今天同事归档sqlserver数据库的数据时遇到一个很有意思的案例:
数据库类型:Sql Server 2008R2、Sql Server2016
ID字段类型:PK(聚集索引),bigint
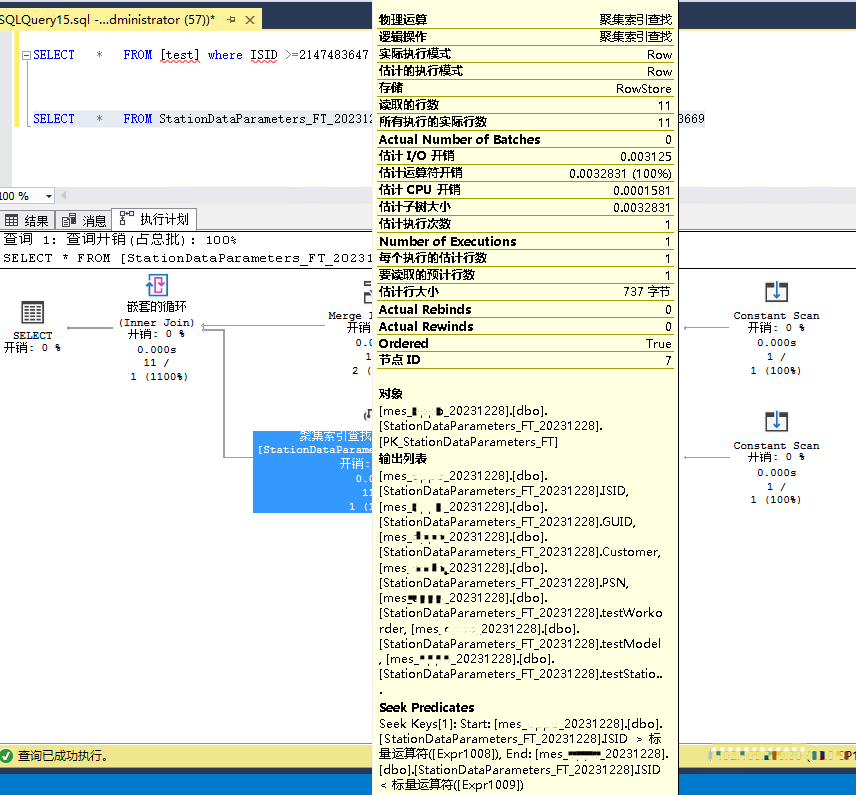
有个表存了几十亿行数据,今天给这个表做归档,大概语句insert into XXX SELECT ... from table where id>=XXX and id<XXX,前二十亿的归档都很顺利,直到在归档id范围包含2147483647这个数值时,出现了超时,然后一点点缩减范围排查。
测试结果如下:
1、SELECT id from table where id>2147483646 and id<2147483648; --查询超时,IO飙升
2、SELECT id from table where id>=2147483647 and id<2147483648; --查询超时,IO飙升
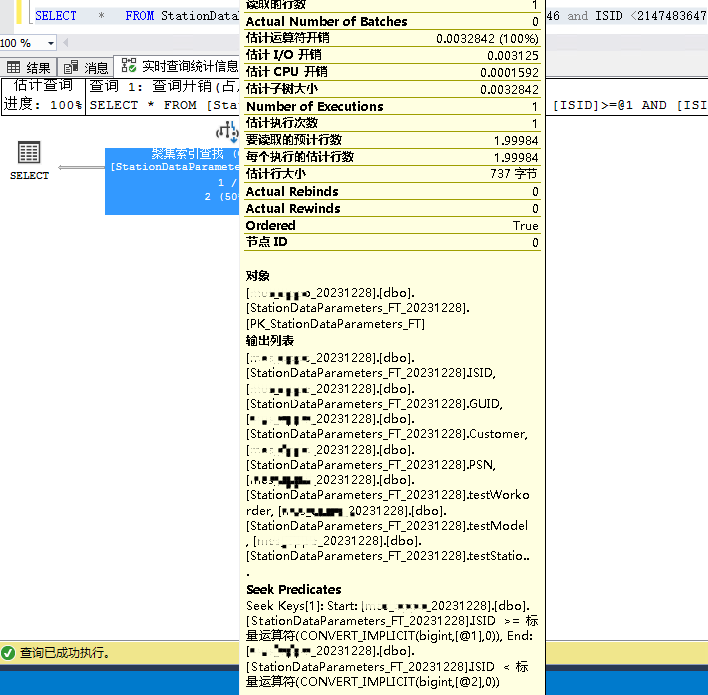
3、SELECT id from table where id>=2147483646 and id<2147483647; --结果集秒出
4、SELECT id from table where id>=2147483648 and id<2147483649; --结果集秒出
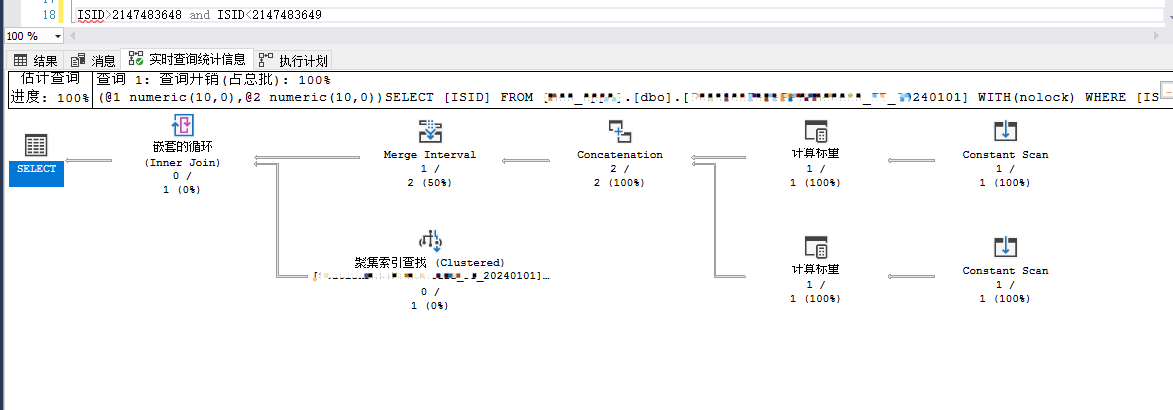
5、SELECT id from table where id>='2147483647' and id<'2147483648'; --结果集秒出
6、SELECT id from table where id>=CAST(2147483647 AS BIGINT) and id<CAST(2147483648 AS BIGINT); --结果集秒出
7、SELECT id from table where id=2147483647; --结果集秒出
第3、4条语句的执行计划不同,也就是说2147483647这个值前后的执行计划不一样。
最后创建相同表结构的测试表,并插入了几千行数据(包含了2147483647这个数前后的数据),查询结果集秒出,看起来必须大数据量才能复现。
分别在sqlserver2008和2016版本的生产库上都复现了。



 评论
评论