

2022-08-29
请教一个有挑战性的问题,同一个SQL,完全不同的执行计划
大佬们好,请教一个有挑战性的问题。同一个SQL,涉及到6-7张表。
测试环境为 oracle11.2.0.4,64位。
现在用dbsm_stats和analyze分别对这些表收集统计信息,然后执行相同SQL,发现执行计划完全不同。
在dbms_stats.gather_table_stats收集统计信息之后,SQL的执行计划为:
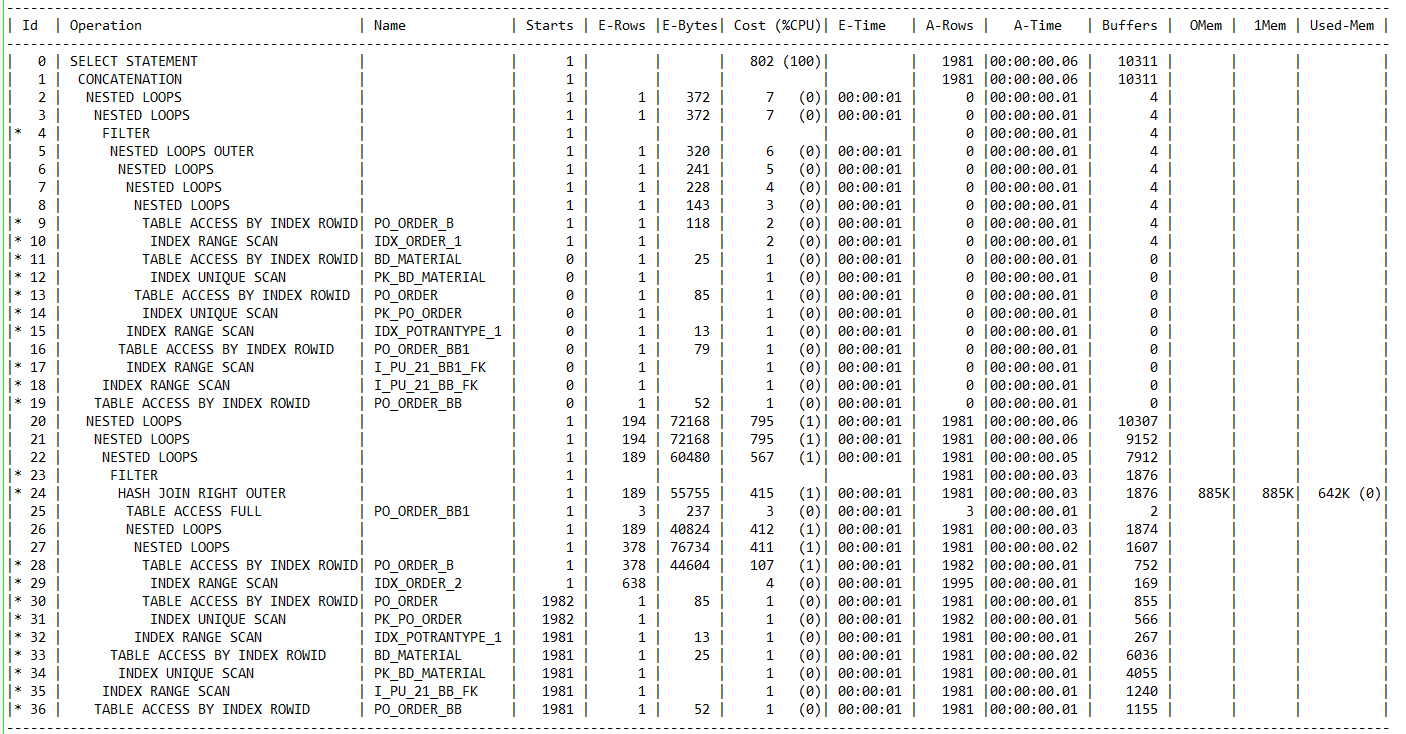
在analyze收集统计信息之后,SQL的执行计划为:
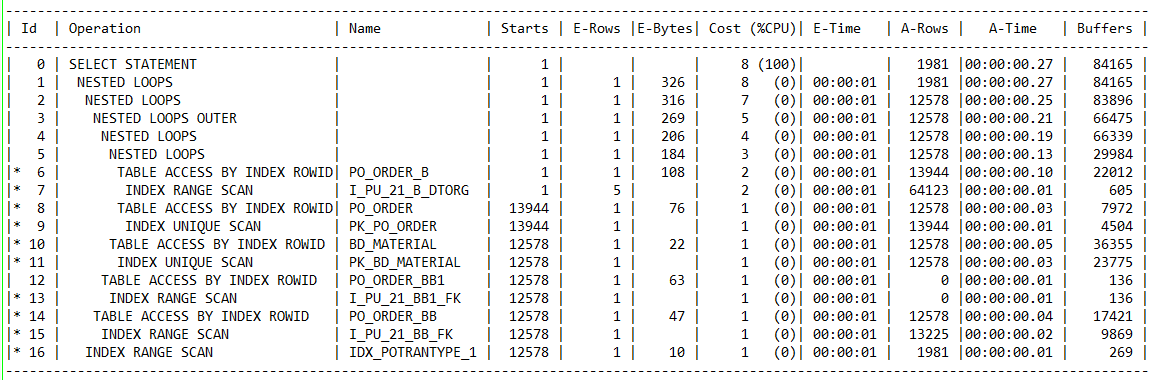
查看表和相关索引的统计信息SQL:
select table_name, num_rows, blocks, last_analyzed
from user_tab_statistics
where table_name = 'PO_ORDER_B';
select table_name, index_name, num_rows, distinct_keys, last_analyzed, leaf_blocks, clustering_factor
from user_indexes
where table_name = 'PO_ORDER_B'
and index_name = 'I_PU_21_B_DTORG'
order by 2;
select blevel, table_name, index_name, num_rows, distinct_keys, last_analyzed, leaf_blocks, clustering_factor
from user_ind_statistics
where index_name = 'I_PU_21_B_DTORG';复制通过以上SQL查看,发现dbms_stats和analyze两种方式收集的统计信息,基本接近,相差无几。
为什么同一个SQL,使用dbms_stats和analyze两种方式采集统计信息之后,执行计划相差如此之大呢?
请教大佬们,提供个分析排查思路。谢谢。
我来答
添加附件
收藏
分享
问题补充
5条回答
默认
最新
 评论
评论




回答交流
Markdown
请输入正文
提交
问题信息
请登录之后查看
附件列表
请登录之后查看
邀请回答
暂无人订阅该标签,敬请期待~~
 墨值悬赏
墨值悬赏