




如何利用工具优化特别慢的SQL
5墨值下载
如何利用工具优化特别慢的 SQL?
Tosska 公司的 SQL 优化产品,能自动产生等价 SQL, 然后做性能基准测试,让
用户选择当前数据库软件和硬件环境下最优的等价 SQL。
SQL 优化专家版下载:
https://www.tosska.cn/tosska-sql-tuning-expert-tse-oracle-free-download-zh/
SQL 优化大师版下载:
https://www.tosska.cn/tosska-sql-tuning-expert-pro-tse-pro-for-oracle-download-
free-trial-zh/
当用户输入需要优化的 SQL 后,点击“优化 SQL”按钮,在弹出的“测试运行
所有 SQL 选项”窗口中,点击“确认”按钮开始自动优化过程。
如果原始 SQL 执行时间小于 1 分钟,那么在弹出的“测试运行所有 SQL 选项”
窗口中, 不用修改默认的性能基准测试选项,就能很快得到最优的替代 SQL。
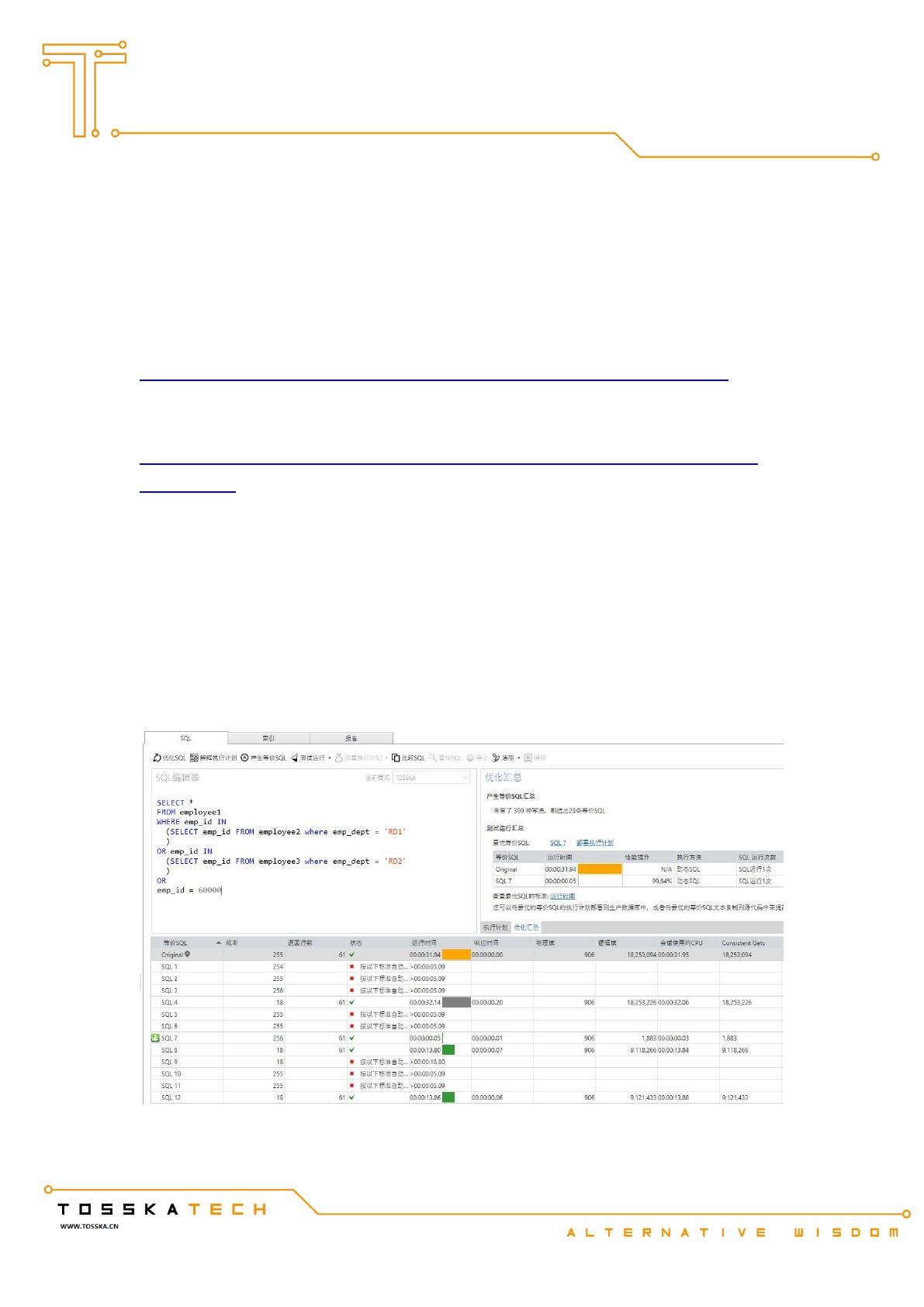
如下图,不到 5 分钟,优化过程就完成了。
原 SQL (执行时间 31.94 秒,逻辑读 18253094)
最优 SQL 7 (执行时间:0.05 秒,逻辑读 1883)

如果原始 SQL 执行时间很长(例如 3 分钟,或者 30 分钟也没跑完),优化过程
可能会很耗时。有没有什么加快优化过程的技巧呢?
让我们构造 1 个例子来说明如何做。
第一步,创建 4 个表
create table tu as select * from dba_objects;
create table tv as select * from dba_objects;
create table tw as select * from dba_objects;
create table tt as select * from dba_objects;
第二步,收集统计资料
exec dbms_stats.gather_table_stats(
ownname=>'TOSSKA',
tabname=>'TU',
estimate_percent=>dbms_stats.auto_sample_size);
exec dbms_stats.gather_table_stats(
ownname=>'TOSSKA',
tabname=>'TV',
estimate_percent=>dbms_stats.auto_sample_size);
exec dbms_stats.gather_table_stats(
ownname=>'TOSSKA',
tabname=>'TW',
estimate_percent=>dbms_stats.auto_sample_size);
exec dbms_stats.gather_table_stats(
ownname=>'TOSSKA',
tabname=>'TT',
estimate_percent=>dbms_stats.auto_sample_size);
第三步,准备原始 SQL (我在 SQL*Plus 中测试过,3 分钟没跑完,于是杀掉了)
SELECT /*+ use_hash(w u v t) */ COUNT(*)
FROM tv v,
tu u,
tw w,
tt t
of 9
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论