

1



Whale:统一多种并行化策略的分布式深度学习框架.pdf
50墨值下载

A Unified Distributed Training Framework
Whale
Ang Wang
wangang.wa@alibaba-inc.com
PAI, Alibaba Cloud
15/12/2020
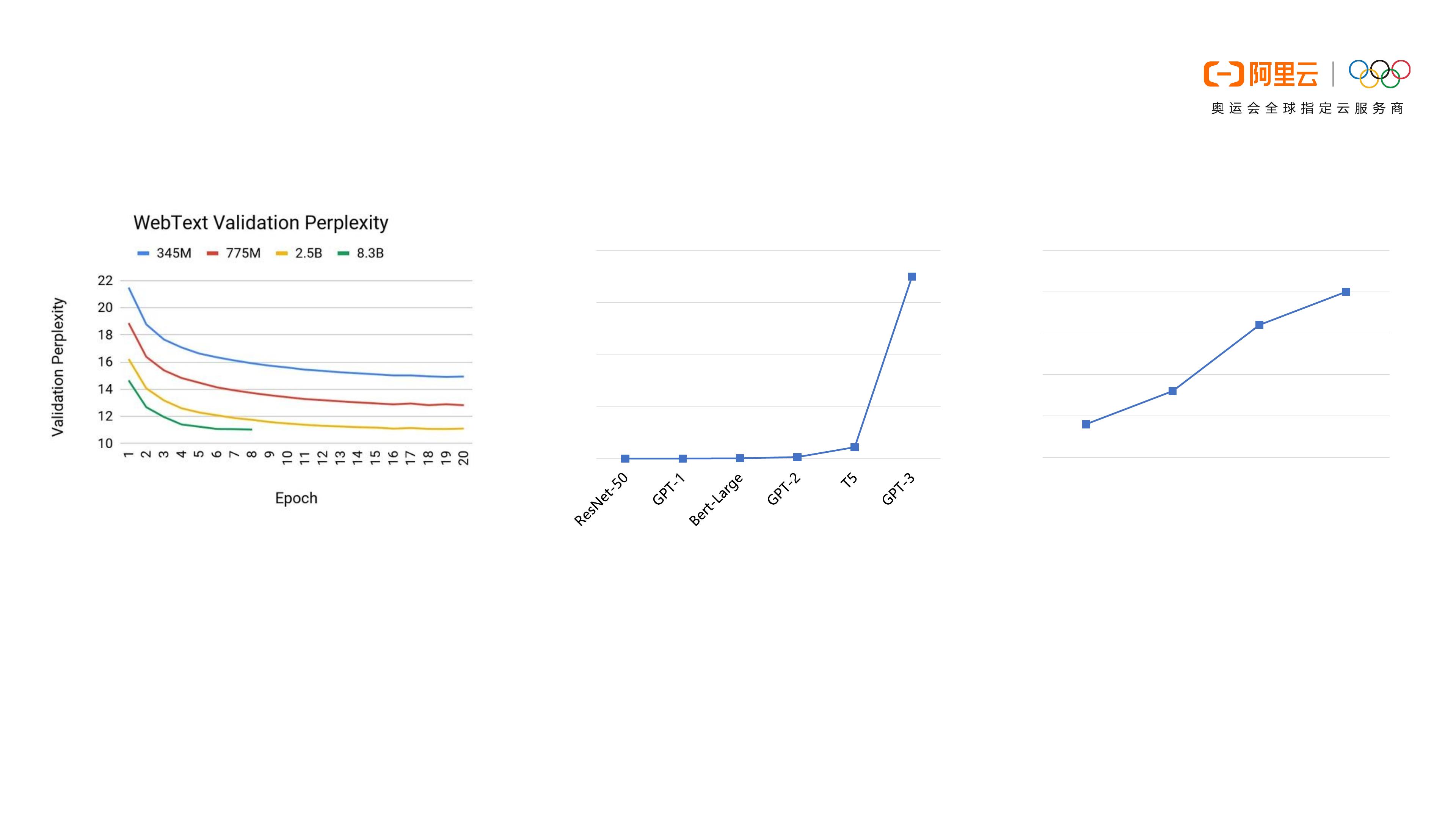
Motivation
25
117
340
1500
11000
175000
0
50000
100000
150000
200000
Parameters(M)
8
16
32
80
0
10
20
30
40
50
P4 P100 V100 A100
Memory (GB)
[1]
Models are getting larger
and more complex
Larger models lead to better
results with lower validation
perplexities
Model size grows far beyond
upgrading of hardware
[1] https://developer.nvidia.com/blog/training-bert-with-gpus/
Models are getting larger
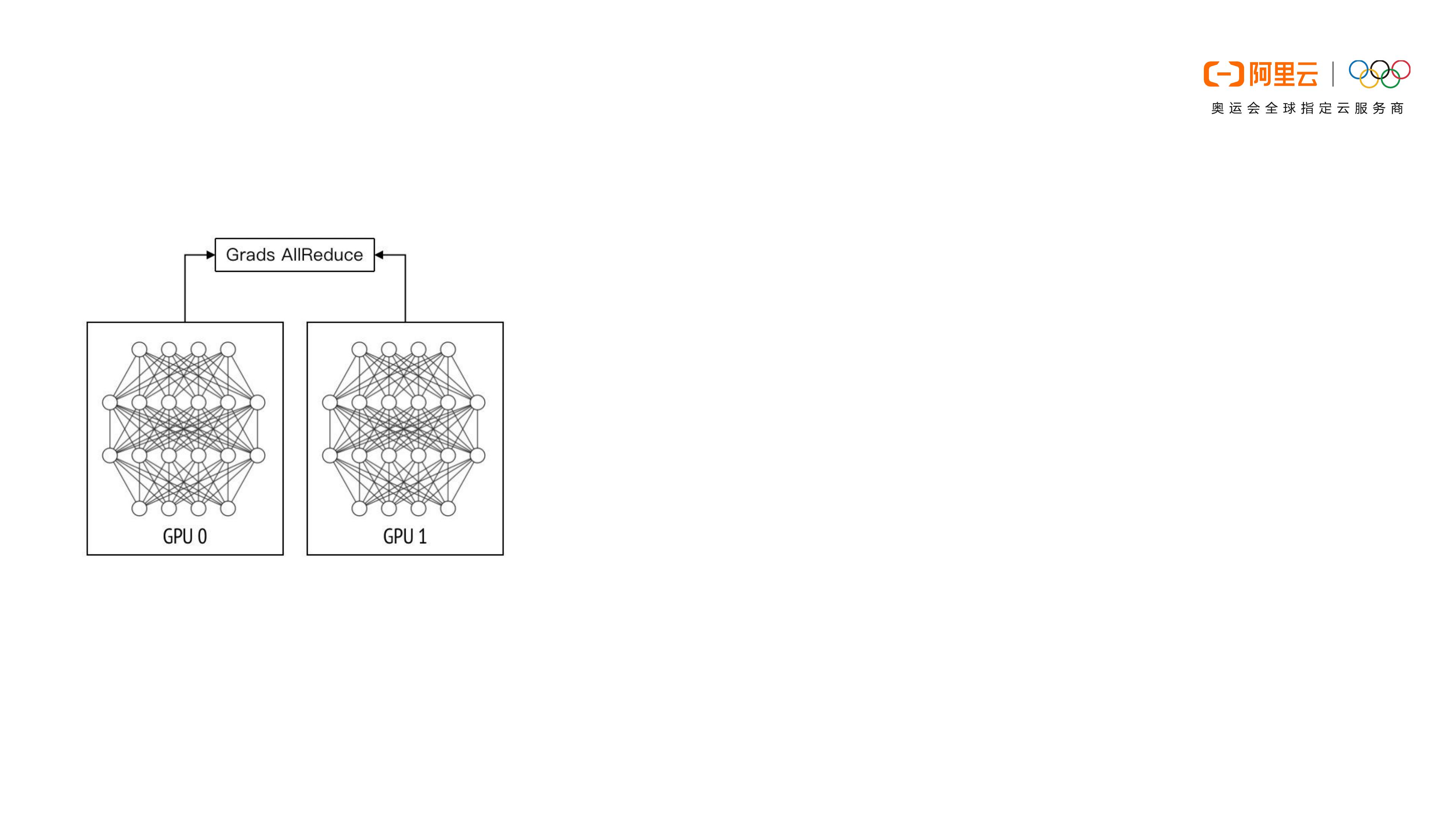
• Data Parallel(DP) is widely used in distributed training
as it is simple and easy to implement.
• DP is not always optimal for every distributed training
workloads.
• Necessary to find an efficient parallel strategy that can
make full use of the resources and speedup the training.
Motivation
Distribute the training
workload with data parallelism
Data parallelism becomes less optimal for lots of distributed workloads
of 19
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
最新上传
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
7
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

文档被以下合辑收录
相关文档
评论