

 匿名用户
匿名用户想请教各位大佬一个问题相同版本的库,表数据和结构都一样为什么执行过程不一样呢?
想请教各位大佬一个问题相同版本的库,表数据和结构都一样为什么执行过程不一样呢?
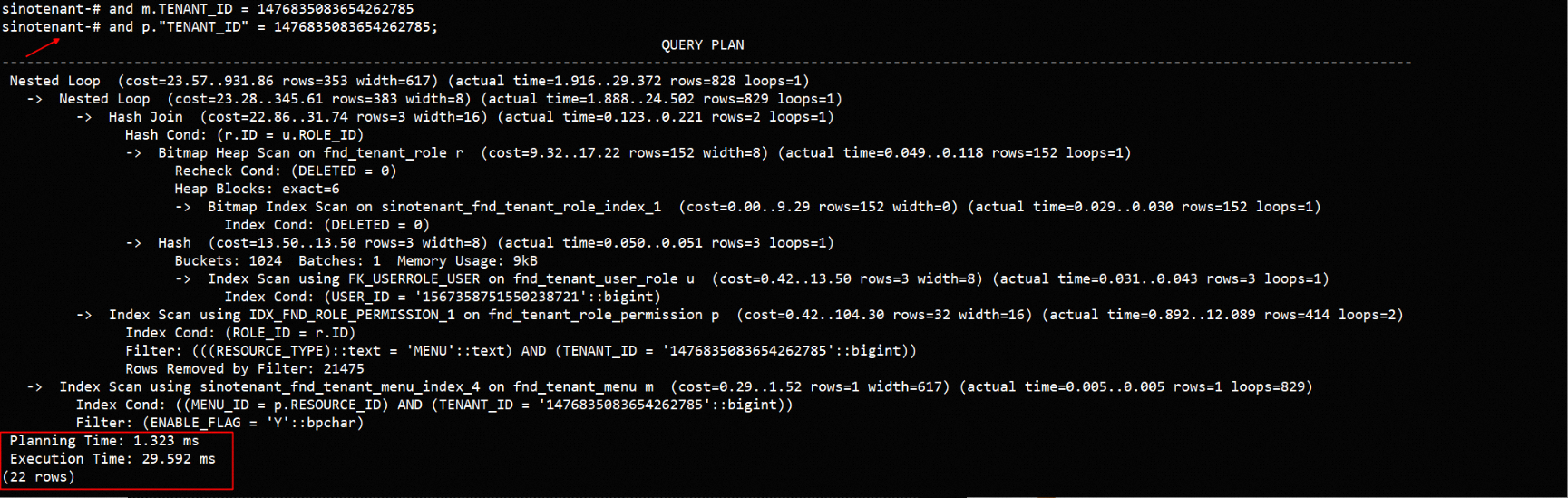
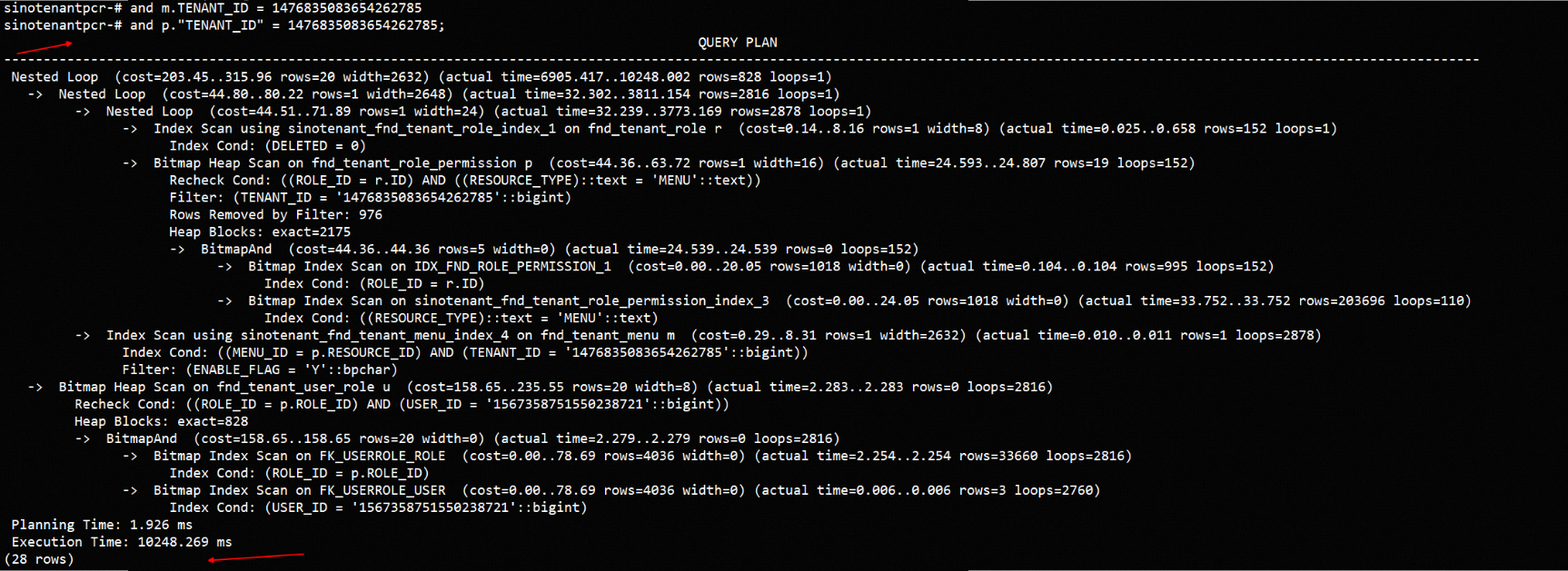
语句都是这个
select
m.ID,
m.MENU_ID,
m."CODE",
m.TITLE,
m.TOOLTIP,
m.POPUP_FLAG,
m.IS_FRONT_END,
m.REPORT_FLAG,
m.DISPLAY_ORDER,
m.URL,
m.ICON_CLASS,
m.PARENT_ID
from
fnd_tenant_menu m,
fnd_tenant_role_permission p,
fnd_tenant_role r,
fnd_tenant_user_role u
where
u.USER_ID = 1567358751550238721
and m.MENU_ID = p.RESOURCE_ID
and p.ROLE_ID = r.ID
and r.ID = u.ROLE_ID
and m.ENABLE_FLAG = 'Y'
and p.RESOURCE_TYPE = 'MENU'
and r.DELETED = 0
and m.TENANT_ID = 1476835083654262785
and p."TENANT_ID" = 1476835083654262785;复制 我来答
添加附件
收藏
分享
问题补充
1条回答
默认
最新
 评论
评论
回答交流
Markdown
请输入正文
提交
相关推荐
PG原生的流复制支持异步、同步、Quorum Base的机制来同步WAL日志。这三种复制方式有什么区别?
回答 1
首先是同步复制,同步复制的首要目标是保证不丢数据,但其实它会有一些问题,第一个问题是它无法满足可用性的要求,当备库出现故障的时候,或者网络链路上有抖动的时候,这个时候可能会影响主库的可用性,或者主库的
SQL 执行计划管理中的执行计划通常有哪三个状态?
回答 1
SQL执行计划管理中的执行计划通常有三个状态——新生成(New)、已接受(Accepted)和已验证(Verified)
HTAP 架构有几个优化器?
回答 1
HTAP架构内置了两个优化器,其一为传统内置优化器,用于处理单机查询。其二为GPORCA优化器,用于处理分布式查询。执行器层引入了大量算子。除了单机执行引擎所需要的算子之外,还需要对以上算子做并行化改
PolarDB的docker启动dn后登不进去有人遇到过吗?
回答 1
是的,有些用户在使用PolardDB的Docker启动数据库节点(DN)后登录遇到了问题。以下是一些常见原因和解决方法:网络配置:确保你的网络配置正确,包括正确的端口映射和防火墙设置。PolardDB
Backend 访问数据块时,读取数据的流程是什么?
回答 1
Backend访问数据块时,读取数据的流程如下:首先,将进程要访问的数据块标记发送给管理器,并由管理器负责寻找当前哪个ID存在可用空间。然后管理器将找到的Bufferid发送给用户进程并记录到描述层,
在云上买了个polardb-x 2.0来测试的。但是用了DRDS模式的语法直接报错了,为什么?
回答 1
这个是标准版的,需要买企业版才有分布式的功能
PolarDB-X怎么创建主从节点
回答 1
PolarDBX是分布式数据库,实例下可以挂载多个多个节点,对应的节点如果这边购买的RDS是单机版,那么这个节点就是单机实例,如果购买的是高可用版的节点,那么这个就是主从节点。
请问PolarDB可以和自建MySQL搭建主从吗?
回答 2
是不支持的,原因如下:1、目前PolarDB数据库是主备HA架构,不开放数据库文件的配置信息及权限给客户端。2、当主库发生异常的时候,从库会在30秒内进行切换,成为主库,这时会导致serverid发生
PolarDB迁移到PolarDB-X报错Unsupported SQL kind: IDENTIFIER not support yet
回答 1
PolarDB迁移到PolarDBX报错UnsupportedSQLkind:IDENTIFIERnotsupportyet。原因是使用的SQL语法或者功能PolarDBX尚不支持。建议手动将存储过程
polardb 在云下用的多吗
回答 1
你说的是哪个?polardb有mysql,pg和oracle兼容三个版本,只有pg是开源的。

