

 匿名用户
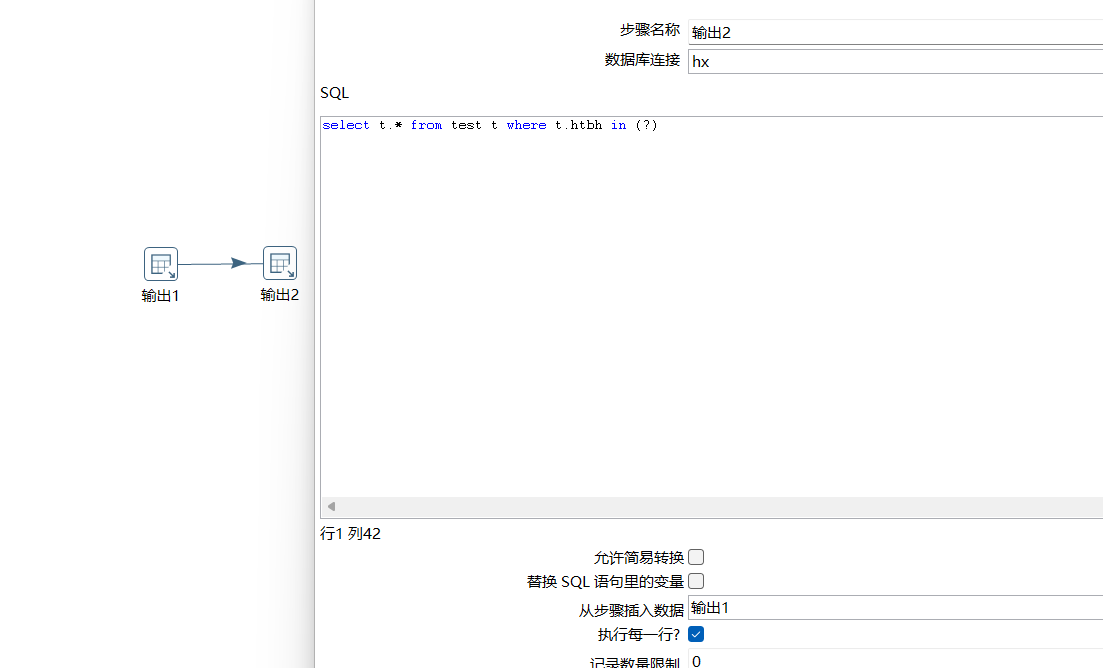
匿名用户kettle建了俩个表出输出,输出2基于输出1查询的,但是输出2用了in 每次只是里面in1一个,有没有办法一次in几百个或者能用EXISTS吗?
我来答
添加附件
收藏
分享
问题补充
1条回答
默认
最新
 评论
评论
回答交流
Markdown
请输入正文
提交
相关推荐
状态是recover数据文件怎么彻底删除?
回答 1
要进行恢复。如果说不要了,要offline才能删除
Hubble数据库支持分布式事务吗?
回答 1
Hubble数据库支持分布式事务,并且支持最高级别的串行化事务,天云数据Hubble数据库将事务分配到集群节点。用户可以访问任意节点发起事务操作,也不需要关心分片具体分布在哪个节点上,Hubble自动
达梦数据库上有什么好用的实时同步工具吗?
回答 1
用dmhs
HANA 1.00.122.06.1485334242 如何删除备份记录
回答 1
SAP HANA不允许删除差异备份,因为它是基于上一次全量备份或增量备份的变更。如果删除了差异备份,那么在恢复数据时,将无法应用这些变更,可能导致数据丢失。如果你确实需要删除备份
RPO
回答 1
已采纳
恢复点目标
数据库下沉是什么意思?
回答 2
数据库从来都是在最底层,再下沉的话,估计就把数据库取消掉算了
新加了一列,想实现上图这样自动插入时间 ,发现没有这个选项
回答 1
已采纳
altertableqaddcolumntTIMESTAMPnotnulldefaultCURRENTTIMESTAMP;
有没有比较好的数据差异对比工具推荐?
回答 1
这个要看什么数据库,以及对比的场景是什么?
数据库高并发怎么处理?
回答 2
看是什么高并发,如果是查询高并发可以扩展多个节点,分摊查询压力,如果是修改或者插入高并发,可以采用消息队列削峰处理
怎么处理数据库阻塞呢?
回答 1
已采纳
生产库的话。我一般这么做。找到阻塞的语句。根据语句判断是否可以kill 如果可以kill的话。就直接kill掉。让用户业务先流畅起来。然后再慢慢分析阻塞的原因。
问题信息
请登录之后查看
邀请回答
暂无人订阅该标签,敬请期待~~

