
各位大佬,请教一下oracle的db file async I/O submit等待事件有没有排查思路呢?数据库运行缓慢的时候查询了库里的等待情况和redo的状态:
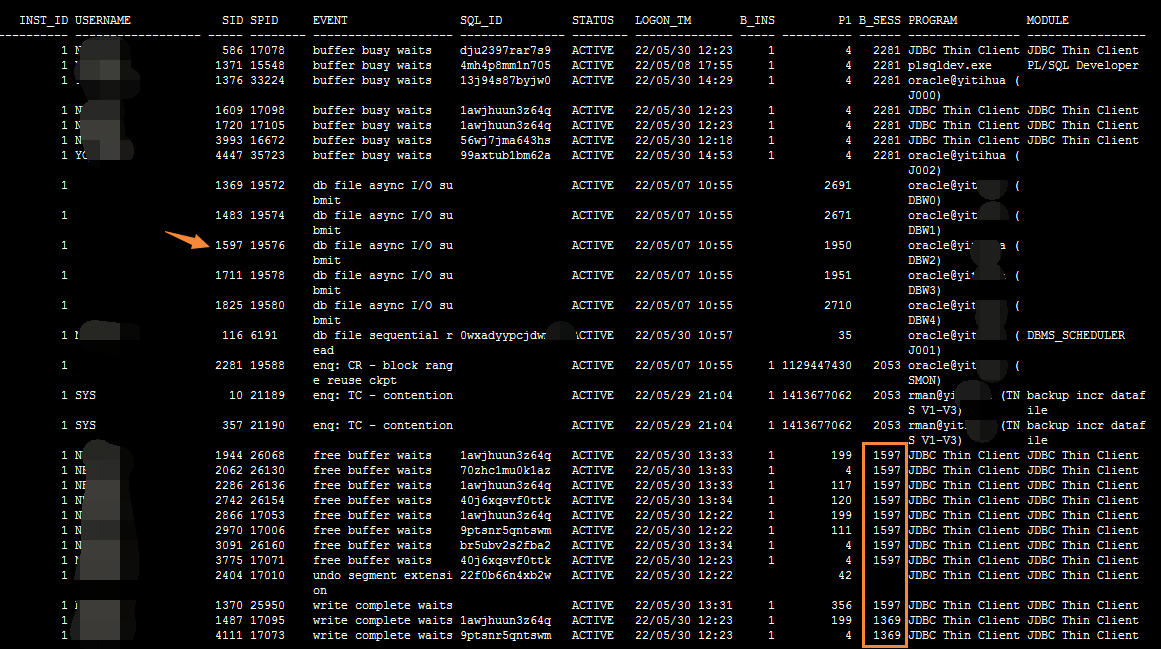
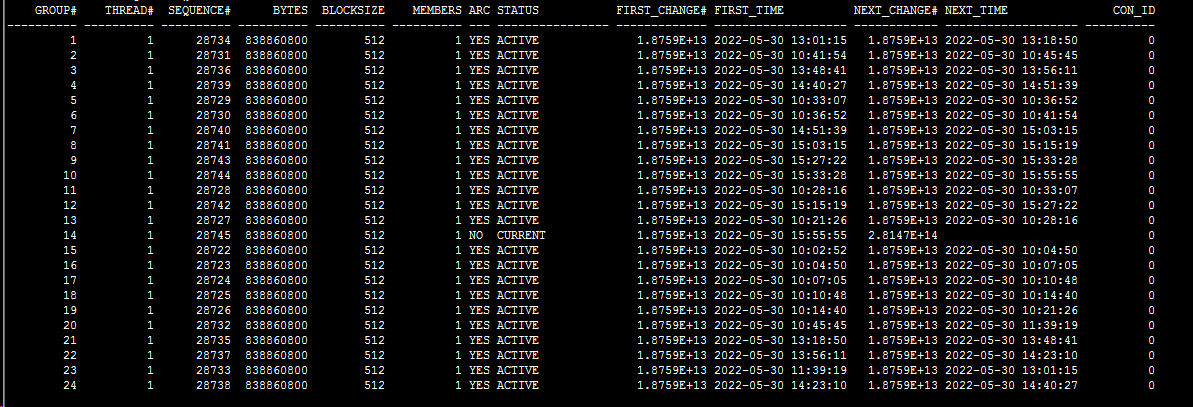
也测了一下磁盘的写情况


可以看到1579这个sid实际上就是后台dbwn进程,这个等待事件也是跟io有关的等待事件,是异步IO相关的等待事件,简单说就是io请求是异步的。
可以研究下这几个参数
disk_asynch_io
filesystemio_options
disk_asynch_io为TRUE,filesystemio_options为NONE的情况下,出现db file async I/O submit等待,可以设置filesystemio_options参数为ASYNCH或者SETALL,使得db file parallel write等待代替db file async I/O submit等待。
参考这个文档:(Doc ID 1274737.1)
 评论
评论 有用 0
有用 0可以参考楼下说的,查看异步IO是否开启,不行的话可以配置更多的DBWR,但是DBWR不能超过CPU个数。
评论 有用 0你这个等待事件是oracle计算异步io类的等待事件;但是有没有真正的启用异步Io要看你的参数,另外就是需要看你的awr里面的io等待时间。
1.disk_asynch_io,filesystemio_options参数发出来;
2.awr发出来看看
可以参考
https://www.modb.pro/db/21265
评论 有用 0 评论 有用 0
根据上传的awr
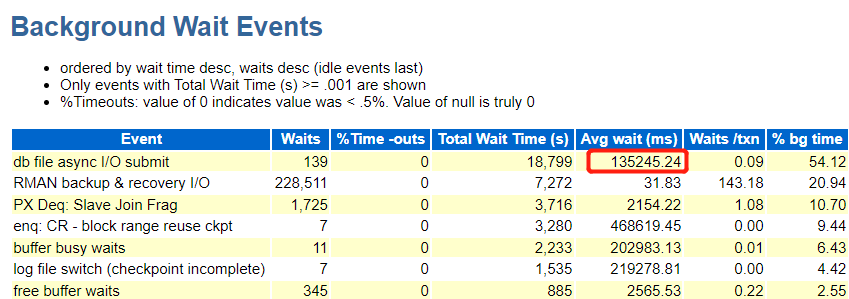
io很差,当然和数据库有备份也有关系。
参考
How To Check if Asynchronous I/O is Working On Linux (Doc ID 237299.1)
无论 filesystemio_options 参数如何,ASM 固有地执行异步 I/O(文档 ID 751463.1)
Oracle Database - Enterprise Edition - Version 9.0.1.0 to 12.1.0.2 [Release 9.0.1 to 12.1]
你的awr是no rac使用文件系统,排除asm干扰。
那么结合参数看,你这个虽然disk_asynch_io True看起来启用了异步IO,但是由于参数filesystemio_options = none,实际上没有真正的使用异步IO。
Example strace of dbw0 process with AIO enabled (init.ora parameter filesystemio_options = asynch) shows:
…
io_submit(3071864832, 1, {{0xb7302e34, 0, 1, 0, 21}}) = 1
gettimeofday({1176916625, 58882}, NULL) = 0
io_getevents(-1223102464, 1, 1024, {{0xb7302e34, 0xb7302e34, 8192, 0}}, {600, 0}) = 1
…
Example strace of dbw0 process with AIO disabled (filesystemio_options = none):
…
pwrite64(21, “\6\242\0\0004\21\300\0\220B\243\0\0\0\1\6\207\357\0\0\1”…, 8192, 36077568) = 8192
times(NULL) = 1775653082
times(NULL) = 1775653082
pwrite64(21, “\6\242\0\0<\21\300\0\220B\243\0\0\0\1\6\254\0\0\0\2\0*”…, 8192, 36143104) = 8192
…
建议比较简单,和上面的说的一样,调整参数
设置filesystemio_options参数为ASYNCH
这样数据库真正使用异步IO写,在IO比较差的环境下,可以减少IO类的等待,整体提升数据库性能。
另外就是你的awr log file switch (checkpoint incomplete) 这个是什么原因导致的? 你的日志组数量,日志文件大小这块有没有格式化。 一般建议日志大小是20分钟切换一个redo,日志组一般是1个thread设置10组,当然如果业务很少3组就够了。 你的问题是所有redo都是active,这说明日志文件大小+日志文件组 不够用。
dbca默认3组redo,每个日志文件50M;
group 1 50m 写满;
group 2 50m 写满;
group 3 50m 写满;
这个时候redo需要切换,复用group 1 or group 2;
那这个复用的前提条件是group 1 or group 2对应的buffer cache中的脏块落盘,dbwr写脏块完成。
然后你的系统dbwr写的贼慢!!! 当然redo大小不合理也存在这个问题。 例如dbca默认的情况下150M redo就会发送等待,所有redo都是active. 如果10组redo,每组1g size . 那么redo只有写入100G的时候,才可能出现所有redo都是active 状态。
评论 有用 010*1=10g 笔误,可以看看https://www.cnblogs.com/lvcha001/p/9180514.html
评论 有用 0从你AWR看,一个是对hdi_larexadet_list的delete、insert操作上,产生了buffer waits,一个是RMAN backup & recovery I/O,由于这两个消耗了IO。可以按楼上说的调节参数试下,还有就是SQL优化上的,和开发讨论怎么处理好这样的操作。有些事DBA不背锅。
评论 有用 0
 墨值悬赏
墨值悬赏