




巨杉学习笔记 SequoiaDB MySQL导入导出工具使用实战.pdf
50墨值下载
巨杉学习笔记 SequoiaDB MySQL 导入导出工具使用实战
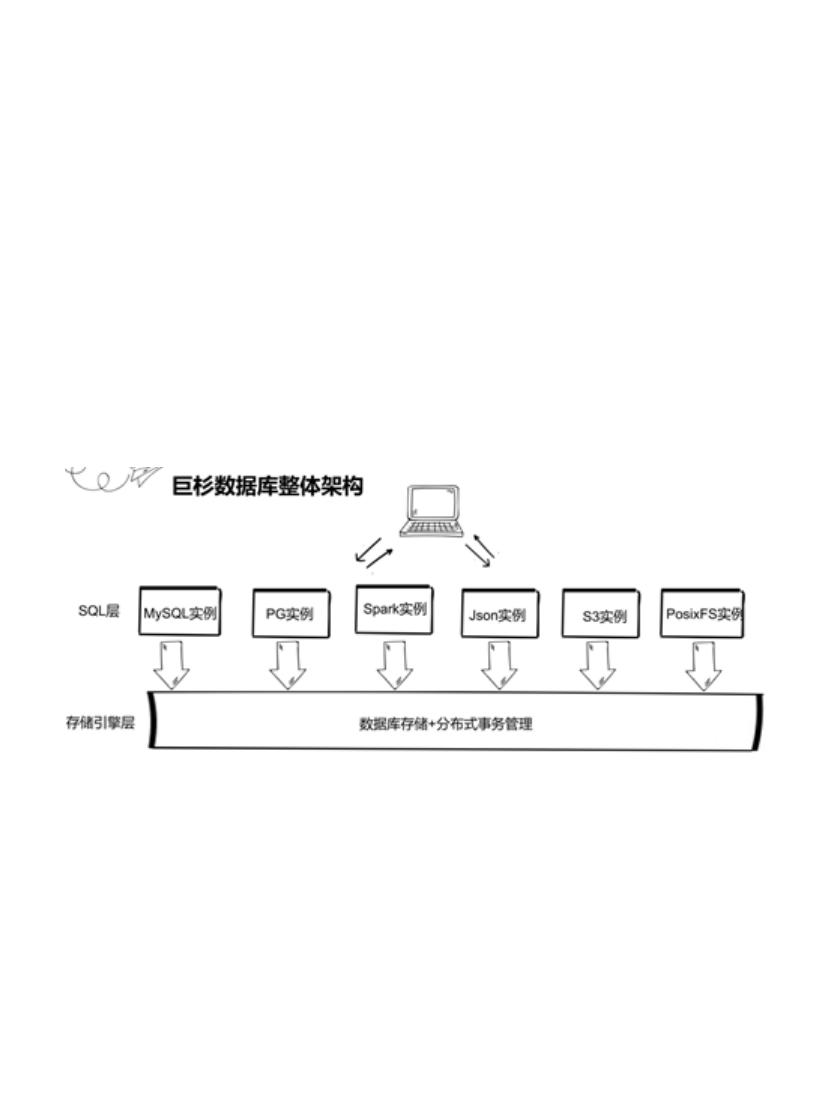
巨杉数据库架构简介
巨杉数据库作为分布式数据库是计算和存储分离架构,由数据库实例层和存储引擎层组成
的。存储引擎层负责数据库核心功能比如数据读写存储以及分布式事务管理。数据库实例层
也就是这里的的 SQL 层负责把应用 SQL 请求处理后发存储引擎层处理,并且把存储引擎层
响应结果反馈给应用层。支持结构化实例比如 MySQL 实例/PG 实例/spark 实例,也支持非结
构化实例比如 Json 实例,S3 对象存储实例/PosixFs 实例等等。这种架构支持的实例类型
比较多,方便从传统数据库无缝迁移到巨杉数据库,减小了开发学习成本,之前也跟数据库
圈同行交流,他们对架构也是十分认可。
这里的 SQL 层采用的是 MySQL 实例,存储引擎层是有三个数据节点和协调节点编目节点组
成。其中数据节点就是用来存储数据的,协调节点不存储数据,是用来把 MySQL 的请求进
行路由分发到数据库节点。编目节点用来存储集群的系统信息比如用户信息/分区信息等等。
这里用一个容器来模拟一个物理机或云虚拟机,这里设置的是 MySQL 实例在一个容器里,
编目和节点和协调节点放在了一个容器,三个数据节点分别放在一个容器,三个数据节点构
成了三个数据组,每个数据组三个副本。Web 应用的海量数据是通过分片切分的方式分散给
不同的数据节点,像这里的数据 ABC 通过分片打散到三台机器。
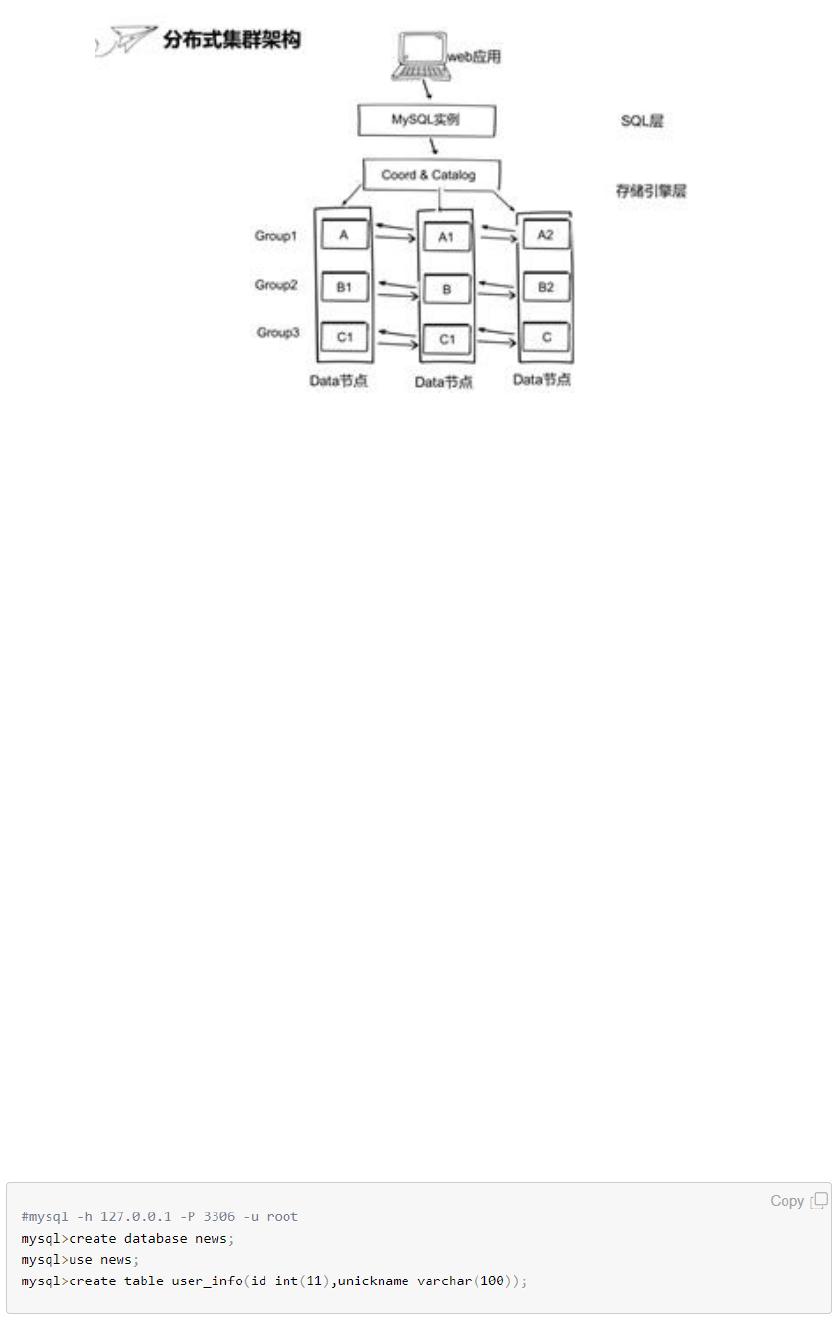
这里的数据分片是通过分布式 Hash 算法 DHT 机制实现,DHT 是 distribute Hashing table 缩
写。当写入数据时,首先通过 MySQL 实例把记录下发到协调节点,协调节点会通过分布式
Hash 算法根据每条记录的分区键进行散列,散列完之后协调节点根据分区键判断到底发送
到哪一个分区,所以每个分区之间的数据是完全隔离互相独立的。采用这种方法,我们就可
以把一个很大的表拆散到下面不同的子分区里面小表,实现数据拆分。
mysqldump 和 mydumper/myloader 导入导出工具实战
SequoiaDB 实现了对 MySQL 的完整兼容,那么有的用户会问了:
“既然是完整兼容,MySQL 相关的工具是否能使用?”
“数据从 MySQL 迁移到 SequoiaDB 如何操作?”
下面我们就介绍 SequoiaDB 如何使用 mysqldump 和 mydumper/myloader 进行数据的导入
导出。
1. mysqldump
1)通过存储过程制造测试数据
of 6
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论