




目录
产品简介
Apache Pinot是一个用Java编写的面向列的开源分布式数据 存储。Pinot 旨在以低延迟执行 OLAP 查询。它适用于需要对不可变数据进行快速分析(例如聚合)的环境,可能需要实时数据摄取。
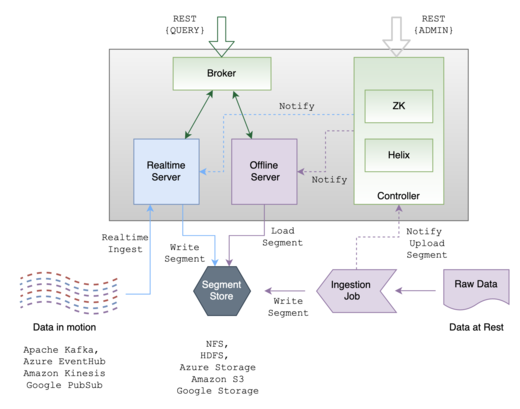
Pinot 将表划分为段,这些段是一组不可变的元组。每个段内的元组以柱状方式组织。段是 Pinot 的基本单位。在服务器节点中,来自 Kafka 和 Hadoop / HDFS 的数据被处理和缓存为段。它们为它们的元组存储元数据、索引和必要的区域映射。每个段内都应用了存储优化;为每个段建立索引。查询计划和优化也是按段生成和执行的。
Pinot 的内部构建块是 Apache Helix。它用于管理集群,例如副本和冗余节点。Pinot 还依赖两个外部组件Zookeeper和对象存储来为全局元数据和数据库提供持久存储。
产品特点
-速度快
Pinot 旨在以低延迟回答不可变数据和可变数据的 OLAP 查询(Upsert 支持)
- 可插拔索引
可插拔索引技术 - 排序索引、位图索引、倒排索引、星树索引、布隆过滤器、范围索引、文本搜索索引(Lucence/FST)、Json 索引、地理空间索引 - 近实时摄取
使用Apache Kafka、Apache Pulsar、Kinesis支持JSON、Avro、ProtoBuf、Thrift格式的近实时摄取 - 水平可扩展
水平可扩展和容错 - 使用 Trino 或 PrestoDB 连接
目前不支持连接,但是可以通过使用Trino或PrestoDB进行查询来克服这个问题 - 类 SQL 查询接口 (PQL)
支持对数据进行选择、聚合、过滤、分组、排序、不同查询的类似 SQL 的语言 - 混合表
由离线表和实时表组成。仅使用实时表覆盖可能尚无离线数据的段 - 异常检测
运行 ML 算法以检测 Pinot 中存储的数据的异常情况。使用ThirdEye和 Pinot 进行异常检测和根本原因分析 - ThirdEye 中的智能警报
通过自定义异常检测流和通知流来检测正确的异常
产品历史
Pinot 于 2014 年首次由 LinkedIn 开发,作为内部分析基础设施。它源于对 OLAP 系统进行横向扩展以支持对海量数据的低延迟实时查询的需求。后来在 2015 年开源,2018 年进入 Apache 孵化器。
用户评价
0
0
词条统计
创建者:小芳
编辑次数:1
浏览次数:2597
API调用次数:0
贡献者
