For
instance, a forging machine in a steel processing factory may handle dierent types of steel bars
during various time periods, depending on the production orders. When processing each type of
steel bar, the machine may exhibit several working patterns inuenced by its operating conditions
and the environment. To identify all machine working patterns across dierent product types,
analysts need to cluster subsequences of time series data over various time intervals to achieve a
comprehensive clustering result. Apparently, loading all related data out of databases and clustering
from scratch each time is extremely time-consuming.
1.1 Challenges
Considering such IoT scenarios with time series databases, the challenges of in-database time series
clustering are as follows.
(1) Time series are often stored out-of-order in LSM-Tree databases owing to delayed arrivals,
while existing clustering methods require data in chronological order. It incurs extra pre-processing
time overheads to sort data chronologically. Therefore, we propose in-database adaptations for
existing clustering method K-Shape, which can handle the out-of-order issues in LSM-Tree.
(2) Clustering may need to be performed repeatedly with dierent time lters for dierent tasks.
K-Shape requires clustering from scratch each time, making it inecient. To support frequent
clustering queries, we propose in-database K-Shape with pre-computation.
(3) K-Shape is also inecient in handling long subsequences due its high complexity with respect
to the subsequence length. Therefore, we propose Medoid-Shape and in-database Medoid-Shape
for acceleration, by leveraging approximate clustering and avoiding time-consuming eigenvector
decomposition.
To tackle these challenges, the paper mainly focuses on how to eciently cluster time series in
databases by leveraging database properties. We primarily concentrate on achieving high eciency
for in-database time series clustering. The following example illustrates the challenges of LSM-Tree
based database storage.
Example 1. Figure 1(a) presents a time series stored in an LSM-Tree based time series database,
recording the solar radiation intensity in a wind farm, where the x-axis denotes time and the y-axis
denotes page number. Data points are batched into 4 pages
𝑃
1
, 𝑃
2
, 𝑃
3
, 𝑃
4
on disk, each denoted by a gray
rectangle. The higher the page number is, the later the data points arrive in the database. The dotted
Proc. ACM Manag. Data, Vol. 3, No. 1 (SIGMOD), Article 46. Publication date: February 2025.
of 26
100墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论