

 匿名用户
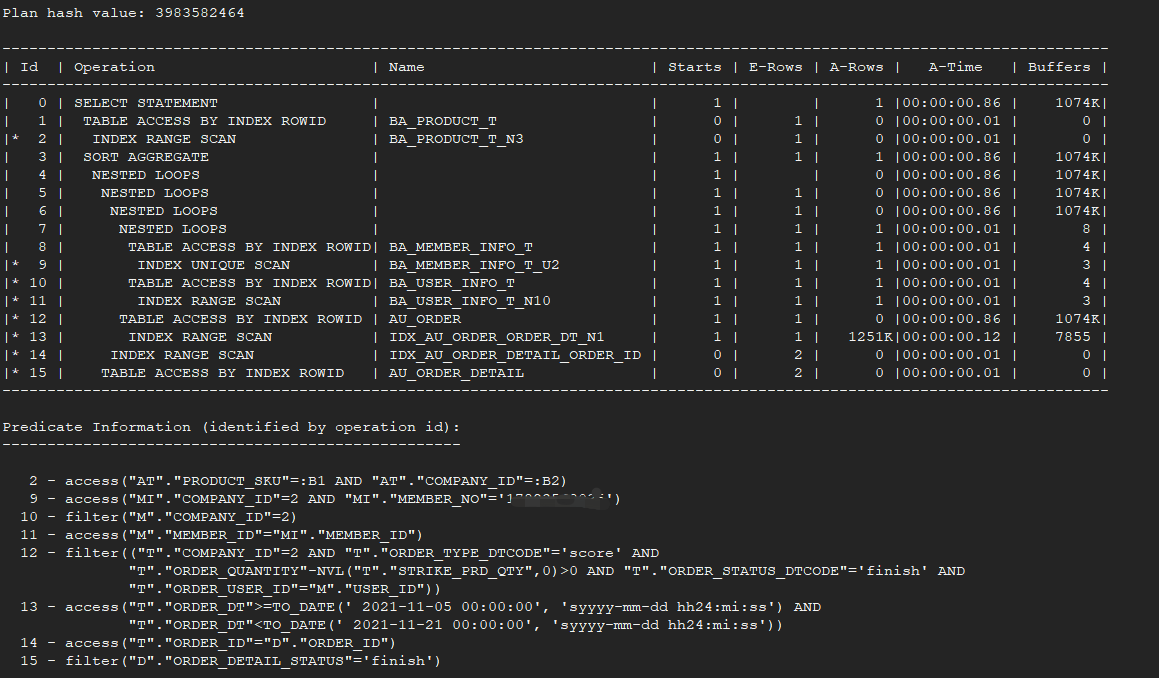
匿名用户该SQL查询如何建索引,从而到达优化该SQL的逻辑读。AU_ORDER T, BA_USER_INFO_T M, AU_ORDER_DETAIL D, BIZCRMDB.BA_MEMBER_INFO_T MI都是上百万和千万的大表, BASEDB.BA_PRODUCT_T只有几千数据。请大师指点一下
SELECT TO_CHAR(NVL(SUM(D.QUANTITY *
(SELECT to_number(AT.standard_tin)
FROM BASEDB.BA_PRODUCT_T AT
WHERE AT.PRODUCT_SKU = D.PRODUCT_SKU
AND AT.COMPANY_ID = T.COMPANY_ID)),
0),
'FM99999990.09999') PURSTANDARDNUM
FROM AU_ORDER T, BA_USER_INFO_T M, AU_ORDER_DETAIL D, BIZCRMDB.BA_MEMBER_INFO_T MI
WHERE T.ORDER_TYPE_DTCODE = 'score'
AND T.ORDER_STATUS_DTCODE = 'finish'
AND D.Order_Detail_Status = 'finish'
AND T.COMPANY_ID = 'X'
AND T.ORDER_USER_ID = M.USER_ID
AND T.COMPANY_ID = M.COMPANY_ID
AND T.ORDER_DT < TO_DATE('20211121', 'YYYYMMDD')
AND T.ORDER_DT >= TO_DATE('20211105', 'YYYYMMDD')
AND T.ORDER_QUANTITY - NVL(T.STRIKE_PRD_QTY, 0) > 0
AND T.ORDER_ID = D.ORDER_ID
AND M.MEMBER_ID = MI.MEMBER_ID
AND MI.COMPANY_ID = M.COMPANY_ID
AND MI.MEMBER_NO = 'XXXXXXX';
 评论
评论
 墨值悬赏
墨值悬赏