




模糊测试中的位置自适应变异调度策略.pdf
100墨值下载

模糊测试中的位置自适应变异调度策略
杨 智
①
徐 航
*①
桑伟泉
①
孙浩东
①
金舒原
②
①
(信息工程大学密码工程学院 郑州 450004)
②
(中山大学计算机学院 广州 510275)
摘 要:种子自适应变异调度策略是基于变异的模糊测试中最新的技术,该技术能够根据种子的语法和语义特征
自适应地调整变异算子的概率分布,然而其存在两个问题:(1)无法根据变异位置自适应地调整概率分布;(2)使
用的汤普森采样算法在模糊测试场景中容易导致学习到的概率分布接近平均分布,进而导致变异调度策略失效。
针对上述问题,该文提出一种位置自适应变异调度策略,通过一种自定义的双层多臂老虎机模型为变异位置和变
异算子建立联系,并且采用置信区间上界算法选择变异算子,实现位置自适应的同时避免了出现平均分布的问
题。基于American Fuzzy Lop(AFL)实现了位置自适应的模糊测试器 (PAMSSAFL),实验结果表明位置自适应
的变异调度策略能明显提升模糊测试器的bug发现能力和覆盖能力。
关键词:漏洞挖掘;模糊测试;变异;覆盖率
中图分类号:TN915.08; TP393.08 文献标识码:A 文章编号:1009-5896(2024)09-3797-10
DOI: 10.11999/JEIT240060
Position-Adaptive Mutation Scheduling Strategy in Fuzzing
YANG Zhi
①
XU Hang
①
SANG Weiquan
①
SUN Haodong
①
JIN Shuyuan
②
①
(School of Cryptographic Engineering, Information Engineering University, Zhengzhou 450004, China)
②
(School of Computer Science and Engineering, Sun Yat-sen University, Guangzhou 510275, China)
Abstract: The seed-adaptive mutation scheduling strategy is the latest technology in mutation-based fuzzing,
which can adaptively adjust the probability distribution of the mutation operators according to the syntax and
semantic characteristics of the seed. However, it has two problems: (1) it is unable to adaptively adjust the
probability distribution according to the mutation position; (2) The Thompson Sampling algorithm used in the
fuzzing scenario is easy to lead to the learned probability distribution close to the average distribution, which
leads to the failure of the mutation scheduling strategy. Focusing on the above problems, a position-adaptive
mutation scheduling strategy is proposed. This technology establishes the relationship between the mutation
position and the mutation operators through a user-defined double-layer multi-armed bandit model, and uses
the Upper Confidence Bound algorithm to select the mutation operator, so as to achieve position adaptation
and avoid the problem of average distribution. The position-adaptive fuzzer Position-Adaptive Mutation
Scheduling Strategy AFL (PAMSSAFL) is implemented based on American Fuzzy Lop (AFL). The comparison
results show that the position-adaptive mutation scheduling strategy can improve the bug detection ability and
coverage ability of the fuzzer.
Key words: Vulnerability mining; Fuzzing; Mutation; Coverage
1 引言
基于变异的模糊测试通过在种子的不同位置应
用不同的变异算子生成大量的测试用例,然后将测试
用例输入到目标程序执行,其因简单高效而倍受从
业者青睐,当前主流的模糊测试器如AFL (American
Fuzzy Lop)
[1]
, Honggfuzz
[2]
和LibFuzzer
[3]
均采用变
异的方式生成测试用例。为了让生成的测试用例尽
可能多样化,基于变异的模糊测试器通常包括多种
变异算子,并且可能将任意一个变异算子应用在种
子的任意变异位置。变异调度是指每一次变异时变
异算子的选择,最新的变异调度策略是由Lee等人
[4]
提出的种子自适应的变异调度策略,该策略首先根
收稿日期:2024-01-26;改回日期:2024-07-13;网络出版:2024-08-02
*通信作者: 徐航 1174290091@qq.com
基金项目:国家自然科学基金(62176265)
Foundation Item: The National Natural Science Foundation of
China (62176265)
第46卷第9期 电 子 与 信 息 学 报 Vol. 46No. 9
2024年9月 Journal of Electronics & Information Technology Sept. 2024

据种子的语法和语义特征将种子聚类到最合适的种
子组,然后以种子组为单位利用汤普森采样算法
[5]
预估变异算子的期望值形成概率分布,因此变异算
子的概率分布是根据种子组发生变化的,但是其仍
存在如下两个问题:(1)在所有变异位置都利用相
同的概率分布选择变异算子,但实际上在不同变异
位置应用同一个变异算子的有效性不同,这导致可
能错过最有效的变异位置和变异算子的组合;(2)该
技术使用汤普森采样算法预估变异算子的期望值,
该算法需要将执行结果分为成功和失败两类,但定
制的分类标准在测试一部分程序时容易出现平均分
布进而导致变异调度策略失效。
考虑到同一个变异算子应用在种子不同变异位
置的有效性是不一样的,本文在种子自适应的变异
调度策略的基础上提出了一种位置自适应变异调度
策略。本文设计了一种双层多臂老虎机模型为变异
位置和变异算子建立联系,以此达到位置自适应的
目的,并采用置信区间上界算法
[6]
解决模糊测试场
景中的多臂老虎机问题,该强化学习算法仅需设置
成功的奖励值,避免了制定分类标准的问题。本文
基于AFL实现了位置自适应的模糊测试器PAMS-
SAFL(Position-Adaptive Mutation Scheduling
Strategy AFL),与AFL
[1]
、DARWIN
[7]
和Seam-
Fuzz
[4]
进行对比实验,结果表明位置自适应的变异
调度策略在bug发现能力和覆盖能力方面优于已有
的变异调度策略。
2 相关工作
基于变异的模糊测试器通常实现一个循环,在
单次循环内选择一个种子进行变异,生成大量的测
试用例输入到目标程序中执行,然后进入下一轮循
环。以AFL
[1]
为例,每一轮循环的变异部分可以分
为两个阶段:确定变异和随机变异。确定变异生成
的测试用例是固定的,所以仅当种子首次进入循环
时才采用确定变异。随机变异首先根据种子的长
度、执行速度等特征计算出需要生成的测试用例数
量,然后对于每个待生成的测试用例,随机选择变
异堆叠次数(应用变异算子的次数),每次堆叠时在
随机位置应用随机的变异算子。此外,在一轮循环
中没有覆盖任何新路径时,便会启动拼接,拼接指
组合一个种子的前半段和另一个种子的后半段形成
新的种子,拼接产生的新种子会重新进行随机变异。
在基于变异的模糊测试器中,确定变异不具有随机
性,因此提供了禁用该功能的参数选项,拼接则在
特定情况下启用,所以随机变异是最主要的测试用
例生成手段,并且随机变异的可拓展性很强,故现
有模糊测试器都将精力集中在随机变异阶段
[4,7]
。
随机变异阶段包含一组预定义的变异算子,可以分
为5种类型,如表1所示。
变异算子的选择即变异调度,按照变异调度策
略可以将基于变异的模糊测试器分为3类:程序无
感知的模糊测试器、程序自适应的模糊测试器、种
子自适应的模糊测试器。程序无感知的模糊测试器,
如AFL
[1]
,测试任何目标程序时都随机选择变异算
子,所以变异算子的概率分布永远为平均分布,沿
用AFL原有变异调度策略的模糊测试器
[8–10]
均为程
序无感知的。Lü等人
[11]
通过实验证明在测试相同
程序时,各个变异算子的有效性不同,并且在测试
不同程序时,相同变异算子的有效性也不同,因此
设计了一款程序自适应的模糊测试器MOPT-AFL,
该模糊测试器利用定制的粒子群优化算法动态计算
变异算子的最优概率分布,但是其包含多个参数,
调整参数使模糊测试器的性能达到最优需要丰厚的
专家知识;DARWIN
[7]
利用进化算法系统地优化变
异算子的概率分布,相较于MOPT-AFL,其采用
的算法复杂度低,并且不需要用户手动配置参数,
对用户更加友好;HavocMAB
[12]
将变异算子分为两
大类(块操作、单元操作),并利用强化学习方法学
习最优的操作类别,但其对变异算子的分类粒度过
粗。以上3款模糊测试器选择变异算子的概率分布
都能根据目标程序动态调整,但是没有考虑将变异
算子应用至不同种子的有效性。
种子自适应变异调度策略
[4]
是基于变异的模糊
测试中最新的技术,其选择变异算子的概率分布随
着种子发生变化,整体流程如图1所示,与传统的
技术相比包含两个独特部分:种子聚类和自适应变
异调度。
(1) 种子聚类:考虑到同一个变异算子应用至
不同种子的有效性是不一样的,但是每次测试时保
存下来的种子有成百上千个,因此为每个种子单独
学习变异算子概率分布将会消耗大量资源,此外,
每个种子被选择的次数很少,这导致很难快速学习
到收敛的概率分布,并且已学习到的概率分布难以
被应用。为了解决上述问题,现有方法
[4]
将行为和
表 1 变异算子类型
类型 释义
Flip(k) 翻转第k个比特,0翻转为1,1翻转为0
Overwrite(s, e, v) 将第s个字节至第e个字节的内容复写为v
Arithmetic(s, e, v)
将第s个字节至第e个字节的内容与
v进行算术运算
Delete(s, l) 从第s个字节开始删除长度l的内容
Insert(s, v) 在第s个字节之后插入v
3798 电 子 与 信 息 学 报 第 46 卷
内容相似的种子聚合到相同的组中,并且以组为单
位学习概率分布。
(2) 自适应变异调度:具体包括更新和应用阶
段。确定种子所属组后,在应用阶段,按照该组已
学习到的概率分布选择变异算子应用至种子,新建
立的种子组由于还未学习到任何可用的信息,所以
随机选择或按顺序选择变异算子。在更新阶段,采
用既定的学习算法,结合本次选择的变异算子和执
行结果更新对应种子组的变异算子概率分布。上述
两个阶段交替进行不断更新变异算子的概率分布。
3 本文方案
3.1 双层多臂老虎机
种子自适应的模糊测试器并未考虑到相同变异
算子应用至种子的不同变异位置的有效性也有差
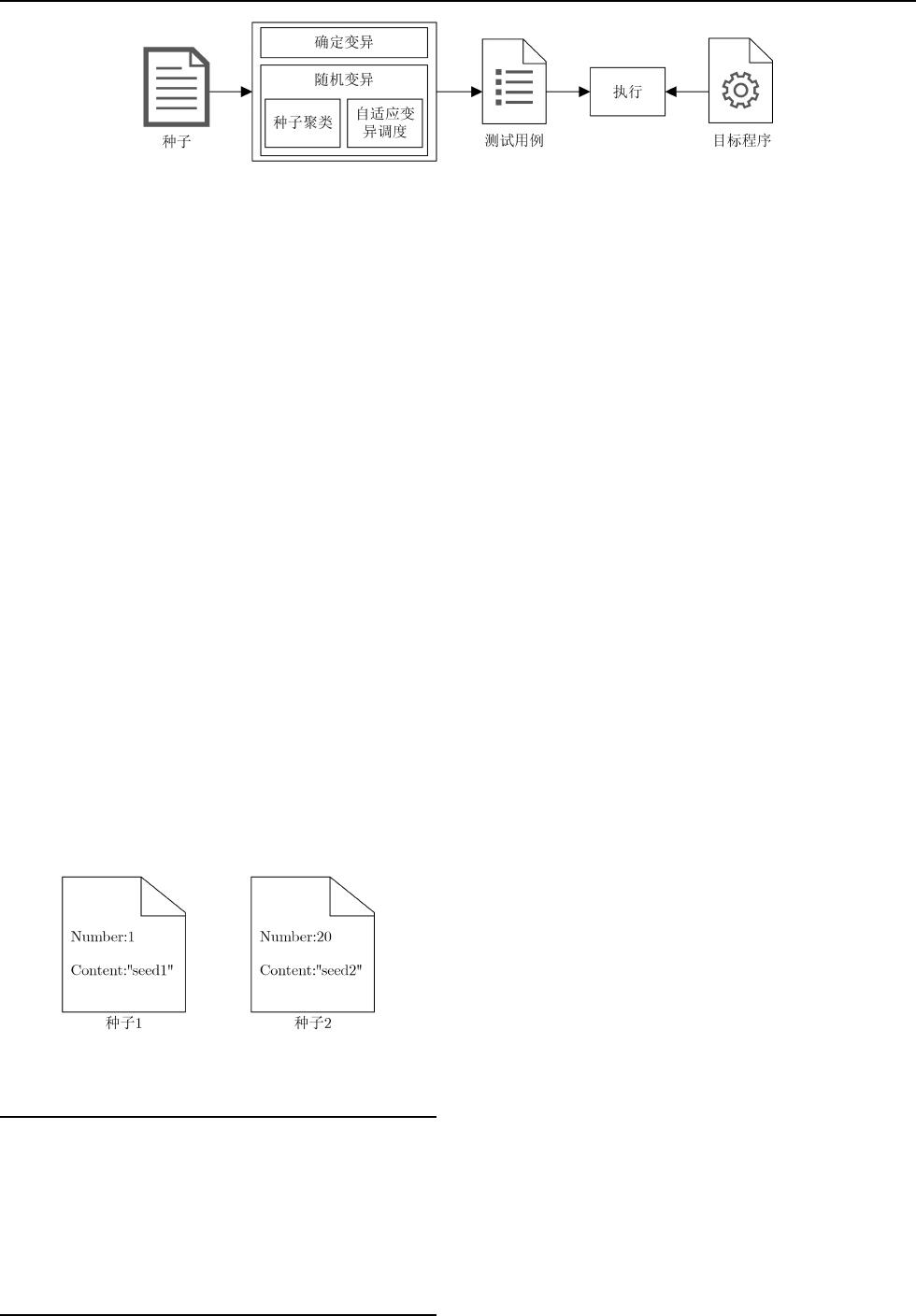
别。图2显示两个不同的种子,在表2的示例代码段
中,number和content是从种子的不同位置读取到
的信息,要想执行函数bug1,应将种子1的Num-
ber加上9,或者将种子2的Number减去10,说明对
于不同种子,有效的变异算子不同;要想执行函数
bug2,应在种子1的Content中插入一段内容使其
长度大于8,说明对于同一个种子的不同变异位置,
有效的变异算子也不同。出于对以上示例的思考,
本文希望对于不同的变异位置,能够选择出最有效
的变异算子。理想的方案是为种子的每一个变异位
置都学习变异算子的期望值,但一次测试中通常产
生成百上千个种子并且每个种子有成百上千个变异
位置,所以为每个种子的每个位置学习所消耗的资
源巨大,为了避免上述问题,本文采取如下方案:
(1)考虑到变异的局部性会导致一些种子的内容相
似,对这部分种子,不需要为相同位置重复学习,
所以沿用了种子自适应的模糊测试器中的种子聚类
策略,将相似的种子聚合到一个种子组中;(2)又
考虑到在一个种子的连续变异位置最有效的变异算
子可能是相同的,如表2中的示例,在Content
的任意位置插入一段内容都能让长度大于8,所以
将每个种子平均划分为m个变异区域(最后一个区
域可能略长或略短),以变异区域为基本单位学习
变异算子的期望值;(3)由于在不同种子的相同变
异区域进行变异的有效性不同,所以本文为每个种
子组学习变异区域的期望值,每次选择出期望值最
高的变异区域,然后在该变异区域内随机确定最终
的变异位置。
在确定上述目标后,本文明确所面临的问题是
在m个变异区域r中选择出对于当前种子组最有效
的一个r
i
,然后在n个变异算子o中选择出对于当前
变异区域r
i
最有效的一个o
j
,将变异算子o
j
应用在
r
i
中的一个随机位置p,在堆叠t次变异后生成最终
的测试用例,将测试用例喂入目标程序中执行后评
估本轮选择的回报值,整体目标是在有限时间内最
大化总回报值,这是一个多臂老虎机问题。多臂老
虎机本质上是探索和利用的平衡问题,在模糊测试
的场景中,老虎机的每个操作臂代表着变异区域或
者变异算子,在测试初始阶段并不知道任何一个操
作臂的期望值,因此尝试去选择一个操作臂,并根
据执行结果更新期望值,随着选择次数的增多,将
获得更加准确的期望值,这是探索的过程;当知道
了所有操作臂的期望值后,按照预定的策略选择出
一个操作臂,这是利用的过程。
最终本文为每个种子组设计了一个双层多臂老
虎机模型,第1层为变异区域选择层,第2层为变异
算子选择层,第1层中的每个变异区域都对应第2层
图 1 种子自适应变异调度策略流程
图 2 示例种子
表 2 示例代码段
1. function example() {
2. number = getNumber();
3. if(number == 10) bug1();
4. content = getContent();
5. length = strlen(content);
6. if(length > 8) bug2();
7. }
第9期 杨 智等:模糊测试中的位置自适应变异调度策略 3799
of 10
100墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
Brite
最新上传
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
7
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

相关文档
评论