




Timer Generative Pre-trained Transformers Are Large Time Series Models.pdf
100墨值下载
Timer: Generative Pre-trained Transformers Are Large Time Series Models
Yong Liu
* 1
Haoran Zhang
* 1
Chenyu Li
* 1
Xiangdong Huang
1
Jianmin Wang
1
Mingsheng Long
1
Abstract
Deep learning has contributed remarkably to the
advancement of time series analysis. Still, deep
models can encounter performance bottlenecks
in real-world data-scarce scenarios, which can be
concealed due to the performance saturation with
small models on current benchmarks. Meanwhile,
large models have demonstrated great powers in
these scenarios through large-scale pre-training.
Continuous progress has been achieved with the
emergence of large language models, exhibiting
unprecedented abilities such as few-shot general-
ization, scalability, and task generality, which are
however absent in small deep models. To change
the status quo of training scenario-specific small
models from scratch, this paper aims at the early
development of large time series models (LTSM).
During pre-training, we curate large-scale datasets
with up to 1 billion time points, unify heteroge-
neous time series into single-series sequence (S3)
format, and develop the GPT-style architecture to-
ward LTSMs. To meet diverse application needs,
we convert forecasting, imputation, and anomaly
detection of time series into a unified generative
task. The outcome of this study is a Time Se-
ries Transformer (Timer), which is generative pre-
trained by next token prediction and adapted to
various downstream tasks with promising capabil-
ities as an LTSM. Code and datasets are available
at: https://github.com/thuml/Large-Time-Series-
Model.
1. Introduction
Time series analysis encompasses a broad range of critical
tasks, including time series forecasting (Box et al., 2015),
*
Equal contribution
1
School of Software, BNRist, Tsinghua
University. Yong Liu
<
liuyong21@mails.tsinghua.edu.cn
>
.
Haoran Zhang
<
z-hr20@mails.tsinghua.edu.cn
>
. Chenyu Li
<
lichenyu20@mails.tsinghua.edu.cn
>
. Correspondence to: Ming-
sheng Long <mingsheng@tsinghua.edu.cn>.
Proceedings of the
41
st
International Conference on Machine
Learning, Vienna, Austria. PMLR 235, 2024. Copyright 2024 by
the author(s).
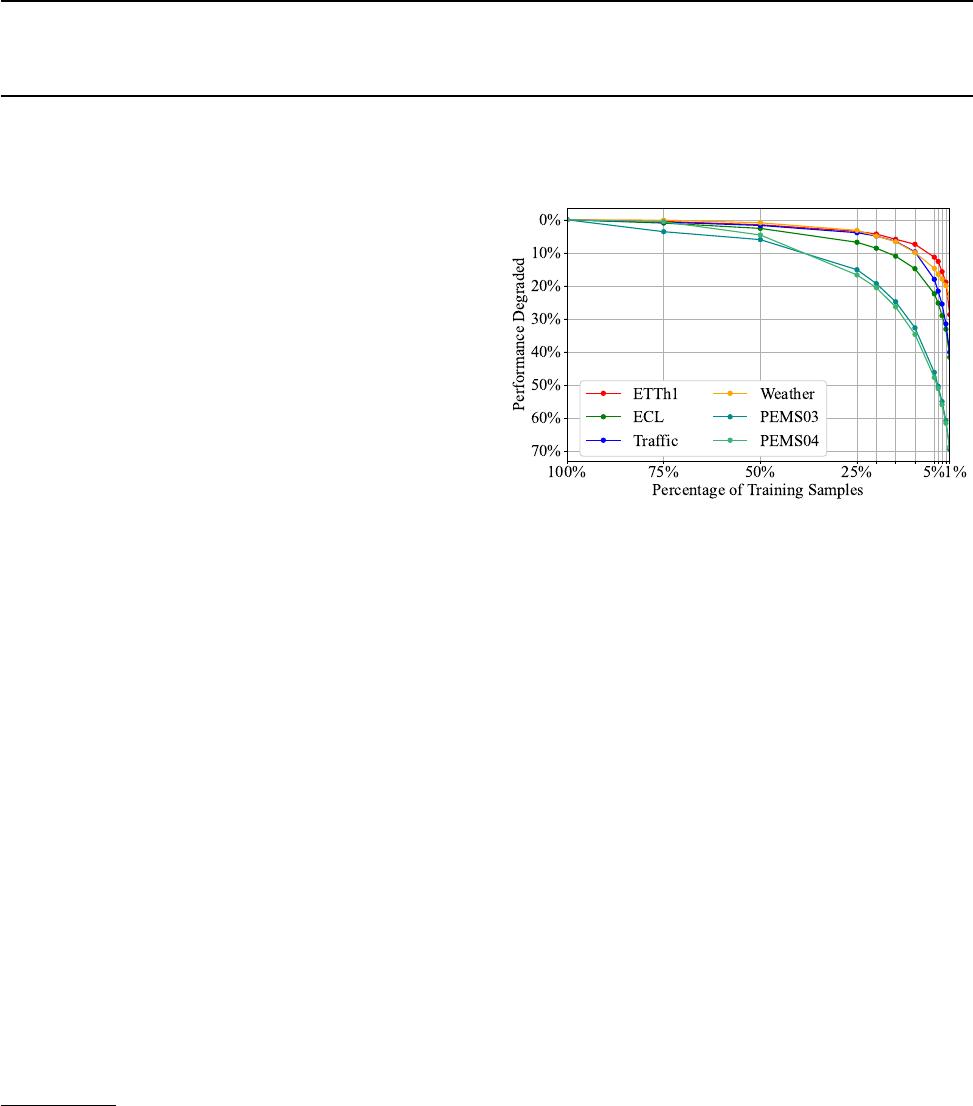
Figure 1.
Performance of PatchTST (2022) on different data scarci-
ties. The degradation is reported as the relative increase in MSE
compared with training on full samples.
imputation (Friedman, 1962), anomaly detection (Breunig
et al., 2000), etc. Despite the ubiquity of real-world time se-
ries, training samples can be scarce in specific applications.
While remarkable advances have been made in deep time
series models (Wu et al., 2022; Zeng et al., 2023; Liu et al.,
2023b), the accuracy of state-of-the-art deep models (Nie
et al., 2022) can still deteriorate drastically in such scenar-
ios, even within prevalent benchmarks as shown in Figure 1.
Concurrently, we are witnessing rapid progress of large lan-
guage models (Radford et al., 2018), involving training on
large-scale text corpora and exhibiting remarkable few-shot
and zero-shot capabilities (Radford et al., 2019). It can be
indicative for the community to develop large time series
models (LTSM) that are transferable on various data-scarce
scenarios by pre-training on numerous time series data.
Further, large models evolved by generative pre-training
(GPT) have demonstrated several advanced capabilities that
are absent in small models: the generalization ability that
one model fits many domains, the versatility that one model
copes with various scenarios and tasks, and the scalability
that performance improves with the scale of parameters and
pre-training corpora. Fascinating capabilities have fostered
the advancement of artificial general intelligence (OpenAI,
2023). Time series holds comparable practical value to nat-
ural language. Essentially, they exhibit inherent similarities
in generative modeling (Bengio et al., 2000) and autoregres-
sion (Box, 2013). Consequently, the unprecedented success
of the generative pre-trained large language models (Zhao
et al., 2023) serves as a blueprint for the progress of LTSMs.
1

Timer: Generative Pre-trained Transformers Are Large Time Series Models
Although unsupervised pre-training on time series data has
been widely explored, yielding breakthroughs based on the
masked modeling (Zerveas et al., 2021) and contrastive
learning (Woo et al., 2022), there are still unsolved funda-
mental issues for developing LTSMs. Firstly, the dataset
infrastructure and unified treatment for heterogeneous time
series are lagging behind other fields. As a result, prior unsu-
pervised pre-training methods are typically constrained to a
small scale and primarily focus on in-dataset transfer (Zhang
et al., 2022; Nie et al., 2022). Secondly, the architecture of
scalable large models remains underexplored in the field of
time series. It is observed that non-autoregressive structures,
which are prevalent and effective in small time series models,
may not be suitable for LTSMs. Thirdly, existing large-scale
pre-trained models (Woo et al., 2023; Das et al., 2023b) pri-
marily concentrated on a single task (e.g., forecasting), and
have scarcely addressed task unification. Consequently, the
applicability of LTSMs remains elevatable.
In this paper, we dive into the pre-training and adaptation of
large time series models. By aggregating publicly available
time series datasets and following curated data processing,
we construct Unified Time Series Dataset (UTSD) of hierar-
chical capacities to facilitate the research on the scalability
of LTSMs. To pre-train large models on heterogeneous time
series data, we propose the single-series sequence (S3) for-
mat that converts multivariate series with reserved patterns
into unified token sequences. For better generalization and
versatility, we adopt the GPT-style objective that predicts
the next token (Bengio et al., 2000). Eventually, we present
Timer, a large-scale pre-trained Time Series Transformer.
Unlike prevalent encoder-only architecture (Nie et al., 2022;
Wu et al., 2022; Das et al., 2023a), Timer exhibits similar
characteristics as large language models such as flexible con-
text length and autoregressive generation. It also presents
notable few-shot generalization, scalability, and task gen-
erality, outperforming state-of-the-art task-specific models
on forecasting, imputation, and anomaly detection. Overall,
our contributions can be summarized as follows:
•
We delve into the LTSM development by curating large-
scale datasets comprised of 1B time points, proposing
a unified sequence format to cope with data hetero-
geneity, and presenting Timer, a generative pre-trained
Transformer for general time series analysis.
•
We apply Timer on various tasks, which is realized in
our unified generative approach. Timer exhibits notable
feasibility and generalization in each task, achieving
state-of-the-art performance with few samples.
•
By pre-training on increasing available time series data,
Timer exhibits zero-shot forecasting capability. Quanti-
tative evaluations and quality assessments are provided
among concurrent large time series models.
2. Related Work
2.1. Unsupervised Pre-training on Sequences
Unsupervised pre-training on large-scale data is the essen-
tial step for modality understanding for downstream applica-
tions, which has achieved substantial success in sequences,
covering natural language (Radford et al., 2021), patch-
level image (Bao et al., 2021) and video (Yan et al., 2021).
Supported by powerful backbones (Vaswani et al., 2017)
for sequential modeling, the paradigms of unsupervised
pre-training on sequences have been extensively studied in
recent years, which can be categorized into the masked mod-
eling (Devlin et al., 2018), contrastive learning (Chen et al.,
2020), and generative pre-training (Radford et al., 2018).
Inspired by significant progress achieved in relevant fields,
masked modeling and contrastive learning have been well-
developed for time series. TST (Zerveas et al., 2021) and
PatchTST (Nie et al., 2022) adopt the BERT-style masked
pre-training to reconstruct several time points and patches
respectively. LaST (Wang et al., 2022b) proposes to learn
the representations of decomposed time series based on
variational inference. Contrastive learning is also well incor-
porated in prior works (Woo et al., 2022; Yue et al., 2022).
TF-C (Zhang et al., 2022) constrains the time-frequency con-
sistency by temporal variations and frequency spectrums.
SimMTM (Dong et al., 2023) combines masked modeling
and contrastive approach within the neighbors of time series.
However, generative pre-training has received relatively less
attention in the field of time series despite its prevalence
witnessed in developing large language models (Touvron
et al., 2023; OpenAI, 2023). Most large language models are
generative pre-trained (Zhao et al., 2023) with token-level
supervision, where each token is generated based on the pre-
vious context and independently supervised (Bengio et al.,
2000). Consequently, they are not constrained by specific
input and output lengths and excel at multi-step generation.
Furthermore, prior studies (Wang et al., 2022a; Dai et al.,
2022) have demonstrated that scalability and generalization
largely stem from generative pre-training, which requires
more training data than other pre-training paradigms. Thus,
our work aims to investigate and revitalize generative pre-
training towards LTSMs, facilitated by extensive time series
and deftly designed adaptation on downstream tasks.
2.2. Large Time Series Models
Pre-trained models with scalability can evolve to large foun-
dation models (Bommasani et al., 2021), featured by increas-
ing model capacity and pre-training scale to solve various
data and tasks. Large language models even demonstrate
advanced capabilities such as in-context learning and emer-
gent abilities (Wei et al., 2022). As of present, research on
large time series models remains at a nascent stage. Ex-
2
of 31
100墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论