

4


1

Oracle DBA关键技能 备份与恢复最佳实践
免费下载
资源由 www.eimhe.com 美河学习在线收集分享
Oracle DBA 关键技能 备份与恢复最佳实践
第一部分:手工备份与恢复
第一章:备份恢复概述
一)数据库故障类型:
1)user process failure: pmon 自动处理
2)instance failure: smon 自动处理
3)user errors : 需要 dba 通过备份恢复或闪回技术解决
4)media failure:只能通过备份和日志恢复
二)备份和恢复计划
1)根据生产环境的恢复周期,制定详细的备份计划,然后严格执行
2)对备份,要在一定的时间内利用测试环境,进行故障恢复的练习
三)备份恢复分类
1)逻辑备份与恢复-- 面向 object
①传统的导入导出:exp/imp:
②数据泵导入导出:expdp/impdp
逻辑备份就是热备数据库对象某一时刻状态,不能运用在 media failure 上,逻辑备份的恢复就是还原备份,没有 recover 的概念。
2)物理备份与恢复-- 面向 media failure
①手工备份与恢复,也叫用户管理的备份与恢复(UMAN),通过 OS 的命令,完成备份与还原,然后再运用日志进行恢复。
②自动备份与恢复,利用 oracle 的备份恢复工具 RMAN,使还原与恢复过程自动完成,可以备份恢复 ASM FILE。
物理备份从方式上可以有一致性备份(冷备)和非一致性备份(热备)
完整的备份策略应该以物理备份为主,逻辑备份为辅(用于备份一些重要的表)
3)闪回技术-- 面向人为的逻辑错误
不需要利用备份。一种利用 undo 数据或闪回日志的快速恢复技术。可以针对不同层面问题进行逻辑恢复,11g 支持七种 flashback
方式。
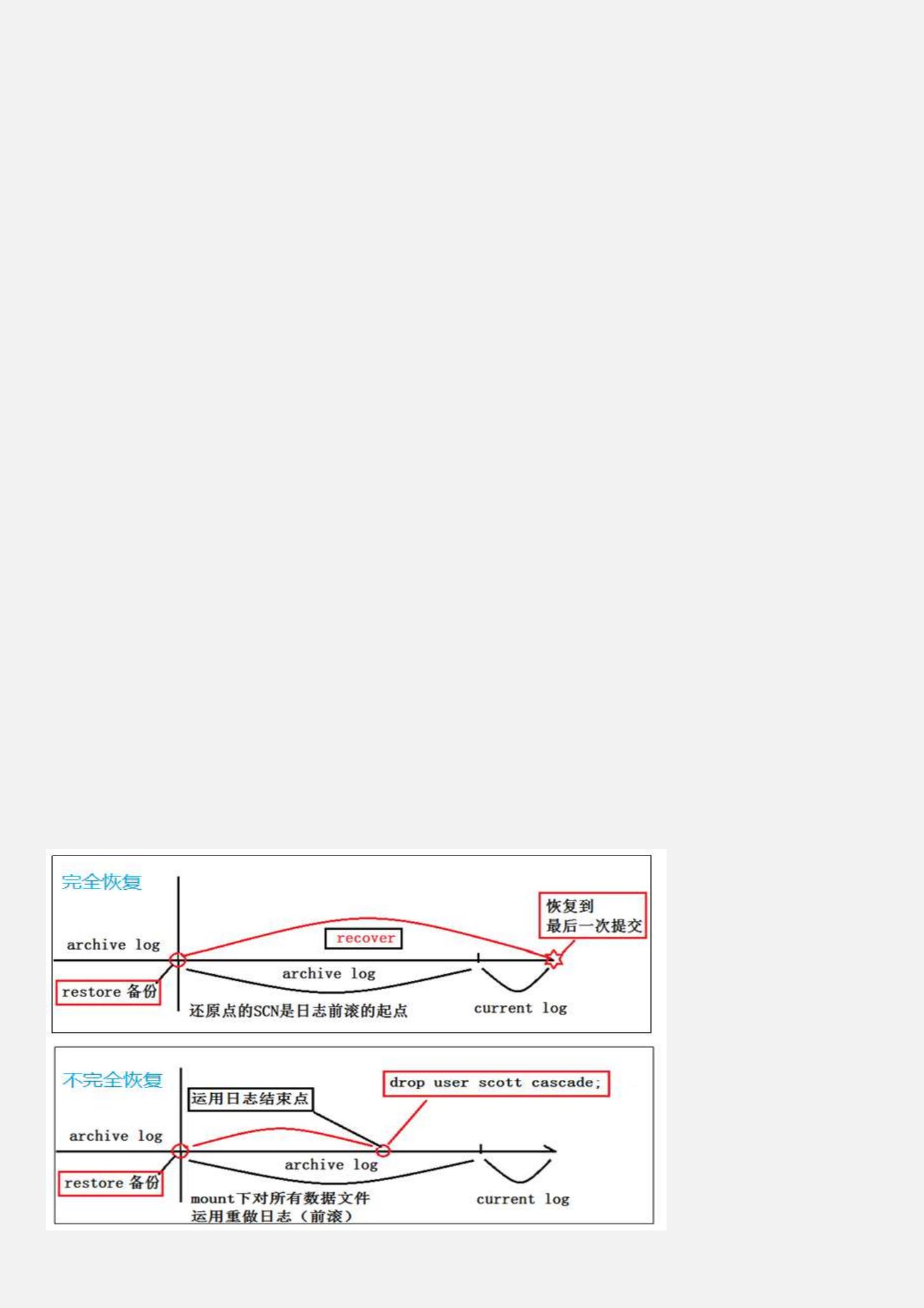
四)完全恢复与不完全恢复
media failure 后,需要运用日志进行 recover。
1)完全恢复:
利用完整备份或部分备份,可以将 datafile 恢复到 failure 前得最后一次 commit,不会出现数据丢失。
2)不完全恢复
需要运用完整备份和日志将 database 恢复到过去的某个时间点(或 SCN),有数据丢失。
五)归档与非归档

资源由 www.eimhe.com 美河学习在线收集分享
1)归档模式:redo log 写入 archive log
2)非归档模式:没有 archive log, redo log file 循环覆盖
当处于非归档模式下时,在丢失数据文件后唯一的选择是执行完整的数据库还原,而不能进行 recover。
第二章:手工备份与恢复
一)相关命令
1)备份和还原都使用 OS 命令(数据库是文件系统),如 linux 中的 cp
2)恢复用 sqlplus 命令:recover
二)备份前进行检查:
1)检查需要备份的数据文件
SQL> select name from v$datafile;
SQL> select file_id,file_name,tablespace_name from dba_data_files;
2)检查要备份的控制文件
SQL> select name from v$controlfile;
3)在线 redo 日志可以不做备份
三)dbv 检查坏块
在手工备份前,应该检查 datafile 是否有坏块,备份完后对备份也要做检查。
对某个 datafile 做坏块检查
$ dbv file=/u01/oradata/prod/users01.dbf feedback=50
DBVERIFY - 开始验证: FILE = /u01/oradata/prod/users01.dbf
.......
四)冷备的注意事项:
1)必须干净的关闭数据库,以保证数据一致性。
SQL>shutdwon immediate;
2)在 OS 下必须备份所有数据文件(完整备份)
3)在 OS 下必须备份控制文件(至少备份一个)
4)非归档备份还原策略
恢复时还原所有备份,重建所有在线日志, 没有 recover 步骤。
SQL>startup mount
SQL>alter database clear unarchived logfile group n;(n 为所有在线日志组)
SQL>alter database open;
五)手工非一致性备份(热备份)
1)在备份前要进入热备模式,备份后要结束热备模式
执行 begin backup 设置备份模式(在数据文件上生成检查点,写入 scn ,将来恢复的时候以此 scn 为起点)
对只读的表空间不能做热备份,临时表空间不需要备份,特别强调:NOARCHIVE 模式下不支持手工热备。
对整个数据库设置热备模式:SQL> alter database begin backup
对整个数据库结束热备模式:SQL> alter database end backup;
对单个表空间设置热备模式:SQL> alter tablespace users begin backup;
对单个表空间结束热备模式:SQL> alter tablespace users end backup;
2)手工热备利用 v$backup 监控
例;
SQL> alter tablespace test begin backup;
SQL> select file#,checkpoint_change# from v$datafile_header;
FILE# CHECKPOINT_CHANGE#

资源由 www.eimhe.com 美河学习在线收集分享
---------- ------------------
1 2414314
2 2414314
3 2414314
4 2414314
5 2414314
6 2430480 在备份期间,scn 被冻结,当检查点发生时不受影响,它是恢复阶段运用日志的起点。
7 2414314
SQL> select * from v$backup;
FILE# STATUS CHANGE# TIME
---------- ------------------ ---------- -------------------
1 NOT ACTIVE 0
2 NOT ACTIVE 0
3 NOT ACTIVE 0
4 NOT ACTIVE 0
5 NOT ACTIVE 0
6 ACTIVE 2430480 2012-07-30 11:07:19
7 NOT ACTIVE 0
STATUS 是 ACTIVE,表示可以备份相应的数据文件。
$cp test01.dbf test01.bak
SQL> alter tablespace test end backup;
SQL> select * from v$backup;
备份完毕,尽快执行 end backup
如果在 end backup 之前发生数据库 abort,那么可以在下次启动到 mount 时 end backup,从而完成实例恢复。
六)split block(fractured block)问题
一个 Oracle block 一般包含多个 OS block,,当手工热备时,OS 的 cp 单位不是 Oracle block 而是 OS block,而 Oracle 的 DBWR 又
可能不时的从内存中刷新 Oracle block(脏块)到磁盘上,如此,OS 级的拷贝便可能造成:一个 Oracle Block 是由不同的版本组成,
比如未被 DBWR 刷新 Header block 加上另一部分被刷新的 foot block,这样 cp 出来的 Oracle blcok 就是 split block。
数据库的一致性是不允许 oracle block 是 split 的, split block 实际上属于 logical corruption Oracle 采取的办法是:在 backup mode
后,如果发现首次 DBWR 要写脏块,则将该块被刷新之前的镜像数据记录到 redo buffer,这样,虽然 cp 后的文件里仍然含有 split
block,而当需要恢复时,日志会前滚该块的前镜像,以保证所有被恢复的 oracle block 最终是一个完整的版本。
这就是我们常常发现在热备时日志文件会急剧增大的原因。
RMAN 备份不会造成 split block。 RMAN 备份时以 oracle block 为读取单元,并查验块的一致性,如果不一致会重复读,三次失
败,将标注该块为逻辑坏块。
第三章:手工完全恢复
一)基本概念
1)完全恢复的步骤
1)restore: OS 拷贝命令还原所有或部分 datafile
2)recover:SQL*PLUS 利用归档日志和当前的 redo 日志做恢复
2)完全恢复可以基于三个级别
recover database: 所有或大部分 datafile 损坏,一般是在 mount 状态完成
recover tablespace: 非关键表空间损坏,表空间下某些数据文件不能访问,一般是在 open 下完成
recover datafile: 单一或少量数据文件损坏,可以在 mount 或 open 状态完成
3)什么是关键文件
如果关键文件损坏,数据库将不能维持在 open 状态,或崩溃或死机!
哪些文件是关键文件:①system01 file,②undotbs file,③control file,④current log file
4)恢复过程可以查看的视图:
1)v$recover_file 查看需要恢复的 datafile
2)v$recovery_log 查看 recover 需要的 redo 日志
of 61
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
7
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

评论