




论文 glaxybase.docx
10墨值下载
原生分布式图数据库
1
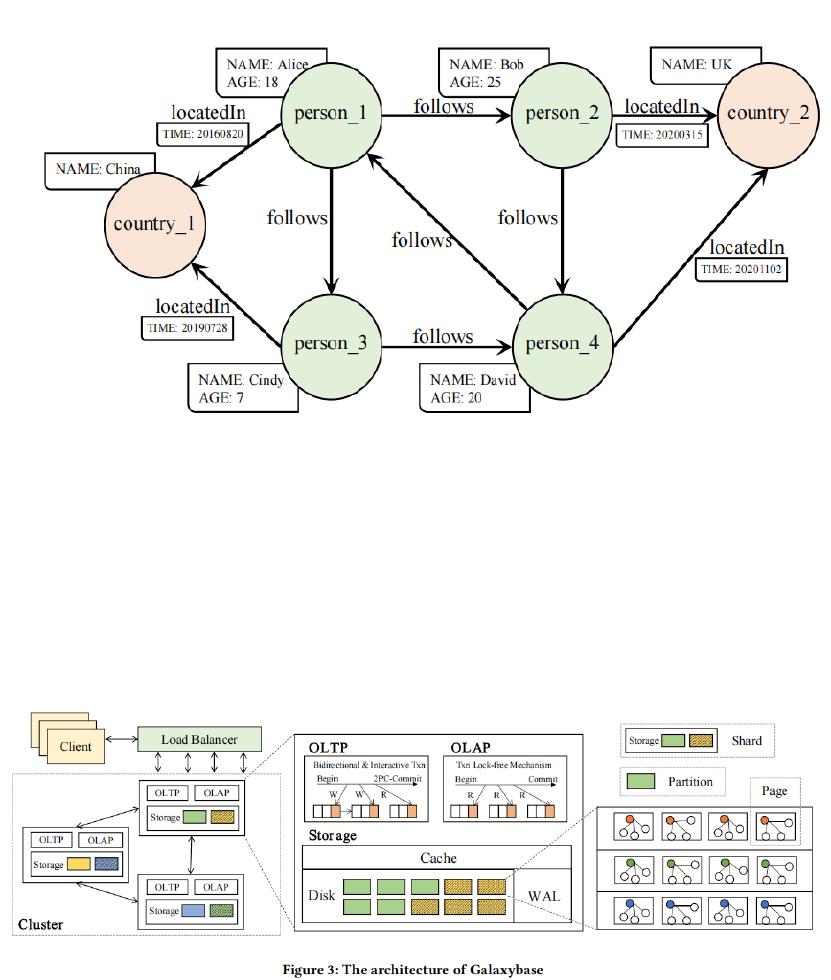
、属性图
属性图模型:点和边上可以处理各种属性。如上图所示,点和边分配了一个类型,例如
(点)、
(点)、
(边)、
(边)以及 一组属性,比 如
。
2
、
galaxybase
架构
原生分布式并行架构。存储模型分为三级:
、
!!
和
"
。
)和关系性分布式数据库类似,在关系型数据库(比如
#$
)中将一个表根据
分布键进行分片,从而将表数据分布在各个
%"$
数据节点上;
)这里以边切的方式切图,根据点的
&
进行分布,并将对应边存储在一起(这里指的
是放在同一个存储节点上)。将图根据点
&
分布在各个存储节点上,每个图的分
片在单个存储节点上形成一个
!!
,同样的
!!
内容在其他存储节点上构
成副本。他这里的
定义和其他地方不同,它将同一个存储节点上所有的
!!
包括副本构成一个
,而不是同一个
!!
和其他存储节点上的副本
构成一个
,这点需要注意
'
)每个
!!
中部署了日志结构邻接表用于存储点和边数据,实现无索引邻接,从
而方便图遍历和从磁盘上顺序读写。
(
)为了进一步优化边查询性能,
!!
中为每个点创建了一个
"#"
,将每个点
的所有邻边放到一个页中。
)
)
*
和关系型数据库中的一样,作为变更日志写到磁盘,系统崩溃重启时可以通过
*
进行恢复
3
、数据存储
#!!
中处理
"+%,-
(日志结构邻接表),将点和表作为邻接表,
并存储多版本数据,最后将数据批量写回磁盘;
#"
级别部署了
"#"
结构,在图遍
历和单边查询等基本操作中实现高性能。
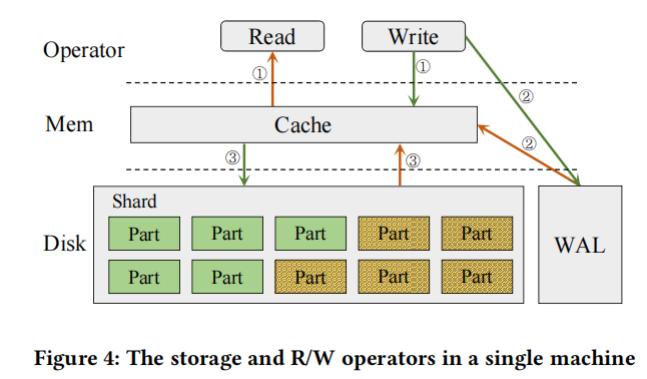
如上图所示,
"
对集群中每个服务构建了两层存储模式,内存中是
模块,以
及磁盘上的持久化模块。持久化模块包括
*
和数据。
写操作:绿色箭头展示了写流程,首先数据会写到
和
*
到磁盘:
提高了读写
效率,
*
确保数据一致性。当数据的
*
持久化到磁盘,并且数据更新到
后就认
为写完成了。当缓存中的数据满足驱逐标准时,异步、顺序、批量写到
的
!!
中
读操作:黄色线表示了读操作,首先从
中进行查找,如果数据都在
中就可以返
回,否则需要从磁盘上的
中加载检索,合并
中和读上来的数据。默认情况下,
*
中的数据会同步到
中
数据驱逐策略:内存的使用影响到了系统稳定性;利用
./
策略驱逐最近读的数据;
中更新的数据达到了阈值。
of 6
10墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论