




MapReduce_Simplified Data Processing on Large Clusters.pdf
免费下载

MapReduce: Simplified Data Processing on Large Clusters
Jeffrey Dean and Sanjay Ghemawat
jeff@google.com, sanjay@google.com
Google, Inc.
Abstract
MapReduce is a programming model and an associ-
ated implementation for processing and generating large
data sets. Users specify a map function that processes a
key/value pair to generate a set of intermediate key/value
pairs, and a reduce function that merges all intermediate
values associated with the same intermediate key. Many
real world tasks are expressible in this model, as shown
in the paper.
Programs written in this functional style are automati-
cally parallelized and executed on a large cluster of com-
modity machines. The run-time system takes care of the
details of partitioning the input data, scheduling the pro-
gram’s execution across a set of machines, handling ma-
chine failures, and managing the required inter-machine
communication. This allows programmers without any
experience with parallel and distributed systems to eas-
ily utilize the resources of a large distributed system.
Our implementation of MapReduce runs on a large
cluster of commodity machines and is highly scalable:
a typical MapReduce computation processes many ter-
abytes of data on thousands of machines. Programmers
find the system easy to use: hundreds of MapReduce pro-
grams have been implemented and upwards of one thou-
sand MapReduce jobs are executed on Google’s clusters
every day.
1 Introduction
Over the past five years, the authors and many others at
Google have implemented hundreds of special-purpose
computations that process large amounts of raw data,
such as crawled documents, web request logs, etc., to
compute various kinds of derived data, such as inverted
indices, various representations of the graph structure
of web documents, summaries of the number of pages
crawled per host, the set of most frequent queries in a
given day, etc. Most such computations are conceptu-
ally straightforward. However, the input data is usually
large and the computations have to be distributed across
hundreds or thousands of machines in order to finish in
a reasonable amount of time. The issues of how to par-
allelize the computation, distribute the data, and handle
failures conspire to obscure the original simple compu-
tation with large amounts of complex code to deal with
these issues.
As a reaction to this complexity, we designed a new
abstraction that allows us to express the simple computa-
tions we were trying to perform but hides the messy de-
tails of parallelization, fault-tolerance, data distribution
and load balancing in a library. Our abstraction is in-
spired by the map and reduce primitives present in Lisp
and many other functional languages. We realized that
most of our computations involved applying a map op-
eration to each logical “record” in our input in order to
compute a set of intermediate key/value pairs, and then
applying a reduce operation to all the values that shared
the same key, in order to combine the derived data ap-
propriately. Our use of a functional model with user-
specified map and reduce operations allows us to paral-
lelize large computations easily and to use re-execution
as the primary mechanism for fault tolerance.
The major contributions of this work are a simple and
powerful interface that enables automatic parallelization
and distribution of large-scale computations, combined
with an implementation of this interface that achieves
high performance on large clusters of commodity PCs.
Section 2 describes the basic programming model and
gives several examples. Section 3 describes an imple-
mentation of the MapReduce interface tailored towards
our cluster-based computing environment. Section 4 de-
scribes several refinements of the programming model
that we have found useful. Section 5 has performance
measurements of our implementation for a variety of
tasks. Section 6 explores the use of MapReduce within
Google including our experiences in using it as the basis
To appear in OSDI 2004 1

for a rewrite of our production indexing system. Sec-
tion 7 discusses related and future work.
2 Programming Model
The computation takes a set of input key/value pairs, and
produces a set of output key/value pairs. The user of
the MapReduce library expresses the computation as two
functions: Map and Reduce.
Map, written by the user, takes an input pair and pro-
duces a set of intermediate key/value pairs. The MapRe-
duce library groups together all intermediate values asso-
ciated with the same intermediate key I and passes them
to the Reduce function.
The Reduce function, also written by the user, accepts
an intermediate key I and a set of values for that key. It
merges together these values to form a possibly smaller
set of values. Typically just zero or one output value is
produced per Reduce invocation. The intermediate val-
ues are supplied to the user’s reduce function via an iter-
ator. This allows us to handle lists of values that are too
large to fit in memory.
2.1 Example
Consider the problem of counting the number of oc-
currences of each word in a large collection of docu-
ments. The user would write code similar to the follow-
ing pseudo-code:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
The map function emits each word plus an associated
count of occurrences (just ‘1’ in this simple example).
The reduce function sums together all counts emitted
for a particular word.
In addition, the user writes code to fill in a mapreduce
specification object with the names of the input and out-
put files, and optional tuning parameters. The user then
invokes the MapReduce function, passing it the specifi-
cation object. The user’s code is linked together with the
MapReduce library (implemented in C++). Appendix A
contains the full program text for this example.
2.2 Types
Even though the previous pseudo-code is written in terms
of string inputs and outputs, conceptually the map and
reduce functions supplied by the user have associated
types:
map (k1,v1) → list(k2,v2)
reduce (k2,list(v2)) → list(v2)
I.e., the input keys and values are drawn from a different
domain than the output keys and values. Furthermore,
the intermediate keys and values are from the same do-
main as the output keys and values.
Our C++ implementation passes strings to and from
the user-defined functions and leaves it to the user code
to convert between strings and appropriate types.
2.3 More Examples
Here are a few simple examples of interesting programs
that can be easily expressed as MapReduce computa-
tions.
Distributed Grep: The map function emits a line if it
matches a supplied pattern. The reduce function is an
identity function that just copies the supplied intermedi-
ate data to the output.
Count of URL Access Frequency: The map func-
tion processes logs of web page requests and outputs
hURL, 1i. The reduce function adds together all values
for the same URL and emits a hURL, total counti
pair.
Reverse Web-Link Graph: The map function outputs
htarget, sourcei pairs for each link to a target
URL found in a page named source. The reduce
function concatenates the list of all source URLs as-
sociated with a given target URL and emits the pair:
htarget, list(source)i
Term-Vector per Host: A term vector summarizes the
most important words that occur in a document or a set
of documents as a list of hword, frequencyi pairs. The
map function emits a hhostname, term vectori
pair for each input document (where the hostname is
extracted from the URL of the document). The re-
duce function is passed all per-document term vectors
for a given host. It adds these term vectors together,
throwing away infrequent terms, and then emits a final
hhostname, term vectori pair.
To appear in OSDI 2004 2
User
Program
Master
(1) fork
worker
(1) fork
worker
(1) fork
(2)
assign
map
(2)
assign
reduce
split 0
split 1
split 2
split 3
split 4
output
file 0
(6) write
worker
(3) read
worker
(4) local write
Map
phase
Intermediate files
(on local disks)
worker
output
file 1
Input
files
(5) remote read
Reduce
phase
Output
files
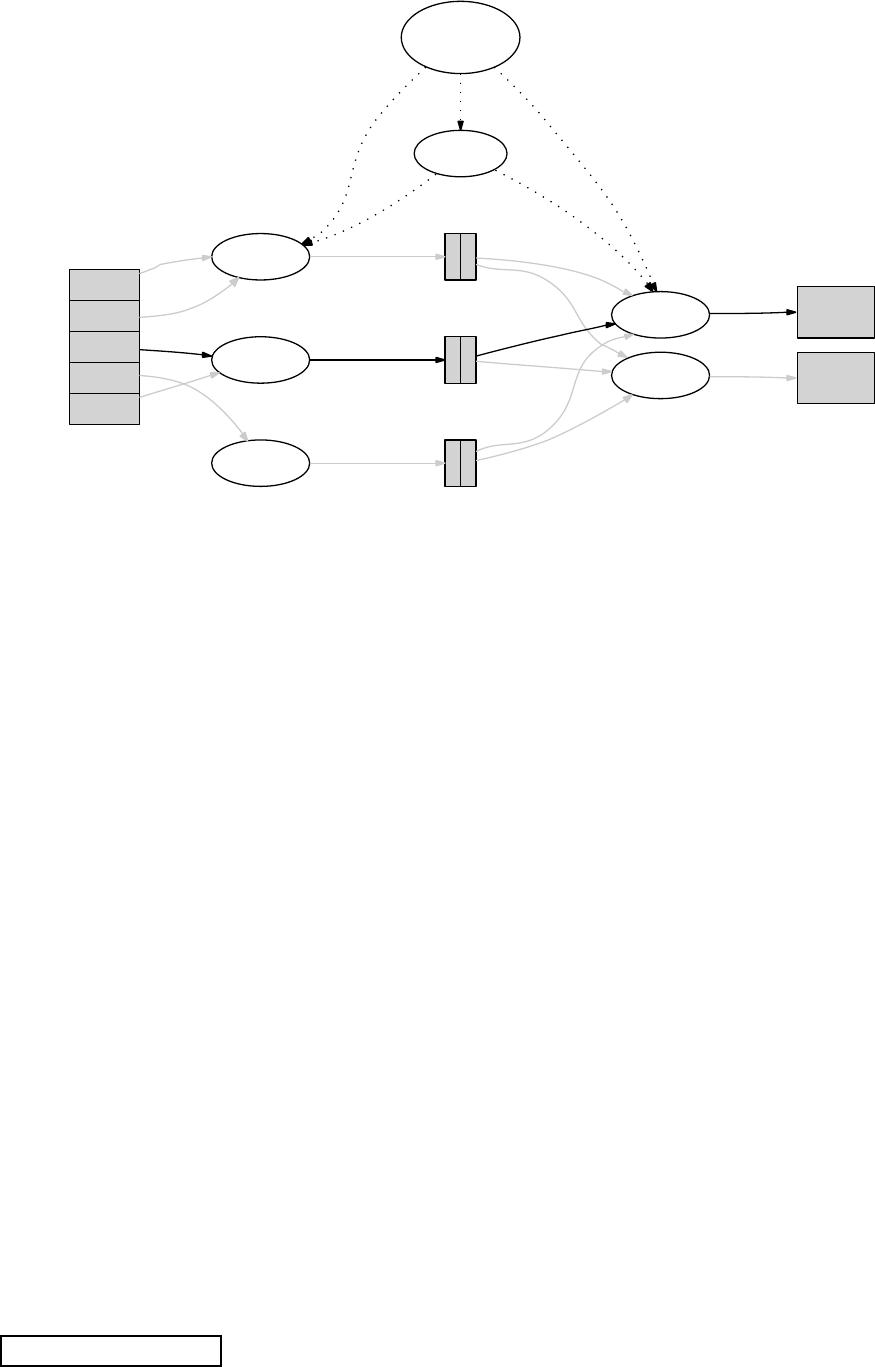
Figure 1: Execution overview
Inverted Index: The map function parses each docu-
ment, and emits a sequence of hword, document IDi
pairs. The reduce function accepts all pairs for a given
word, sorts the corresponding document IDs and emits a
hword, list(document ID)i pair. The set of all output
pairs forms a simple inverted index. It is easy to augment
this computation to keep track of word positions.
Distributed Sort: The map function extracts the key
from each record, and emits a hkey, recordi pair. The
reduce function emits all pairs unchanged. This compu-
tation depends on the partitioning facilities described in
Section 4.1 and the ordering properties described in Sec-
tion 4.2.
3 Implementation
Many different implementations of the MapReduce in-
terface are possible. The right choice depends on the
environment. For example, one implementation may be
suitable for a small shared-memory machine, another for
a large NUMA multi-processor, and yet another for an
even larger collection of networked machines.
This section describes an implementation targeted
to the computing environment in wide use at Google:
large clusters of commodity PCs connected together with
switched Ethernet [4]. In our environment:
(1) Machines are typically dual-processor x86 processors
running Linux, with 2-4 GB of memory per machine.
(2) Commodity networking hardware is used – typically
either 100 megabits/second or 1 gigabit/second at the
machine level, but averaging considerably less in over-
all bisection bandwidth.
(3) A cluster consists of hundreds or thousands of ma-
chines, and therefore machine failures are common.
(4) Storage is provided by inexpensive IDE disks at-
tached directly to individual machines. A distributed file
system [8] developed in-house is used to manage the data
stored on these disks. The file system uses replication to
provide availability and reliability on top of unreliable
hardware.
(5) Users submit jobs to a scheduling system. Each job
consists of a set of tasks, and is mapped by the scheduler
to a set of available machines within a cluster.
3.1 Execution Overview
The Map invocations are distributed across multiple
machines by automatically partitioning the input data
To appear in OSDI 2004 3
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
最新上传
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
7
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

文档被以下合辑收录
相关文档
评论