

2024-01-14
greenplum节点宕机,pg_stat_activity卡了一堆进程杀不掉
背景:sdw11primary宕机,目前已执行恢复命令,在同步xlog。
pg_stat_activity从13号晚上23点卡到第二天,一堆进程select pg_terminate_backend(pid int);杀不掉。
早上8点多另一个节点sdw12上的primary报超出内存也挂了。
目前问题:1.卡的那一堆进程如何杀掉?
2.是否可以开始sdw12的恢复?
现有情况:1.目前卡住的进程通过查询进程句柄发现都在master节点上。

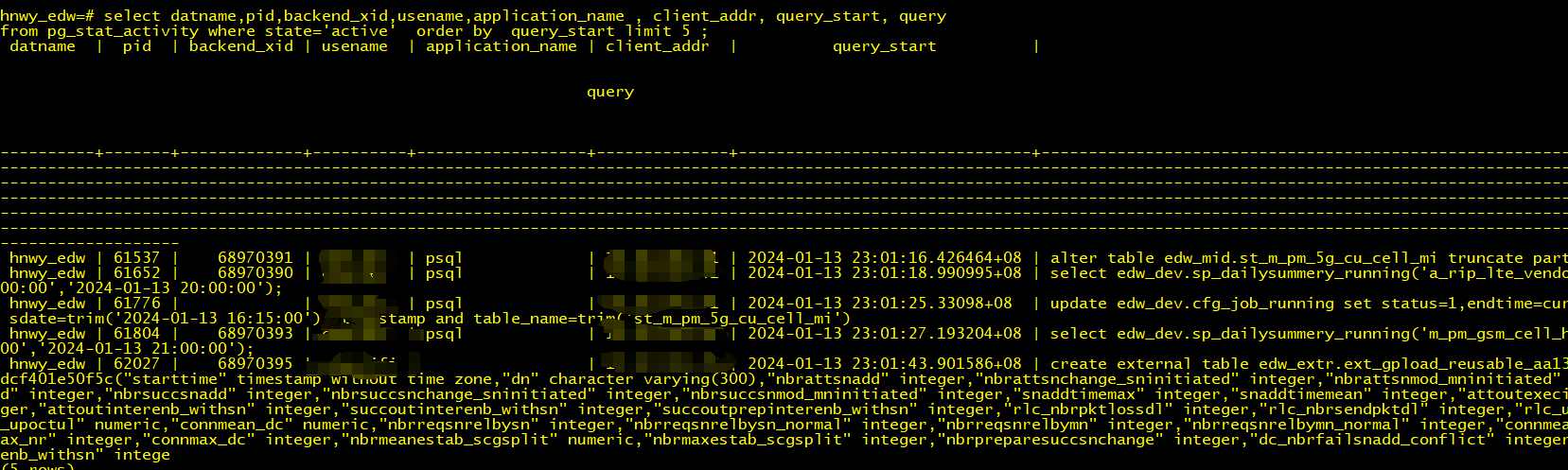
2.卡住无法杀掉的进程截图:
我来答
添加附件
收藏
分享
问题补充
4条回答
默认
最新

 评论
评论

回答交流
Markdown
请输入正文
提交
问题信息
请登录之后查看
邀请回答
暂无人订阅该标签,敬请期待~~
 墨值悬赏
墨值悬赏