




【2024VLDB】Combining Small Language Models and Large Language Models for Zero-Shot NL2SQL.pdf
免费下载

Combining Small Language Models and Large Language Models
for Zero-Shot NL2SQL
Ju Fan
Renmin University of
China
fanj@ruc.edu.cn
Zihui Gu
Renmin University of
China
guzh@ruc.edu.cn
Songyue Zhang
Renmin University of
China
zhangsongyue@ruc.edu.cn
Yuxin Zhang
Renmin University of
China
zhangyuxin159@ruc.edu.cn
Zui Chen
MIT CSAIL
chenz429@mit.edu
Lei Cao
University of Arizona/MIT
lcao@csail.mit.edu
Guoliang Li
Tsinghua University
liguoliang@tsinghua.edu.cn
Samuel Madden
MIT CSAIL
madden@csail.mit.edu
Xiaoyong Du
Renmin University of
China
duyong@ruc.edu.cn
Nan Tang
HKUST (Guangzhou) /
HKUST
nantang@hkust-gz.edu.cn
ABSTRACT
Zero-shot natural language to SQL (NL2SQL) aims to generalize pre-
trained NL2SQL models to new environments (e.g., new databases
and new linguistic phenomena) without any annotated NL2SQL
samples from these environments. Existing approaches either use
small language models (SLMs) like BART and T5, or prompt large
language models (LLMs). However, SLMs may struggle with com-
plex natural language reasoning, and LLMs may not precisely align
schemas to identify the correct columns or tables. In this paper, we
propose a ZNL2SQL framework, which divides NL2SQL into
smaller sub-tasks and utilizes both SLMs and LLMs. ZNL2SQL
rst ne-tunes SLMs for better generalizability in SQL structure
identication and schema alignment, producing an SQL sketch. It
then uses LLMs’s language reasoning capability to ll in the miss-
ing information in the SQL sketch. To support ZNL2SQL,we
propose novel database serialization and question-aware alignment
methods for eective sketch generation using SLMs. Additionally,
we devise a multi-level matching strategy to recommend the most
relevant values to LLMs, and select the optimal SQL query via an
execution-based strategy. Comprehensive experiments show that
ZNL2SQL achieves the best zero-shot NL2SQL performance
on benchmarks, i.e., outperforming the state-of-the-art SLM-based
methods by 5.5% to 16.4% and exceeding LLM-based methods by
10% to 20% on execution accuracy.
PVLDB Reference Format:
Ju Fan, Zihui Gu, Songyue Zhang, Yuxin Zhang, Zui Chen, Lei Cao,
Guoliang Li, Samuel Madden, Xiaoyong Du, and Nan Tang. Combining
Small Language Models and Large Language Models for Zero-Shot NL2SQL
. PVLDB, 17(11): 2750 - 2763, 2024.
doi:10.14778/3681954.3681960
⇤
Nan Tang is the corresponding author.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 11 ISSN 2150-8097.
doi:10.14778/3681954.3681960
PVLDB Artifact Availability:
The source co de, data, and/or other artifacts have been made available at
https://github.com/ruc-datalab/ZeroNL2SQL.
1 INTRODUCTION
Natural Language to SQL (NL2SQL), which translates a natural lan-
guage question into an SQL query, makes it easier for non-technical
users to access and analyze data, and thus can be useful for business
intelligence, data analytics, and other data-driven applications.
Figure 1 shows how (a) a natural language question
&
posed
over (b) a database ⇡ can be translated into (c) an SQL query (.
Zero-shot NL2SQL. A practical scenario for NL2SQL is that of-
tentimes, for new databases or applications, high-quality training
data (i.e., annotated NL2SQL samples) is time-consuming and labor-
intensive to acquire, and thus is not available. In this paper, we
refer to the case of zero annotated NL2SQL samples as zero-shot
NL2SQL. Thus, a natural question is: can we utilize existing anno-
tated NL2SQL samples, either from public benchmarks (e.g., Spi-
der [
48
]) or within enterprises, to train an NL2SQL model that is
generalizable to new test environments? An armative answer to
this question has the potential to dramatically reduce the expert
knowledge and human eorts for training data annotation.
However, the key obstacle to answer the question is that test
environments for NL2SQL may be very dierent from existing an-
notated datasets, which may include the following cases. (1) new
databases: an NL2SQL model trained on the Spider [
48
] bench-
mark may not perform well for domain-specic (e.g., academic or
nancial) databases [
16
,
28
]. (2) new linguistic phenomena: varying
linguistic phenomena (e.g., abbreviations, synonyms, etc.) in the
test environments may lead to dramatic performance declines for
existing NL2SQL models [4].
State of the Art: Strengths and Limitations. The state-of-the-
art (SOTA) solutions for NL2SQL mainly rely on pre-trained lan-
guage models, which fall into two categories: small language models
(SLMs) such as BART [
17
] and T5 [
32
], and large language models
(LLMs) such as GPT4 and PaLM [
7
]. We have conducted an in-depth
analysis to gain insights into strengths and limitations of the SOTA
2750
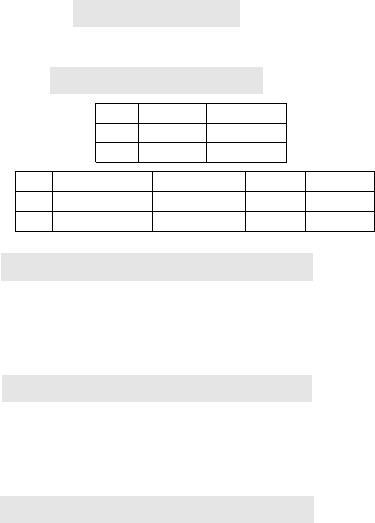
(a) A Text Question &
Which course has the highest score for the student named timothy ward?
(b) Snippets of a Database ⇡
Course id course teacher
001 math jordy wu
... ... ...
Student id given_name last_name score course
1 timmy ward 92 math
... ... ... ... ...
(c) The Ground-truth SQL Query ( w.r.t. &
SELECT course FROM Student
WHERE given_name = timmy AND last_name = ward
ORDER BY score LIMIT 1;
(d) An SQL query (
0
translated by an SLM
SELECT course FROM Student
WHERE given_name = ’timothy ward’
ORDER BY score LIMIT 1;
(e) An SQL query (
00
translated by an LLM
SELECT Course.course, Student.score
FROM Student JOIN Course ON Student.id = Course.id
WHERE given_name = ’timothy’ AND last_name = ward
ORDER BY score LIMIT 1;
Figure 1: A sample NL2SQL translation. The incorrect por-
tions are highlighted in red.
solutions for zero-shot NL2SQL, and report the error distributions
of both categories in Figure 2.
SLM-based methods, such as RASAT [
30
], PICARD [
37
], and
RESDSQL [
18
], have shown promise in generating accurate SQL
queries on NL2SQL datasets through ne-tuning on numerous an-
notated NL2SQL samples. However, SLM-based methods may have
limited generalizability in natural language reasoning in our zero-
shot settings, which may dramatically degrade the performance of
the methods [
28
]. Consider
(
0
in Figure 1(d), given “student named
timothy ward” in question
&
, an SLM-based method only selects
one column
given_name
that is similar to the word “named”. This is
because the annotated NL2SQL samples used to train the method do
not dierentiate between
given_name
and
last_name
. Although
further ne-tuning on new databases or linguistic phenomena can
alleviate this problem, it requires a signicant amount of high-
quality training data, such as annotated NL2SQL samples. Acquir-
ing such data can be both time-consuming and labor-intensive,
making it a challenging task.
LLMs like PaLM [
7
] and GPT4 [
25
], which are often accessed
through API calls, have demonstrated remarkable reasoning abil-
ities across a range of domains and tasks. Compared with SLMs,
LLMs are capable of (complicated) language reasoning, including
understanding question semantics, resolving ambiguities, and per-
forming logical deductions, which are necessary for generating SQL
queries in new environments. However, LLMs may not achieve pre-
cise schema alignment: as shown in Figure 2, 42% of the errors
are caused by incorrect table/column selection. In particular, LLMs
tend to choose more columns and tables to cover the input content,
leading to incorrect execution results. Consider
(
00
in Figure 1(e):
the LLM identies incorrect columns (
score
) and tables (
course
)
in SELECT and FROM clauses.
Our Proposal. We propose a decomposition-base d approach that
breaks down the NL2SQL task into smaller sub-tasks, such that
each sub-task is more amenable to solve in our zero-shot setting.
Naturally, the thought process of writing an SQL query can be
broken down into four sub-tasks:
(1)
Identifying query structure that consists of SQL reserved
keywords, e.g.,SELECT, FROM, WHERE, and ORDER BY;
(2)
Aligning relevant schema elements with the question, i.e.,
columns and tables in SELECT and FROM clauses;
(3)
Completing the SQL query by deducing conditions in
WHERE
clause, columns in ORDER BY or GROUP BY clauses, etc.
(4)
Iteratively correcting the SQL query if there are syntax or
execution errors.
By analyzing the behavior of SLMs and LLMs over many dier-
ent data sets, our key observation is that, contrary to the intuitive
observation that LLMs should outperform SLMs, we nd that the
two together complement each other and perform better than ei-
ther alone when performing the above four steps. Specically, a
task-specic ne-tuned SLM can better understand the database
schema and the SQL syntax, which enables it to excel in structure
identication and schema alignment. In contrast, existing research
reveals that LLMs often face an “hallucination” issue, generating
text unrelated to the given instructions, due to their lack of do-
main knowledge [
21
]. However, a general LLM possesses strong
language reasoning capabilities [
2
], making it well-suited for SQL
completion that require complex condition reasoning. Moreover,
LLM also exhibits excellent interaction capabilities, allowing it to
perform error correction eciently through appropriate feedback.
Based on the insight, we propose ZNL2SQL, a framework that
uses SLMs and LLMs to solve dierent steps in our decomposition-
based approach, combining the best of the two worlds to address
the generalization challenge of zero-shot NL2SQL. ZNL2SQL
consists of two key steps, as illustrated in Figure 3.
•
Step 1: SQL sketch generation utilizes SLMs for SQL structure
identication and schema alignment to generate an SQL sketch,
with attributes to SELECT, tables included in FROM, and necessary
keywords (e.g.,ORDER BY) for composing the SQL query.
•
Step 2: SQL query completion and correction leverages
LLMs to complete the missing information in the SQL sketch and
generate complete SQL queries, e.g., aligning with data values from
the database. For example, although the question refers to “timothy”,
the database actually uses the abbreviation “timmy”. Thus, “timmy”
should be used in the SQL query.
Challenges and Solutions. The rst challenge is how to de-
velop an SQL sketch generation method that can generalize to
new databases or linguistic phenomena. We introduce an encoder-
decoder based SLM model that generates an SQL sketch. Specically,
to improve the generalizability of the model, we design a novel data-
base serialization strategy to make the encoder more adaptive to
new databases. Moreover, we propose a question-aware aligner to
obtain the most relevant SQL sketches by inferring the semantics
2751
of 14
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论