

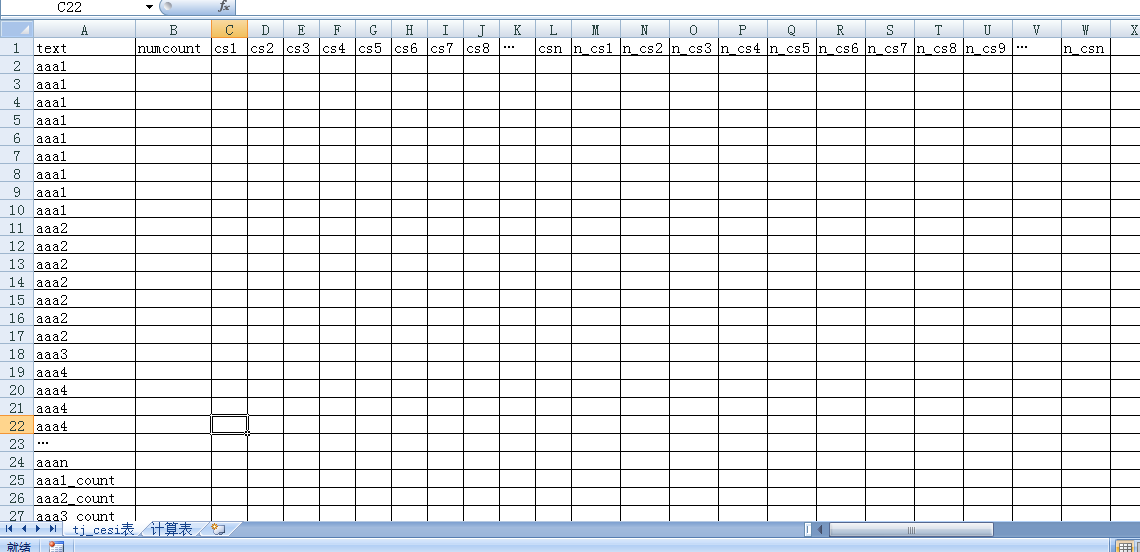
我有个表tj_cesi里有个text字段,该字段里内容有很多,如表格所示主要内容为aaa1---aaan(有几百个,而且是没规律的存在,长度或个数都不一样,比如是asd1、d2f3、asdfd、rad2dss.....等等,我用aaa1-n表示,是为了简单描述),而每个相同的aaa?有不同的个数的存在,但相对应的aaan_count都是唯一的一个。
我想到过用过渡表的方式,先做个text表,把text内容写进去

insert into text表 (text) select text from tj_cs b group by b.text;
update text表 set text_count=text||'_count';
update tj_cs a set numcount=(select count(*) from cgltj_cs where text='aaa1') where a.text='aaa1_count';
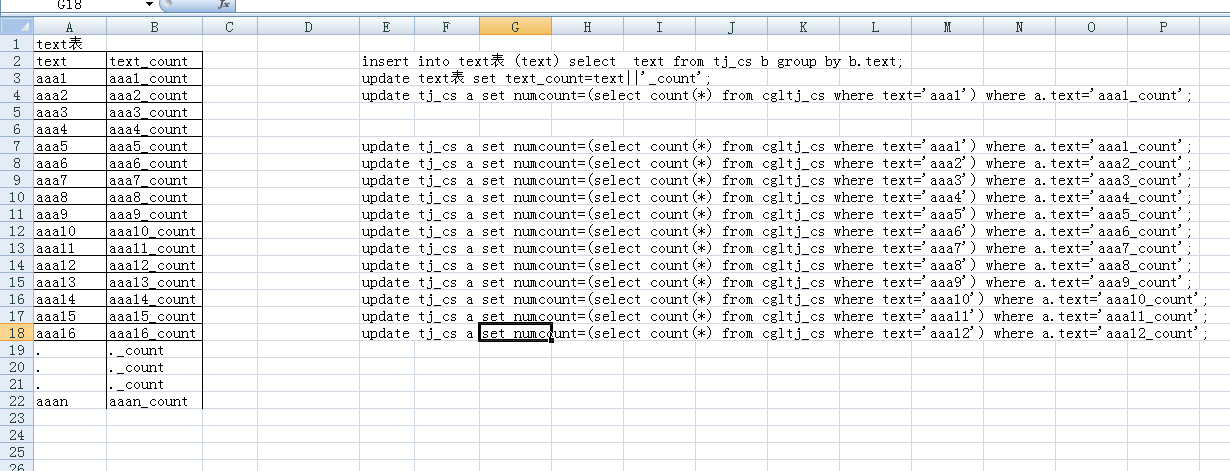
我要实现的第1个目的是在每个aaan_count的numcount字段里统计个数(类似下面语句,但写起来会有几百条语句)
update tj_cesi a set numcount=(select count(*) from cgltj_cesi where text='aaa2') where a.text='aaa2_count';
update tj_cesi a set numcount=(select count(*) from cgltj_cesi where text='aaa3') where a.text='aaa3_count';
。
。
。
update tj_cesi a set numcount=(select count(*) from cgltj_cesi where text='aaan') where a.text='aaan_count';
我要实现的第2个目的是在每个aaa1-n的n_cs1-n里的个数与其相对应的numcount的比值,写到它对应的aaa _count里,(类似下面语句,但写起来会有几千条语句)
update tj_cs a set n_cs1=(select count(*) from tj_cs where text='aaa1' and cs1=1)/numcount where a.text='aaa1_count';
update tj_cs a set n_cs1=(select count(*) from tj_cs where text='aaa2' and cs1=1)/numcount where a.text='aaa2_count';
update tj_cs a set n_cs1=(select count(*) from tj_cs where text='aaa3' and cs1=1)/numcount where a.text='aaa3_count';

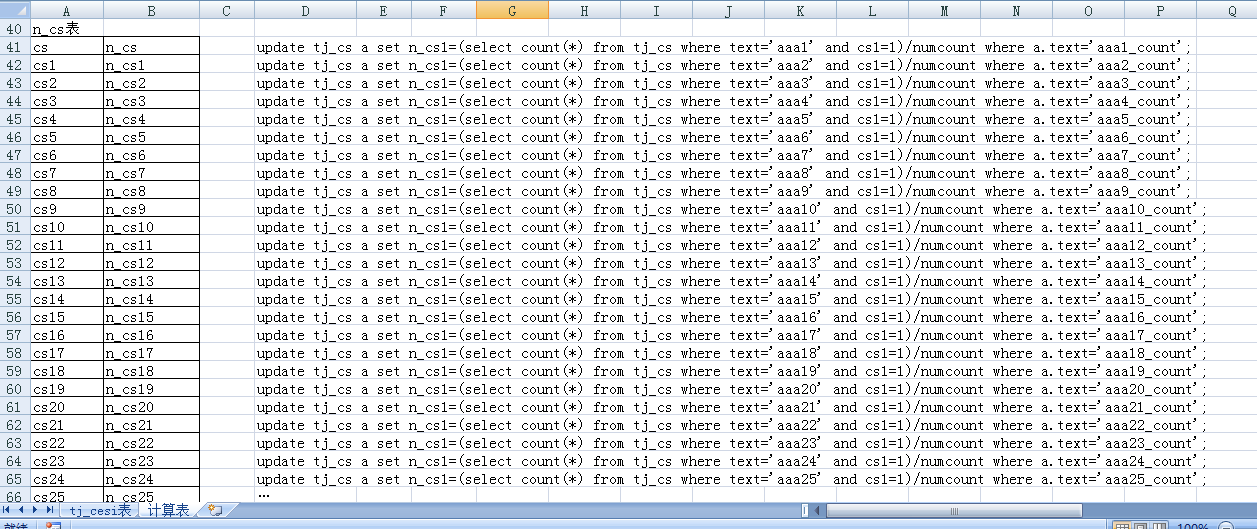
(听说用存储的方法,但存储方法没学过),不知道有没有哪位老师可以用简单的方式实现,谢谢!
 评论
评论

