

1



awr分析思路.pptx
5墨值下载
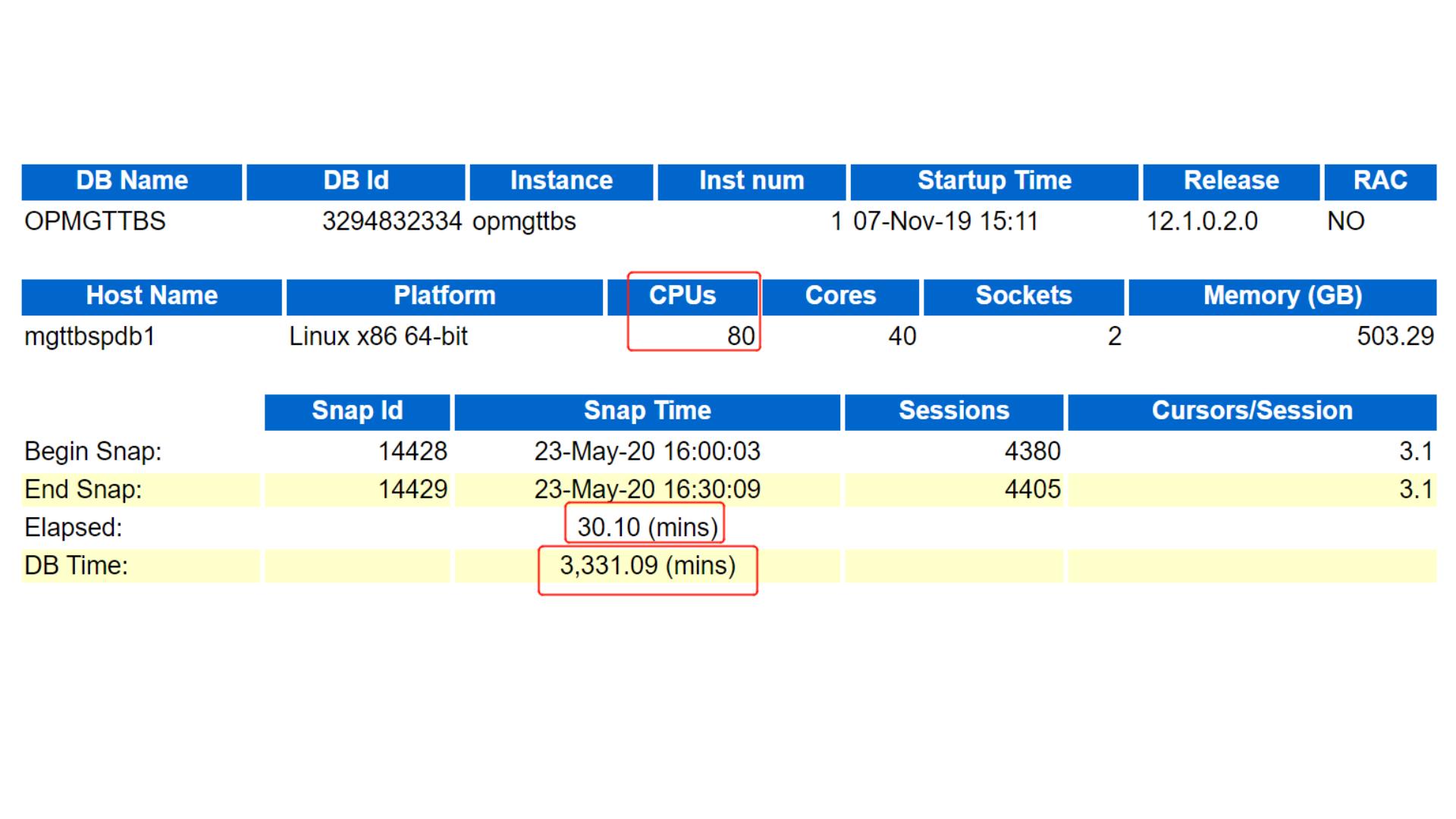
从 中我们可以看出,这套数据库是一个 的单例数据库,运行在 平台上,机器有 个逻辑 ,有 的内存。
我们可以得出快照收集时间是在 年 月 日 点和 点 分,快照时间是半个钟,而 有 分钟,远大于
( )分钟,说明该数据库负载比较高,存在明显的等待事件。
Awr 主机负载分析:
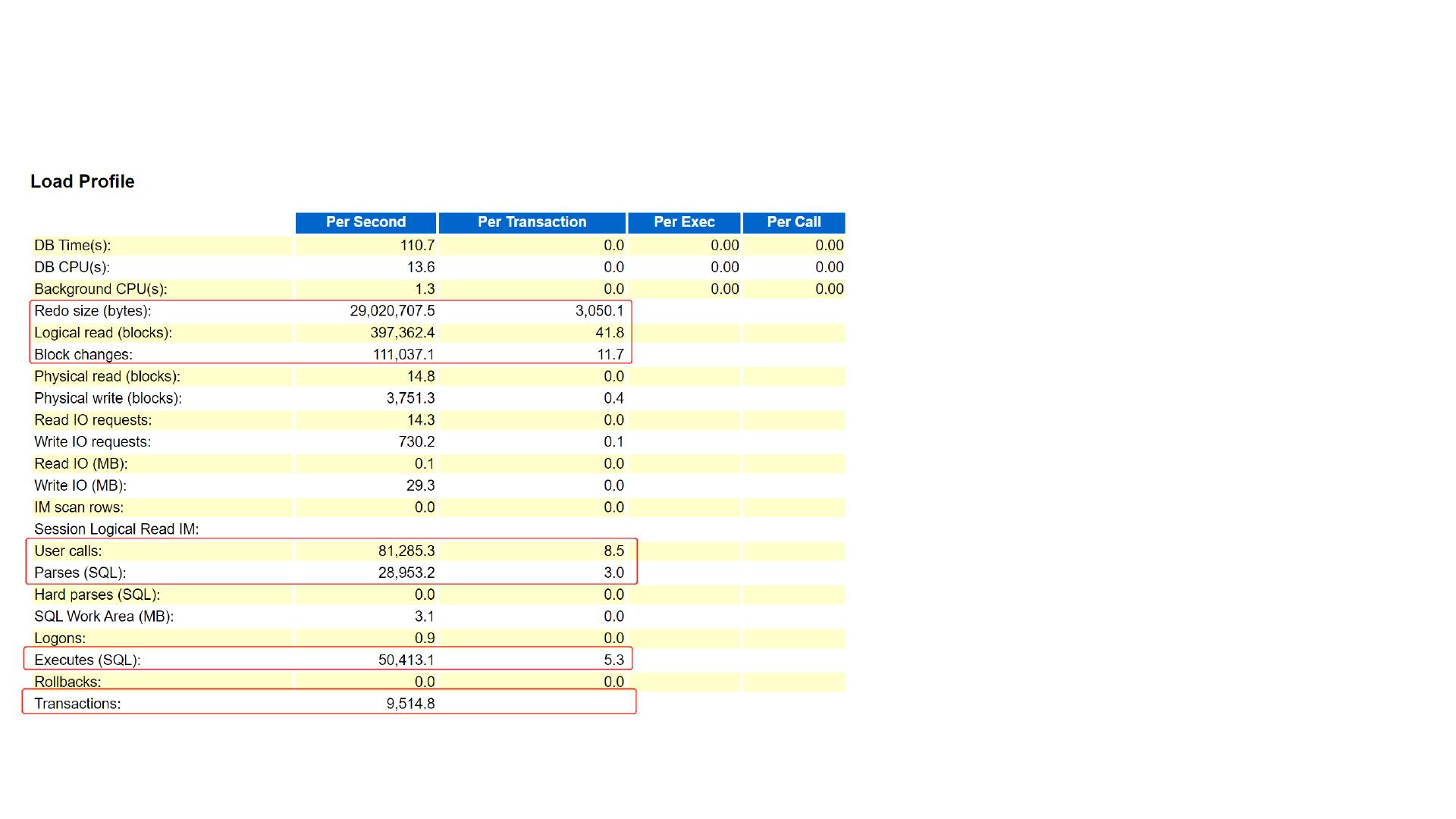
Awr 数据库负载分析:
关注这份指标中比较大的值。我们必须知道的事:
1. 日志切换频繁会导致每秒 日志产生量很大
;
2. 逻辑读和物理读可以判断是否存在硬解析;
3. 块变更和物理写可以判断是否数据块变更频率
;
4. 用户调用体现在登录、解析和执行的数据结构
;
5. 执行 和解析 的比例可以看 的重用率
;
6. 从事务量上可以判断数据库属于 !" 还是
!#" ;
7. 如果硬解析非常高需要查看 $%&'
和应用程序绑定变量的问题。

Awr 实例效率百分比:
1. (&) : 指的是可立即访问 ' 中所有数据而不用等待的次数的比例,若比例低,要查看 中 *()))) 等待;
2. (%) : 指的是数据库请求的数据在 *(% 中直接命中的比例,如果大量的查询走全表扫描的,该值会非常低;
3. !*+%) : 指的是将要执行的 语句或者 , 语句已经存在于 % 和 *+% 中可复用,该值与共享池大小关联;
4. -)) : 指的是 执行次数和解析次数的比值,该指标过低,常与开发人员的程序相关,没有进行绑定变量;
5. ") : 指的是解析过程中 时间占的比重,指标过低说明 % 过小或者未使用绑定变量;
6. .&) : 指的是 /&) 在 ' 可立即生成而不用等待的次数与全部的 /&) 的次数;
① 如果日志切换频繁,需要增加 &&' 大小;② 如果 ' 切换不频繁,说明可能磁盘 0 性能差,需更换高性能磁盘;
7. 0&/+) : 指的是内存内排序和磁盘排序之间的比例,若该值过低,需要增加 )$$1,'$''')$)') ;
8. 23) : 指的是需要执行的 语句或 , 程序可以在 *+% 中找到并复用;过低要查看绑定变量;过高可优化 ) ;
9. !)%%) : 指的是 )% 不需要等待即可获取的比例;
10.4&/ : 用在非解析上边的 时间,如果很低表明 时间花在解析上的时间很多,一般是由于 未复用。
软解析高,但 )) 低,可通过静态 ,绑定变量, &$%$ 和 &$ 等技术减少软解析。
of 12
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论