
 匿名用户
匿名用户Oracle12c的新功能批量回表(TABLE ACCESS BY INDEX ROWID BATCHED),pg或者mysql,或者db2
那个有类似是功能??

Mysql 回表的功能MRR (Disk-Sweep Multi-Range Read)
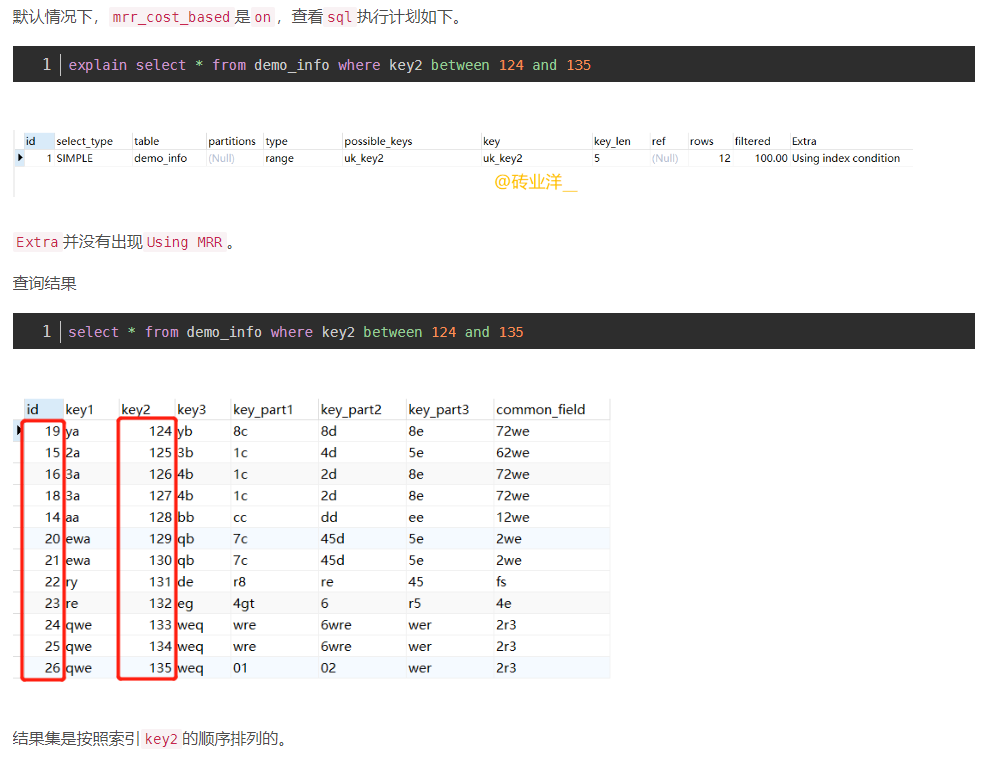
当mysql读取一批二级索引时,会将根据这些二级索引拿到的主键id进行排好序,去批量回表到主键索引拿,这个优化过程由Mysql自行控制,我们无法干预,这就是MRR技术,多范围查询技术。
MRR(multi-range read) 【optimizer_switch mrr 和 mrr_cost_base控制】,主要是为了在辅助索引的扫描时候,一般的,都会去随机的从磁盘读取数据文件,导致效率很低。这个优化是将相关的keys收集排序,最终回表查询的时候是按照主键的顺序去查询,减少了随机读取磁盘文件
在MySQL当前版本中,基于成本的算法过于保守,导致大部分情况下优化器都不会选择MRR特性。为了确保优化器使用mrr特性
请执行下面的SQL语句:
set optimizer_switch=‘mrr=on,mrr_cost_based=off’ 这种设置将会始终启用MRR优化
read_rnd_buffer_size 参数来决定MRR 优化的时候可以使用多少内存存储中间rowid
MRR的原理(Disk-Sweep Multi-Range Read)
每次根据主键回表时,虽然是按照非聚集索引排好序的,但是这些记录的主键id是无序的,也就是说,这些非聚集索引记录对应的聚集索引记录所在的页面也是无序的。每次回表都要重新定位页的位置,将聚集索引页读取出来,这些非连续I/O的性能开销很大。
因为大多数的数据都是按照主键递增顺序插入得到的,所以我们可以认为,如果按照主键递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能。
于是,便有了MRR(Disk-Sweep Multi-Range Read,多范围读取)的优化措施。即先读取一部分满足条件的非聚集索引记录,将它们的主键值排好序之后再统一回表,相比于每读取一条非聚集索引记录就回表,这样会节省一些I/O开销(比如记录更有可能在同一页)。
https://blog.csdn.net/qq_34115899/article/details/118004118
 评论
评论 有用 0
有用 0
可以参考下这篇微信公众号文章:https://mp.weixin.qq.com/s?__biz=Mzk0NzE4MjYzOQ==&mid=2247486599&idx=1&sn=4162a46a9b8c5e244ddc98f5ca49bfa3&chksm=c37b81c7f40c08d14ca28727182f0c93d27a64484c61b17a0aa2734702ece69205e2729aebff&cur_album_id=1612711574396321793&scene=189#rd
评论 有用 0 墨值悬赏
墨值悬赏