




巨杉数据库-P8高级运维管理.pdf
免费下载
8.1数据库弹性扩展能力
课程介绍
本课程主要介绍 SequoiaDB 巨杉数据库的弹性扩展能力。但受限于实验环境,分区组扩展仅在一台服务器上演示,
扩展步骤和原理与在多台服务器上原理保持一致。完成节点扩展后还将展示基于 split 方法的数据 rebalance,使数
据打散到所有分区组中。
SequoiaDB 巨杉数据库是一款金融级别的分布式数据库,可以通过集群的扩容实现集群性能的近线性增长。通过扩
容后主要解决两个问题:数据存储的容量问题和整个集群的性能问题。因为数据量的不断增长及上线后的推广使用,
所以需要进行扩容来提升集群性能及增加数据存储空间。
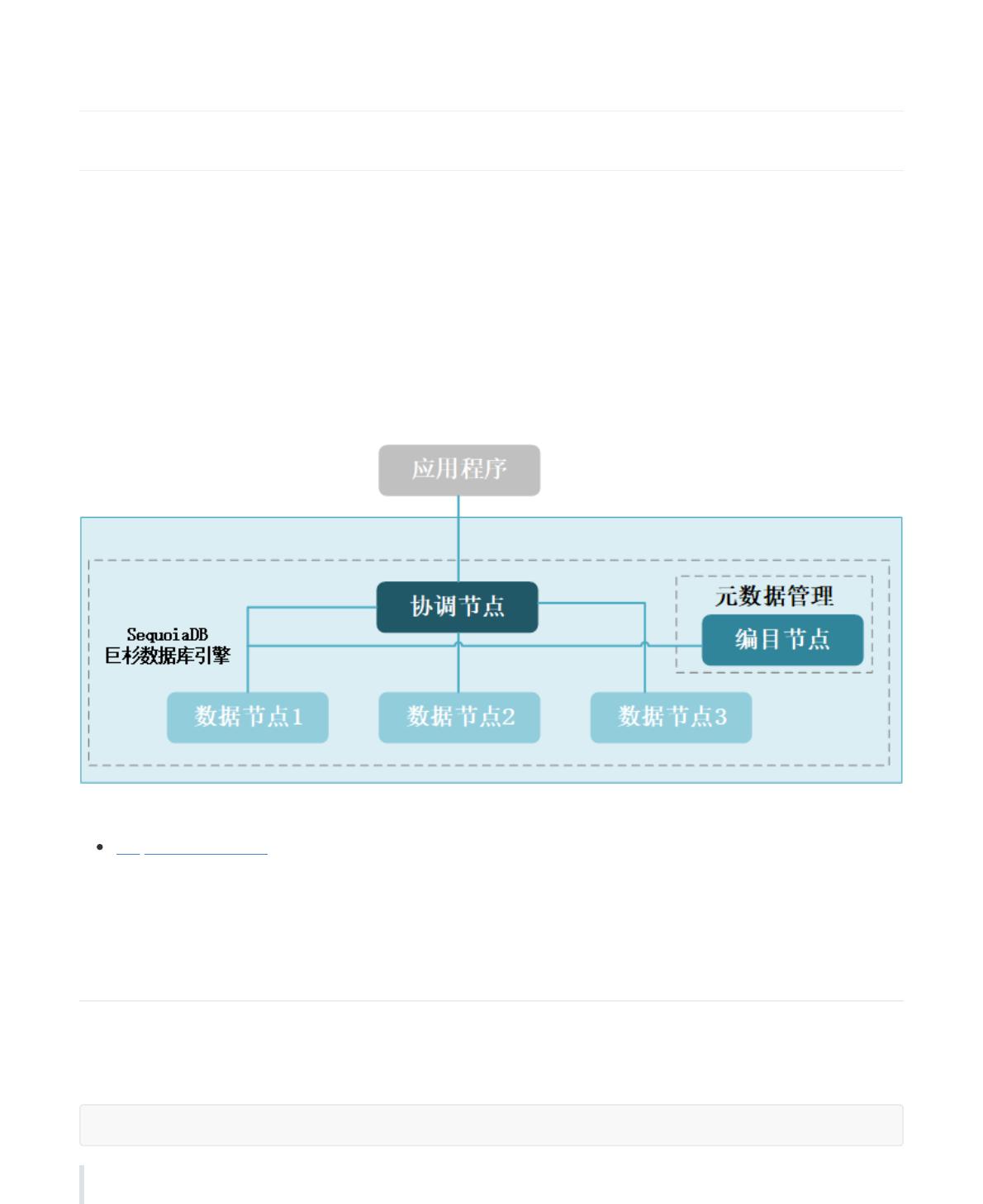
部署架构
本课程中的 SequoiaDB 巨杉数据库的集群拓扑结构为三分区单副本。
关于 SequoiaDB 巨杉数据库系统架构的详细信息,请参考如下链接:
SequoiaDB 系统架构
实验环境
课程使用的实验环境为 Ubuntu Linux 16.04 64 位版本。
切换用户及查看数据库版本
切换到 sdbadmin 用户
部署 SequoiaDB 巨杉数据库和 SequoiaSQL-MySQL 实例的操作系统用户为 sdbadmin。
su - sdbadmin
Note:
用户 sdbadmin 的密码为 sdbadmin
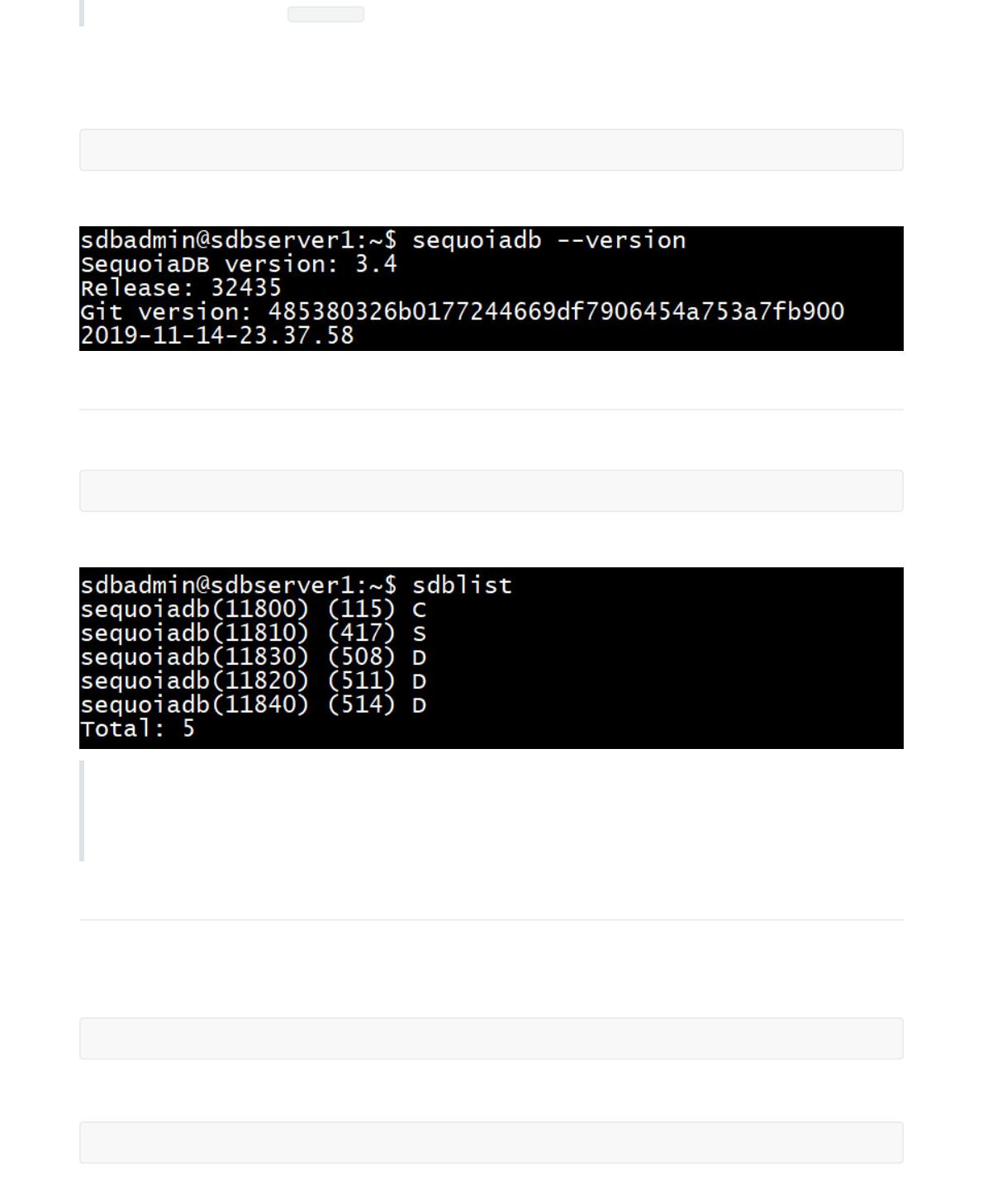
查看巨杉数据库版本
查看 SequoiaDB 巨杉数据库引擎版本:
sequoiadb --version
操作截图:
查看节点启动列表
查看 SequoiaDB 巨杉数据库引擎节点列表:
sdblist
操作截图:
Note:
如果显示的节点数量与预期不符,请稍等初始化完成并重试该步骤。
C: 编目节点,S:协调节点,D:数据节点
创建域、集合空间、集合
创建数据域、集合空间和集合,为集群扩容后数据重分布做准备。
1)通过 Linux 命令行进入 SequoiaDB Shell;
sdb
2)通过 javascript 语言连接协调节点,获取数据库连接;
var db = new Sdb("localhost", 11810);
3)创建 company_domain 逻辑域;
db.createDomain("company_domain", [ "group1", "group2", "group3" ], { AutoSplit: true } );
4)创建 company 集合空间;
db.createCS("company", { Domain: "company_domain" } );
5)创建 employee 集合;
db.company.createCL("employee", { "ShardingKey": { "_id": 1 }, "ShardingType": "hash",
"ReplSize": -1, "Compressed": true, "CompressionType": "lzw", "AutoSplit": true,
"EnsureShardingIndex": false } );
6)使用 JavaScript 的 for 循环向 employee 集合中写入 1000 条数据;
for (var i = 0; i < 1000; i++)
{
var record = { empno: i, ename: "TEST", age: 20 };
db.company.employee.insert(record);
}
7)通过查看集合快照信息,获取集合分区情况;
db.snapshot(SDB_SNAP_COLLECTIONS, { "Name": "company.employee" }, { "Details.GroupName": "",
"Details.Group.TotalRecords": "" } );
操作截图:
of 64
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
7
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

相关文档
评论