




虽然表和索引是最重要和最常用的模式对象,但数据库支持许多其他类型的模式对象,其中最常见的将在本章中讨论。
分区概述
在Oracle数据库中,分区使你能够将非常大的表和索引分解成更小、更易于管理的叫做分区的片断。每个分区是一个独立的对象,具有其自己的名称和 (可选的)的存储特征。
为说明分区,打个比方,假设一个人事经理有一只大箱子,其中包含雇员的文件夹。每个文件夹列出了雇员的雇用日期。经常会查询在一个特定月份雇用的雇员。要满足这些要求的一种方法是,对雇员的雇佣日期创建索引,它指向分散在箱子中的这些文件夹的位置。相比之下,分区策略将使用许多更小的箱子,每个小箱子仅包括在一个给定月份内雇用的雇员的文件夹。
使用更小的箱子具有几个优势。当要检索在 6 月份雇用的员工的文件夹时,人事经理只需检索 6 月份的箱子。此外,如果任何小箱子损坏,则并不影响其他小箱子保持可用。办公室搬家也会变得更容易,因为他不必移动一个很大的箱子,而只需移动几个小箱子。
从应用程序的角度来看,只有一个模式对象已存在。DML 语句不需要作任何修改就可以访问该分区表。分区对许多不同类型的应用程序都很有用,特别是那些管理大量数据的应用程序。其好处包括:
- 可用性增强
其中某个分区不可用并不意味着整个对象不可用。当部分分区不可用时,查询优化器自动从查询计划中删除未引用的分区,而查询不会受影响。 - 更轻松的管理模式对象
已分区对象具有多个分片,可以将其作为一个整体来管理,也可以单独管理各个分片。DDL 语句可以处理分区,而不是整个表或索引。因此,您可以分解大量占用资源的任务,如重建索引或表。例如,您可以一次只移动一个表分区。如果发生了问题,则只需重新移动该分区,而不是整个表。而且,删除一个分区可以避免执行许多 DELETE语句。 - 在 OLTP 系统中减少对共享资源的争用
在一些 OLTP 系统中,分区可以减少对共享资源的争用。例如,DML 被分散到很多段,而不只是一个段。 - 在数据仓库中增强的查询性能
在数据仓库中,分区可以加快处理即席查询。例如,包含一百万行的销售表可以按季度进行分区。
分区特征
每个表或索引的分区必须具有相同的逻辑属性,如列名称、数据类型和约束。
例如,在一个表中的所有分区都共享相同的列和约束定义,并在索引中的所有分区都共享相同的索引列。但是,每个分区可以有单独的物理属性,如其所属的表空间。
分区键
分区键是一个列或列集,以确定分区表中的每一行应该所在的分区。每个行会被确定地(而不是模棱两可地) 分配到某个分区。
在 sales 表中,您可以指定 time_id 列作为范围分区的键。基于此列中的日期是否属于某一特定范围,数据库将行分配到所属分区。通过使用分区键,Oracle 数据库将插入、更新、和删除操作自动地指向适当的分区。
分区策略
Oracle 分区提供了几个分区策略,来控制数据库如何将数据放置到分区。基本策略有范围分区、列表分区和哈希分区等。
单一分区只使用一种数据分布方法,例如,仅使用列表分区,或仅使用范围分区。在复合分区中,表先按一种数据分布方法分区,然后每个分区使用第二种数据分布方法进一步分成子分区。例如,您可以使用 channel_id划分列表分区,并使用 time_id 划分范围子分区。
例 4-1 分区表的示例行集
这个分区示例假设您希望用以下行填充分区表 sales:
PROD_ID CUST_ID TIME_ID CHANNEL_ID PROMO_ID QUANTITY_SOLD AMOUNT_SOLD ---------- ---------- --------- ---------- ---------- ------------- ----------- 116 11393 05-JUN-99 2 999 1 12.18 40 100530 30-NOV-98 9 33 1 44.99 118 133 06-JUN-01 2 999 1 17.12 133 9450 01-DEC-00 2 999 1 31.28 36 4523 27-JAN-99 3 999 1 53.89 125 9417 04-FEB-98 3 999 1 16.86 30 170 23-FEB-01 2 999 1 8.8 24 11899 26-JUN-99 4 999 1 43.04 35 2606 17-FEB-00 3 999 1 54.94 45 9491 28-AUG-98 4 350 1 47.45复制
范围分区
在范围分区中,数据库基于分区键的值范围将行映射到各个分区。范围分区是最常见的分区类型,通常与日期一起使用。
假设你使用如下语句创建分区表 time_range_sales,time_id 列是分区键:
CREATE TABLE time_range_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
(PARTITION SALES_1998 VALUES LESS THAN (TO_DATE('01-JAN-1999','DD-MON-YYYY')),
PARTITION SALES_1999 VALUES LESS THAN (TO_DATE('01-JAN-2000','DD-MON-YYYY')),
PARTITION SALES_2000 VALUES LESS THAN (TO_DATE('01-JAN-2001','DD-MON-YYYY')),
PARTITION SALES_2001 VALUES LESS THAN (MAXVALUE)
);
复制然后,您可以将示例 4-1 中的示例行加载到 time_range_sales 表。这段代码显示了四个分区中的行分布。数据库根据 PARTITION BY RANGE 子句中指定的规则,基于 time_id 值为每个行选择适当的分区。范围分区键值确定指定分区的非包容性上限。
间隔分区
间隔分区是范围分区的扩展。
如果插入的数据超过现有的范围分区,那么Oracle数据库将自动创建指定间隔的分区。例如,您可以创建一个销售历史表,它将每个月的数据存储在一个单独的分区中。
间隔分区使您能够避免显式地创建范围分区。您几乎可以对每个范围分区的表使用区间分区,并对新分区使用固定的区间。除非您使用不同的间隔创建范围分区,或者总是设置特定的分区属性,否则请考虑使用间隔分区。
在按区间进行分区时,必须指定至少一个范围分区。范围分区键值确定各个范围分区的高值,被称为跃点。数据库会自动为数据创建具有跃点之外的值的区间分区。每个区间划分的下边界是上一个区间划分或区间划分的包容上边界。因此,在例 4-2 中,值 01-JAN-2011 位于分区 p2 中。
数据库为超出跃点的数据创建间隔分区。当插入到表中的数据超出所有已定义的表分区时,间隔分区指示数据库自动创建特定范围或特定间隔的分区。在例 4-2中,分区 p3 包含分区键 time_id 值大于或等于 01-JAN-2013 的行。
例 4-2 间隔分区
假设您创建了一个sales表,其中有四个宽度不同的分区。您指定在2013年1月1日的产品点之上,数据库应该以一个月为间隔创建分区。分区p3的上限表示跃点。分区p3和它下面的所有分区都在范围部分,而它上面的所有分区都在区间部分。
CREATE TABLE interval_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
INTERVAL(NUMTOYMINTERVAL(1, 'MONTH'))
( PARTITION p0 VALUES LESS THAN (TO_DATE('1-1-2010', 'DD-MM-YYYY'))
, PARTITION p1 VALUES LESS THAN (TO_DATE('1-1-2011', 'DD-MM-YYYY'))
, PARTITION p2 VALUES LESS THAN (TO_DATE('1-7-2012', 'DD-MM-YYYY'))
, PARTITION p3 VALUES LESS THAN (TO_DATE('1-1-2013', 'DD-MM-YYYY')) );
复制您插入2014年10月10日的一个销售:
SQL> INSERT INTO interval_sales VALUES (39,7602,'10-OCT-14',9,null,1,11.79);
1 row created.
复制USER_TAB_PARTITIONS 的查询显示,数据库为 10 月 10 日的销售创建了一个新分区,因为销售日期晚于跃点:
SQL> COL PNAME FORMAT a9
SQL> COL HIGH_VALUE FORMAT a40
SQL> SELECT PARTITION_NAME AS PNAME, HIGH_VALUE
2 FROM USER_TAB_PARTITIONS WHERE TABLE_NAME = 'INTERVAL_SALES';
PNAME HIGH_VALUE
--------- ----------------------------------------
P0 TO_DATE(' 2007-01-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
P1 TO_DATE(' 2008-01-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
P2 TO_DATE(' 2009-07-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
P3 TO_DATE(' 2010-01-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1598 TO_DATE(' 2014-11-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
复制列表分区
在列表分区中,数据库使用一些具体值的列表作为每个分区的分区键。分区键由一个或多个列组成。
你可以使用列表分区来控制单个行如何映射到特定的分区。当用来区分数据集的键不方便排序时,可以通过使用列表来分组和组织相关的数据集。
例 4-3 列表分区
假设您使用下面的语句创建列表分区表 list_sales。channel_id 列为分区键:
CREATE TABLE list_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY LIST (channel_id)
( PARTITION even_channels VALUES ('2','4'),
PARTITION odd_channels VALUES ('3','9')
);
复制随后,将示例 4-1 中的表行加载到表中。这段代码显示了在两个分区中的行分。数据库根据 PARTITION BY LIST 子句中指定的规则,基于channel_id 为每个行选择适当的分区。channel_id 值为 2 或 4 的行存储在 EVEN_CHANNELS 分区中,而 channel_id 值 为 3 或 9 的行存储在ODD_CHANNELS 分区中。
哈希分区
在哈希分区中,基于用户所指定的将在分区键上应用的哈希算法,数据库将行映射到各个分区。
行的目标分区是由数据库应用于行的内部哈希函数所决定的。当分区数量为2的幂时,哈希算法在所有分区之间创建大致均匀的行分布。
哈希分区可用于划分大表,以提高可管理性。你只需管理几个较小的表片断,而不是管理一个大型表。一个哈希分区的缺失并不影响其余分区,并且可以独立地恢复。在更新争用较高的 OLTP 系统中,哈希分区也是非常有用的。例如,一个段被分为几个片断,每个片断都可以被更新,而不像单个段那样会遭受争用。
假定您使用下面的语句创建 hash_sales 分区表。prod_id 列为分区键:
CREATE TABLE hash_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY HASH (prod_id)
PARTITIONS 2;
复制随后,将示例 4-1 中的表行加载到表中。这段代码显示两个分区中可能的行分布。请注意这些分区的名称是系统自动生成的。
当您插入行时,数据库会尝试随机、均匀地将它们分布在各个分区之间。您不能指定某行被放置在哪一个分区。数据库应用哈希函数,其结果确定由哪个分区包含此行。
引用分区
在引用分区中,子表的分区策略仅通过与父表的外键关系定义。对于父表中的每个分区,子表中恰好存在一个对应的分区。父表将父记录存储在特定的分区中,子表将子记录存储在相应的分区中。
例如,orders 表是 line_items 表的父表,在 order_id 上定义了主键和外键。表是按引用分区的。例如,如果数据库在 orders 的分区 Q3_2015 中存储订单 233,那么数据库在 line_items 的分区 Q3_2015 中存储订单 233 的所有行项。如果将分区 Q4_2015 添加到 orders 中,那么数据库将自动将 Q4_2015 添加到 line_items 中。
引用分区的优点是:
- 通过对父表和子表使用相同的分区策略,可以避免在所有分区键列重复。这种策略减少了反规范化的人工开销,并节省了空间。
- 父表上的维护操作将自动在子表上进行。例如,当您向主表添加分区时,数据库会自动将此添加传播到它的后代。
- 数据库自动使用父表和子表中的分区连接,从而提高了性能。
可以使用包括引用分区在内的所有基本分区策略来使用引用分区。还可以创建引用分区表作为复合分区表。
例 4-4 创建引用分区表
这个例子创建了一个父表 orders,它在 order_date 上对范围进行分区。使用 Q1_2015、Q2_2015、Q3_2015 和 Q4_2015 这四个分区创建引用分区的子表 order_items,其中每个分区包含与各自父分区中的订单对应的 order_items 行。
CREATE TABLE orders
( order_id NUMBER(12),
order_date DATE,
order_mode VARCHAR2(8),
customer_id NUMBER(6),
order_status NUMBER(2),
order_total NUMBER(8,2),
sales_rep_id NUMBER(6),
promotion_id NUMBER(6),
CONSTRAINT orders_pk PRIMARY KEY(order_id)
)
PARTITION BY RANGE(order_date)
( PARTITION Q1_2015 VALUES LESS THAN (TO_DATE('01-APR-2015','DD-MON-YYYY')),
PARTITION Q2_2015 VALUES LESS THAN (TO_DATE('01-JUL-2015','DD-MON-YYYY')),
PARTITION Q3_2015 VALUES LESS THAN (TO_DATE('01-OCT-2015','DD-MON-YYYY')),
PARTITION Q4_2015 VALUES LESS THAN (TO_DATE('01-JAN-2006','DD-MON-YYYY'))
);
CREATE TABLE order_items
( order_id NUMBER(12) NOT NULL,
line_item_id NUMBER(3) NOT NULL,
product_id NUMBER(6) NOT NULL,
unit_price NUMBER(8,2),
quantity NUMBER(8),
CONSTRAINT order_items_fk
FOREIGN KEY(order_id) REFERENCES orders(order_id)
)
PARTITION BY REFERENCE(order_items_fk);
复制复合分区
在复合分区中,用一种数据分布方法对表进行分区,然后使用另一种数据分布方法将每个分区进一步细分为子分区。因此,组合分区结合了基本的数据分布方法。给定分区的所有子分区都表示数据的逻辑子集。
复合分区提供了以下几个优点:
- 根据 SQL 语句,对一个或两个维度进行分区修剪可能会提高性能。
- 查询可以在任意维度上使用全分区连接或部分分区连接。
- 可以对单个表执行并行备份和恢复。
- 分区的数量大于单级分区,这可能有利于并行执行。
- 如果许多语句可以从分区修剪或分区连接中获益,那么您可以实现一个滚动窗口来支持历史数据,并且仍然在另一个维度上进行分区。
- 您可以根据分区键的标识以不同的方式存储数据。例如,您可能决定以只读、压缩格式存储特定产品类型的数据,并保持其他产品类型的数据未压缩。
区间、列表和散列分区可以作为复合分区表的子分区策略。下图提供了范围-散列和范围-列表复合分区的图形化视图。
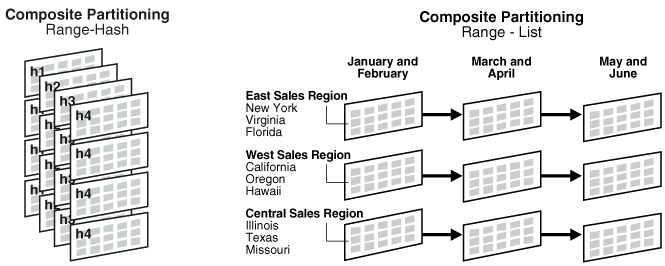
数据库将复合分区表中的每个子分区存储为单独的段。因此,子分区属性可能与表的属性不同,也可能与子分区所属的分区不同。
分区表
分区表包含一个或多个分区,它们可以单独进行管理,并且可以独立于其他分区进行操作。
表要么是分区表,要么是未分区表。即使分区表只包含一个分区,此表也是与一个未分区表不同的,不能将分区加入到未分区表中。
表分区段
分区表由一个或多个表分区段组成。
如果您创建了一个名为 hash_products的分区表,但并没有为此表分配表段。相反,数据库将每个表分区的数据存储在其自己的分区段中。每个表分区段包含表数据的一部分。
当对外部表进行分区时,所有分区都驻留在数据库之外。在混合分区表中,一些分区存储在段中,而其他分区存储在外部。例如,sales表的一些分区可能存储在数据文件中,其他分区存储在电子表格中。
压缩分区表
堆组织表中的某些分区或所有分区可以存储为压缩格式。
压缩可以节省空间,并可以加快执行查询的速度。因此,压缩可用于在插入和更新操作很少的数据仓库环境中,也可以用于 OLTP 环境中。
可以为表空间、表、或表分区声明表压缩属性。如果在表空间级别声明,则默认情况下在该表空间中创建的表是被压缩的。您可以更改一个表的压缩属性,在这种情况下,此更改仅适用于插入到该表的新数据。因此,一个单表或分区可能包含压缩和未压缩的块,它保证数据的大小不会因为压缩反而增大。如果压缩会增加一个数据块的大小,那么数据库就不压缩该块。
分区索引
与分区表类似,分区索引被分解成更小、更易于管理的索引片断。
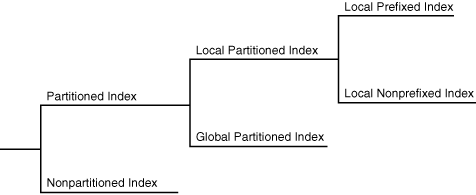
全局索引独立于它们依赖的表进行分区; 而局部索引则依据不同的表分区方法,自动链接到相应的表分区。与分区表类似,分区索引提高了可管理性、可用性、性能、和可扩展性。
下图显示索引的分区选项。
局部分区索引
在局部分区索引中,索引基于表上相同的列来分区,与表分区具有相同分区数目和相同的分区边界。
每个索引分区仅与底层表的一个分区相关联,所以一个索引分区中的所有键都只引用存储在某个单一表分区中的行。通过这种方式,数据库会自动同步索引分区及其关联的表分区,使每个表-索引对相持独立。
局部分区索引在数据仓库环境中很常见。局部索引提供了以下优点:
- 因为使分区中的数据无效或不可用的操作只会影响当前分区,这有助于提高可用性。
- 简化了分区维护。当移动一个表分区,或某个分区的数据老化时,只须重建或维持相关联的局部索引分区。而在全局索引中所有索引分区必须被全部重建或维护。
- 如果分区发生时间点恢复,则可以将局部索引恢复到恢复时间(请参阅“Data File Recovery”)。而不需要重建整个索引。
这个 Hash 分区的例子显示了使用 prod_id 列作为分区键的 hash_sales 分区表的创建语句。示例 4-5 在 hash_sales 表的 time_id 列上创建一个局部分区索引:
CREATE INDEX hash_sales_idx ON hash_sales(time_id) LOCAL;
复制在图 4-3 中,hash_products 表中有两个分区,因此 hash_sales_idx 也有两个分区。每个索引分区与一个不同的表分区相关联。索引分区 SYS_P38对表分区 SYS_P33 中的行建立索引,而索引分区 SYS_P39 对表分区SYS_P34 中的行建立索引。
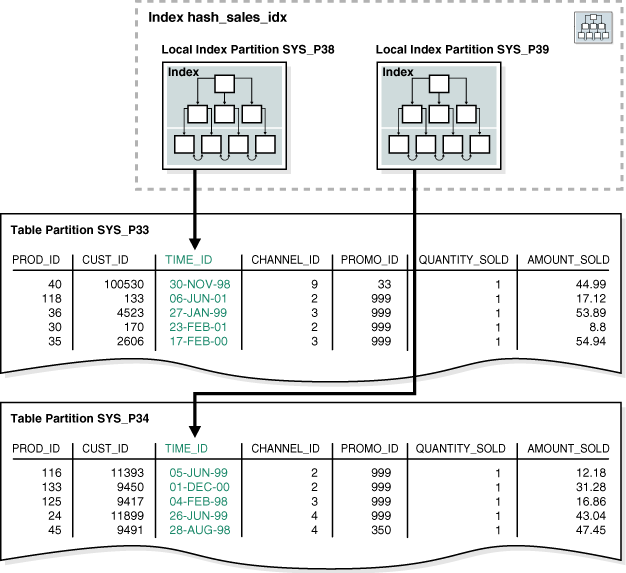
你不能明确将一个分区添加到一个局部索引中。相反,仅当您将一个表分区添加到基础表时,新的索引分区会被自动添加到局部索引。同样,不能明确从局部索引删除一个分区。相反,仅当你从基础表中删除一个表分区时,相应的局部索引分区会被自动删除。
与其他索引一样,您可以在分区表上创建位图索引。唯一的限制是位图索引必须是局部分区索引 — — 而不能是全局分区索引。全局位图索引只支持非分区表。
局部前缀索引和局部非前缀索引
本地分区索引可以带前缀,也可以不带前缀。
索引子类型定义如下:
- 局部前缀索引
在这种情况下,分区键处于索引定义的前导部分。在范围分区的time_range_sales示例中,该表在 time_id 上按范围分区。此表上的局部前缀索引会以 time_id 作为其索引列列表中的第一列。 - 局部非前缀索引
在这种情况下,分区键不是索引列列表的前导部分,甚至根本不必在该列表中。在本地分区索引的hash_sales_idx示例中,由于分区键 product_id 不属于前导列,所以该索引是局部非前缀索引。
这两种类型的索引都可以充分利用分区消除 (也称为分区剪除) ,此时,优化程序将不予考虑无关分区,以加快数据访问速度。查询是否可以消除分区取决于查询谓词。使用局部前缀索引的查询始终允许索引分区消除,而使用一个局部非前缀索引的查询可能不会。
局部分区索引存储
与表分区类似,局部索引分区被存储在其自己的段中。每个段包含整个索引数据的一部分。因此,由四个分区组成的局部索引,不是存储在一个单一索引段中,而是在四个单独的段中。
全局分区索引
全局分区索引是一个 B-树索引,其分区独立于所依赖的基础表。某个索引分区可以指向任意或所有的表分区,而在一个局部分区索引中,索引分区与分区表之间却存在一对一的配对关系。
通常,对于强调快速访问、数据完整性、和可用性的 OLTP 应用程序来说,全局索引很有用。在一个 OLTP 系统中,表可能会基于某个键(如employees.department_id 列)来分区,但应用程序可能需要基于许多不同的键(如 employee_id 或 job_id) 来访问数据。全局索引在这种情况下可能很有用。
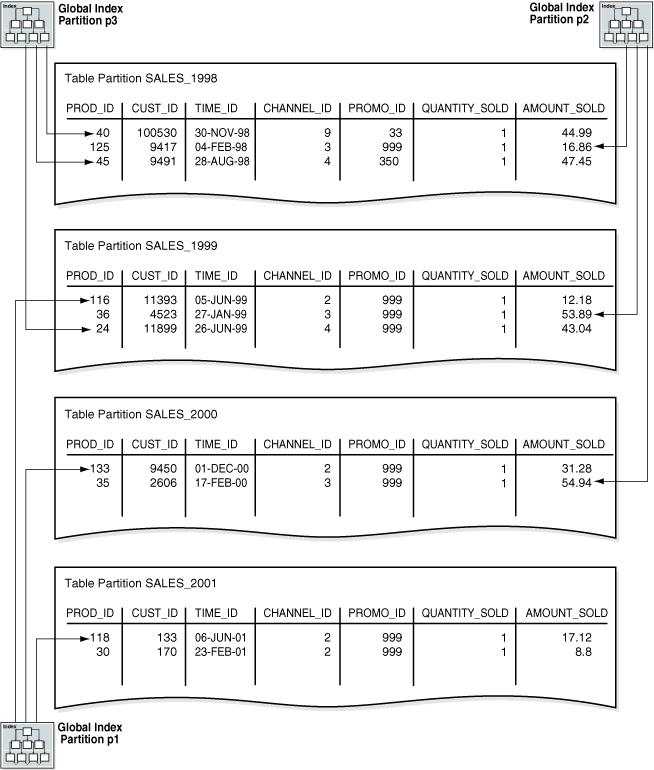
作为演示,假设您在范围分区中的 time_range_sales 表上创建全局分区索引。在该表中,1998 年销售的行存储在一个分区中,1999 年销售的行在另一个分区中,如此等等。下面的例子在 channel_id 列上按范围创建了一个全局分区索引:
CREATE INDEX time_channel_sales_idx ON time_range_sales (channel_id)
GLOBAL PARTITION BY RANGE (channel_id)
(PARTITION p1 VALUES LESS THAN (3),
PARTITION p2 VALUES LESS THAN (4),
PARTITION p3 VALUES LESS THAN (MAXVALUE));
复制如图 4-4,全局索引分区可以包含指向多个表分区的条目。索引分区 p1 指向 channel_id 为 2 的行,索引分区 p2 指向 channel_id 为 3 的行,而索引分区 p3 指向 channel_id 为 4 或 9 的行。
分区表的部分索引
部分索引是与关联分区表的索引属性相关的索引。
相关性使您能够指定索引哪些表分区。部分索引具有以下优点:
- 没有索引的表分区避免使用不必要的索引存储空间。
- 负载和查询的性能可以得到改善。
在 Oracle Database 12c 之前,exchange 分区操作需要对关联的全局索引进行物理更新,以保持其可用性。从Oracle Database 12c 开始,如果分区维护操作中涉及的分区不是局部全局索引的一部分,那么该索引仍然可用,不需要任何全局索引维护。 - 如果在创建索引时只索引一些表分区,如果以后索引其他分区,那么可以减少创建索引所需的排序空间。
可以为表的各个分区打开或关闭索引。局部索引不为所有索引关闭的表分区提供可用的索引分区。全局索引(无论是否分区)将数据排除在所有索引关闭的分区之外。对于强制执行惟一约束的索引,数据库不支持局部索引。
图4-5显示了与图4-4中相同的全局索引,只是全局索引是局部的。表分区 SALES_1998和SALES_2000的索引属性设置为OFF,因此局部全局索引不会索引它们。

分片表概述
在 Oracle 数据库中,分片使您能够将一个大表分解为更易于管理的称为分片的片段,这些片段可以存储在多个数据库中。
每个数据库都驻留在专用服务器上,具有自己的本地资源—CPU、内存、flash或磁盘。这种配置中的每个数据库都称为分片。所有这些分片组成一个逻辑数据库,称为分片数据库(SDB)。
水平分区涉及跨分片数据库表,以便每个分片包含具有相同列但行子集不同的表。以这种方式分割的表也称为分片表。
下图显示了一个跨三个切分水平分区的表。
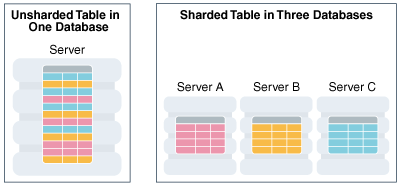
分片基于无共享硬件基础设施,它消除了单点故障,因为分片不共享CPU、内存或存储设备等物理资源。分片在软件方面也是松散耦合的;它们不运行集群软件。
分片通常驻留在专用服务器上。这些服务器可以是普通硬件或工程系统。这些分片可以在单个实例或Oracle RAC数据库上运行。它们可以放在本地、云中,也可以放在混合的本地和云配置中。
从数据库管理员的角度来看,SDB 由多个数据库组成,这些数据库可以集体管理,也可以单独管理。然而,从应用程序的角度来看,SDB 看起来像一个单独的数据库:分片的数量和在这些分片之间的数据分布对数据库应用程序是完全透明的。
分片是为适用于分片数据库体系结构的自定义OLTP应用程序设计的。使用分片的应用程序必须具有定义良好的数据模型和数据分布策略(一致的散列、范围、列表或组合),主要使用分片键访问数据。分片键的示例包括customer_id、account_no或country_id。
分片表
分片表是指在多个数据库中被划分为更小、更易于管理的部分的表,称为分片。
Oracle Sharding 是基于 Oracle 数据库分区特性实现的。Oracle Sharding 本质上是分布式分区,因为它支持跨f分片分布表分区,从而扩展了分区。
在表空间级别上,分区基于分片键分布在分片上。密钥的示例包括客户 ID、账号和国家 ID。
sharding 键支持以下数据类型:
- NUMBER
- INTEGER
- SMALLINT
- RAW
- (N)VARCHAR
- (N)VARCHAR2
- (N)CHAR
- DATE
- TIMESTAMP
分片表的每个分区驻留在一个单独的表空间中,每个表空间与一个特定的分片相关联。根据分片方法,可以自动建立关联,也可以由管理员定义关联。
即使分片表的分区位于多个分片中,对于应用程序来说,该表的外观和行为与单个数据库中的分区表完全相同。应用程序发出的SQL语句不必引用分片,也不必依赖于切分的数量及其配置。
例 4-5 分片
熟悉的表分区 SQL 语法指定了应该如何跨分片分区行。例如,下面的 SQL 语句创建了一个分片表,根据分片键 cust_id 水平分区分片表:
CREATE SHARDED TABLE customers
( cust_id NUMBER NOT NULL
, name VARCHAR2(50)
, address VARCHAR2(250)
, region VARCHAR2(20)
, class VARCHAR2(3)
, signup DATE
CONSTRAINT cust_pk PRIMARY KEY(cust_id)
)
PARTITION BY CONSISTENT HASH (cust_id)
PARTITIONS AUTO
TABLESPACE SET ts1
;
复制前面的表是通过一致散列进行分区的,这是可伸缩分布式系统中常用的一种特殊类型的散列分区。这种技术自动地将表空间分散到多个分片中,以提供数据和工作负载的均匀分布。注意,分片表上的全局索引不受支持,但支持本地索引。
表空间集
Oracle 分片以表空间集的形式创建和管理表空间。PARTITIONS AUTO 子句指定应该自动确定分区的数量。这种类型的哈希在分片之间迁移数据时提供了更大的灵活性和效率,这对于弹性可伸缩性非常重要。
表空间是 SDB 中数据分布的逻辑单元。通过在驻留在不同分片上的表空间中自动创建分区,可以实现分区跨分片的分布。为了最小化多分片连接的数量,相关表的相应分区总是存储在同一个分片中。分片表的每个分区存储在单独的表空间中。
视图概述
视图是一个或多个表的逻辑表示形式。视图在本质上是一个存储的查询。
视图的数据来自它所依赖的称为基表的表。基表可以是表或其他视图。在视图上执行的所有操作实际上都影响到基表。在大多数可以使用表的地方,您也可以使用视图。
视图使您能够为不同类型的用户定制数据表示形式。视图通常用于:
- 通过限制对一组预定义的表行或表列的访问,提供一个额外的表安全级别
例如,图 4-7 显示了 staff 视图如何做到不显示 employees 基表的 salary 列或 commission_pct 列。 - 隐藏数据复杂性
例如,一个单一视图的定义可以包含一个联接,它是多个表中的相关列或行的集合。不过,视图隐藏了一个事实,即此信息实际上来自于几个表。查询还可能会对表的信息执行大量计算。因此,用户可以查询视图,而不用知道如何执行联接或计算。 - 以一个不同于基表的角度来呈现数据
例如,可以重命名视图的列,而不会影响视图所基于的表。 - 隔离应用程序和对基表定义的更改
例如,如果视图的查询定义引用了一个四列表的其中三列,若添加第五列到该表,则视图的定义不会受到影响,并且使用该视图的所有应用程序也不会受到影响。
举一个使用视图的例子,考虑表 hr.employees,它具有多个列和许多行。要允许用户只能查看其中 5 列,或只能查看某些特定的行,您可以创建一个视图,如下所示:
CREATE VIEW staff AS
SELECT employee_id, last_name, job_id, manager_id, department_id
FROM employees;
复制与所有子查询一样,定义视图的查询中不能包含 FOR UPDATE 子句。下图以图形方式显示了 staff 视图。请注意,该视图只显示了基表中的五列。
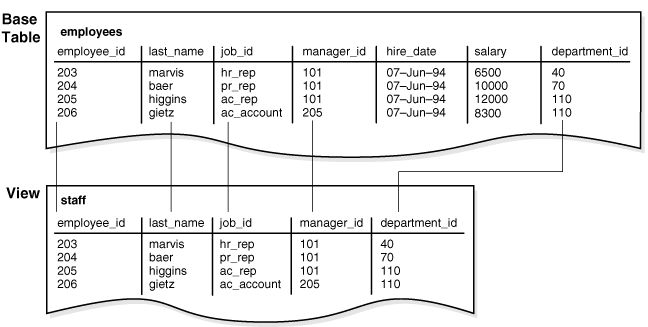
视图特征
与表不同,视图既不分配存储空间,也不包含数据。而是通过定义一个查询,从它所引用的基表中提取或派生出数据。视图基于其他对象,除了只需要在数据字典中存储定义视图的查询,它不需要其他存储。
视图对其所引用的对象存在的依赖关系,由数据库自动处理。例如,如果您删除并重新创建了视图的基表,则数据库会确定新的基表是否仍然适合该视图的定义。
视图中的数据操作
由于视图是从表派生的,所以他们有很多相似之处。用户可以查询视图,在某些限制条件下他们也可以在视图上执行 DML。在视图上执行的操作会影响到视图的基表中的数据,并遵从基表的完整性约束和触发器。
下面的示例创建 hr.employees 表上的一个视图:
CREATE VIEW staff_dept_10 AS
SELECT employee_id, last_name, job_id,
manager_id, department_id
FROM employees
WHERE department_id = 10
WITH CHECK OPTION CONSTRAINT staff_dept_10_cnst;
复制该查询定义只引用了部门 10 中的行。使用 CHECK OPTION 创建的视图具有一个约束,如果对该视图发出的 INSERT 和 UPDATE 语句所生成的新行不符合该视图的选择条件,则该语句将不会成功。因此,行 10 部门的雇员可以插入,但是部门 30 的行不可以。
在视图中,数据是如何访问的
Oracle 数据库将视图定义存储在数据字典中,存的是定义视图查询的文本。
当在 SQL 语句中引用视图时,数据库将执行以下任务:
- (尽可能)将所发出的查询,与定义该视图(或其它任何底层视图)的查询进行合并
Oracle 数据库会优化合并的查询,就好像您发出的查询并没有引用视图一样。因此,数据库可以使用任何被引用基表列上的索引,无论在视图定义中或在针对该视图的用户查询中是否引用了该列。
有时 Oracle 数据库不能将视图定义与用户查询合并。在这种情况下,数据库可能不会使用所有引用列上的索引。 - 在一个共享 SQL 区中,解析合并后的语句
只要还不存在包含相似语句的共享 SQL 区,oracle 数据库就会在一个共享 SQL 区中解析这个引用了视图的语句。因此,视图提供了减少与共享 SQL 相关的内存使用的好处。 - 执行 SQL 语句
下面的示例演示了当查询视图时的数据访问。假设您创建基于 employees 表和 departments 表 employees_view 视图:
CREATE VIEW employees_view AS
SELECT employee_id, last_name, salary, location_id
FROM employees JOIN departments USING (department_id)
WHERE department_id = 10;
复制用户对 employees_view 执行如下的查询:
SELECT last_name
FROM employees_view
WHERE employee_id = 200;
复制Oracle 数据库将视图和用户查询合并,构建如下面的查询,然后执行此查询以检索数据:
SELECT last_name
FROM employees, departments
WHERE employees.department_id = departments.department_id
AND departments.department_id = 10
AND employees.employee_id = 200;
复制可更新联接视图
联接视图被定义为在其 FROM 子句中有多个表或视图的视图。
在下例中,staff_dept_10_30 视图将 employees 表和 departments 表相连接,只包括部门 10 或 30 的雇员。
CREATE VIEW staff_dept_10_30 AS
SELECT employee_id, last_name, job_id, e.department_id
FROM employees e, departments d
WHERE e.department_id IN (10, 30)
AND e.department_id = d.department_id;
复制可更新联接视图,也叫做可修改联接视图,涉及两个或多个基表或视图,并允许 DML 操作。可更新视图在 SELECT 语句的顶层 FROM 子句中包含多个表,并且没有 WITH READ ONLY 子句限制。
要使视图天生就可更新,必须满足几个条件。例如,一般的原则是联接视图上的插入、更新、或删除操作只可一次修改一个基表。如下的对数据字典视图 USER_UPDATABLE_COLUMNS 的查询显示 staff_dept_10_30 视图是可更新的:
SQL> SELECT TABLE_NAME, COLUMN_NAME, UPDATABLE
2 FROM USER_UPDATABLE_COLUMNS
3 WHERE TABLE_NAME = 'STAFF_DEPT_10_30';
TABLE_NAME COLUMN_NAME UPD
------------------------------ ------------------------------ ---
STAFF_DEPT_10_30 EMPLOYEE_ID YES
STAFF_DEPT_10_30 LAST_NAME YES
STAFF_DEPT_10_30 JOB_ID YES
STAFF_DEPT_10_30 DEPARTMENT_ID YES
复制连接视图中的所有可更新列,必须映射到键保留表中的列。联接查询中的键保留表,其基表中的每一行在查询输出中最多出现一次。在示例 4-7 中,department_id 是 departments 表的主键,所以 employees 表中的每一行在结果集中最多出现一次,使得 employees 表是键保留的。而departments 表不是键保留的,因为其每个行可能会在结果集中多次出现。
对象视图
正如一个视图是一个虚拟表,一个对象视图是一个虚拟对象表。在视图中的每一行都是一个对象,对象是某种对象类型的一个实例。对象类型是一种用户定义的数据类型。
您可以检索、更新、插入、和删除关系数据,如同它被存储为一个对象类型。您还可以用对象数据类型的列来定义视图,如对象、REF、和集合(嵌套表和 VARRAYs) 等。
与关系型视图类似,对象视图可以只显示您希望用户看到的数据。例如,一个对象视图可以只呈现 IT 程序员的有关信息,但忽略有关薪水等敏感数据。下面的示例创建一个 employee_type 对象,然后创建基于此对象的视图 it_prog_view:
CREATE TYPE employee_type AS OBJECT
(
employee_id NUMBER (6),
last_name VARCHAR2 (25),
job_id VARCHAR2 (10)
);
/
CREATE VIEW it_prog_view OF employee_type
WITH OBJECT IDENTIFIER (employee_id) AS
SELECT e.employee_id, e.last_name, e.job_id
FROM employees e
WHERE job_id = 'IT_PROG';
复制对象视图在原型程序或向面向对象转换的应用程序中非常有用,因为视图中的数据可以取自关系表,而访问起来好像是一个对象表。您可以运行面向对象的应用程序,而不用将现有表转换为不同的物理结构。
物化视图概述
物化视图是查询结果被提前存储或"物化"的模式对象。在查询的 FROM 子句中可以是命名表、视图、和物化视图。
物化视图通常用作复制中的主表和数据仓库中的事实表。物化视图用于汇总、计算、复制、和分发数据。它们适用于如下各种计算环境:
- 在数据仓库中,可以使用物化视图来计算和存储由聚合函数(如求和或平均值) 所生成的数据。
汇总是一个聚合的视图,它通过预先计算联接和聚合操作,并将结果存储在一个表中,来减少查询时间。物化视图相当于汇总您也可以使用物化视图来计算带或不带聚合的联接。 - 在物化视图复制中,该视图包含从某个表的单一时间点的完整或部分拷贝。物化视图在分布式站点上复制数据,并将在多个站点上执行的更新同步。这种形式的复制适用于如数据库并不始终连接到网络的现场销售环境。
- 在移动的计算环境中,可以使用物化视图将数据子集从中央服务器下载到移动客户端,从中央服务器定期刷新客户端,并定期将客户端更新传输回中央服务器。
在复制环境中,物化视图与一个称为主数据库的不同数据库中的表共享数据。在主站点上与物化视图关联的表是主表。图 4-8 演示了一个数据库中的物化视图,它基于另一个数据库中的主表。对主表的更新被复制到物化视图。
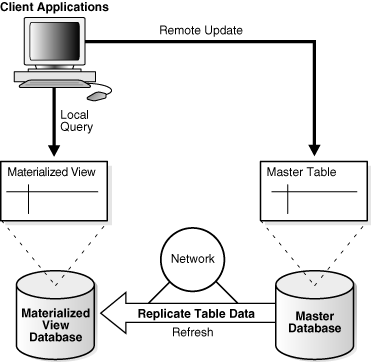
物化视图的特征
物化视图与索引和普通视图具有某些共同特性。
物化视图在以下几方面与索引类似:
- 它们包含实际数据,并且占用存储空间。
- 当其主表中数据更改时,他们可以被刷新。
- 当用于查询重写操作,它们可以提高 SQL 的执行性能。
- 它们的存在对 SQL 应用程序和用户是透明的。
物化视图也类似于非物化视图,因为它也呈现其他的表和视图中的数据。与索引不同的是,用户可以直接使用 SELECT 语句查询物化视图。取决于所需的刷新类型,物化视图也可以用 DML 语句进行更新。
下面的示例创建并填充基于 sh 示例模式中的三个主表的聚合物化视图:
CREATE MATERIALIZED VIEW sales_mv AS
SELECT t.calendar_year, p.prod_id, SUM(s.amount_sold) AS sum_sales
FROM times t, products p, sales s
WHERE t.time_id = s.time_id
AND p.prod_id = s.prod_id
GROUP BY t.calendar_year, p.prod_id;
复制下面的示例删除物化视图 sales_mv 的主表 sales,然后查询 sales_mv。该查询能选出数据,是因为其行数据与主表中的数据是分开存储的。
SQL> DROP TABLE sales;
Table dropped.
SQL> SELECT * FROM sales_mv WHERE ROWNUM < 4;
CALENDAR_YEAR PROD_ID SUM_SALES
------------- ---------- ----------
1998 13 936197.53
1998 26 567533.83
1998 27 107968.24
复制物化视图可以进行分区。您可以在分区表上定义一个物化视图,并可以在该物化视图上创建一个或多个索引。
物化视图的刷新方法
在主表中的数据更改后,数据库通过刷新物化视图来对其进行维护。刷新方法可以是增量刷新,或完全刷新。
完全刷新
完全刷新执行定义物化视图的查询。当您最初创建物化视图时,将发生一次完整的刷新,除非物化视图引用预构建的表,否则将表定义为 BUILD DEFERRED。
一次完整的刷新可能很慢,尤其是在数据库必须读取和处理大量数据的情况下。在创建物化视图之后,您可以在任何时间执行一次完整的刷新。
增量刷新
增量刷新,也称快速刷新,只处理对现有数据的更改。这种方法消除了从一开始重新构建物化视图的需要。只处理更改会导致非常快的刷新时间。
您可以根据需要或定期刷新物化视图。或者,您可以在与基本表相同的数据库中配置物化视图,以便每当事务提交对基本表的更改时进行刷新。
快速刷新有以下两种形式:
- 基于日志刷新
在这种类型的刷新中,物化视图日志或直接加载器日志保存对基本表的更改记录。物化视图日志是一个模式对象,它记录对基表的更改,以便可以增量地刷新在基表上定义的物化视图。每个物化视图日志都与一个基表相关联。 - 分区更改跟踪(PCT)刷新
PCT 刷新仅在分区基本表时有效。PCT 刷新将删除受影响的物化视图分区中的所有数据或数据中受影响的部分,然后重新计算它们。数据库使用修改后的基表分区来标识视图中受影响的分区或数据部分。当基本表上发生分区维护操作时,PCT 刷新是惟一可用的增量刷新方法。
In-Place 和 Out-of-Place 刷新
对于完全刷新和增量刷新,数据库可以刷新 In-Place 的物化视图,就是直接在视图上进行的;或者 Out-of-Place。
out-of-place 刷新创建一个或多个外部表,在这些表上执行刷新语句,然后用外部表切换物化视图或受影响的分区。这种技术在刷新期间实现高可用性,特别是在刷新语句需要很长时间才能完成时。
Oracle Database 12c 引入了同步刷新,这是一种 out-of-place 刷新。同步刷新不修改基表的内容,而是使用同步刷新包中的api,同步刷新包通过同时对基表和物化视图应用这些更改来确保一致性。这种方法允许始终同步一组表和在其上定义的物化视图。在数据仓库中,同步刷新方法非常适合,原因如下:
- 增量数据的加载是严格控制的,并且是周期性的。
- 表及其物化视图通常以相同的方式分区,或者它们的分区由功能依赖关系关联。
查询重写
查询重写是一种优化技术,它将一个按主表写的用户请求,转换为在语义上等效的、包含物化视图的请求。
当基表包含大量的数据时,计算一个聚合或联接是非常昂贵和费时的。因为物化视图包含预计算的聚合和联接,所以查询重写能使用物化视图迅速响应查询。
优化器的查询变换器透明地重写用户请求,以便使用物化视图,而无需用户干预或在 SQL 语句中引用物化视图。因为查询重写是透明的,可以添加或删除物化视图,而不会使应用程序中的 SQL 代码无效。
通常,启用重写查询以使用物化视图,而不是使用明细表,能减少响应时间。下图显示了数据库同时生成原始的和经过重写的查询执行计划,然后选择成本最低的计划。
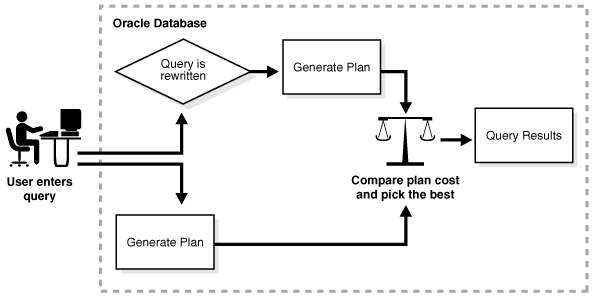
序列概述
序列是一种模式对象,多个用户可以用它来生成唯一整数。序列发生器提供高可扩展性的和性能良好的方法,来为数字数据类型生成代理键。
序列特征
序列定义表示关于序列的一般信息,包括序列的名称以及序列是升序还是降序。
序列定义还表明:
- 编号之间的间隔
- 数据库是否要在内存中缓存生成的序列号集合
- 当超限时序列是否要重复
下面的示例在示例模式 oe 中创建序列 customers_seq。当向 customers 表中添加行时,应用程序可以使用此序列提供客户 ID 号。
CREATE SEQUENCE customers_seq
START WITH 1000
INCREMENT BY 1
NOCACHE
NOCYCLE;
复制对 customers_seq.nextval 的第一次引用会返回 1000。第二次引用返回1001。每个后续引用的返回值比前一个引用大 1。
对序列的并发访问
同一序列发生器可以为多个表生成编号。
以这种方式,数据库可以自动生成主键,并协调跨多个行或表的键。例如,序列可以为 orders 表和customers 表生成主键
序列发生器可用于在多用户环境中生成唯一编号,不会引起磁盘 I/O 开销或事务锁定。例如,两个用户同时向 orders 表中插入新行。通过使用序列来为 order_id 列生成唯一编号,任何一个用户都不必等待别人输入下一个可用的订单号。序列自动为每个用户生成正确的值。
每个引用序列的用户都有权访问他或她的当前序列号,即在该会话中生成的最后一个序列值。用户可以发出一个语句生成一个新的序列号,或使用该会话最后生成的当前序列号。在某个会话中的一个语句生成了一个序列号后,只有该会话可以使用它。单个序列号可以跳过,如果个别序列号在某个事务中被生成使用,而最终被回滚,则它们会被跳过(而变得不连续) 。
维度概述
一个典型的数据仓库有两个重要组成部分:维度和事实。
维度是用于阐述业务问题的类别,例如,时间、地理位置、产品、部门、和分销渠道等。事实是与一组特定的维度的值相关联的事件或实体,例如销售量或利润。
需要使用多维度的示例包括以下:
- 以上升聚合级别方式,显示从 2013 年到 2014 年度,在地理维度上从州到国家到地区,跨越所有产品的总销售额。
- 对 2013 年到 2014 年度,我们在南美的运营情况,创建一个跨表格分析,按地区显示开支。包括所有可能的分类汇总。
- 根据 2014 年汽车产品销售收入,列出在亚洲的前 10 位销售代表,并按其佣金分级。
很多的多维问题往往需要跨时间、地理位置、或预算,来聚合数据和比较数据集。
创建维度允许更广泛地使用查询重写功能。数据库可以通过透明地重写查询以使用物化视图来提高查询性能。
维度的层次结构
维度表是一个逻辑结构,用来定义列对或列集之间的层次关系。
例如,维度可以表示在一行中 city 列表示 state 列的值,state 列表示 country 列的值。
在客户维度中,能将客户上卷到市、州、国家、亚区、和地区。数据分析通常在多维层次结构中从较高级别开始,并在必要时可以逐步下钻。
在子级别的每个值在父级别有且只有一个与其相关联的值。层次结构关系是层次结构中的一个级别对该层次结构中的下一个级别的函数依赖。
维度没有分配数据存储。维度信息存储在维度表中,而事实信息存储在事实表中。
创建维度
维度是用 SQL 语句来创建的。
语句会指定:
- 多个 LEVEL 子句,每个 LEVEL 标识维度中的一个列或列集
- 一个或多个指定相邻级别之间的父/子关系的 HIERARCHY 子句
- 可选的 ATTRIBUTE 子句,每个 ATTRIBUTE 标识与某个单个级别相关联的额外的列或列集
下面的语句用来在示例模式 sh 中创建 customers_dim 维度:
CREATE DIMENSION customers_dim
LEVEL customer IS (customers.cust_id)
LEVEL city IS (customers.cust_city)
LEVEL state IS (customers.cust_state_province)
LEVEL country IS (countries.country_id)
LEVEL subregion IS (countries.country_subregion)
LEVEL region IS (countries.country_region)
HIERARCHY geog_rollup (
customer CHILD OF
city CHILD OF
state CHILD OF
country CHILD OF
subregion CHILD OF
region
JOIN KEY (customers.country_id) REFERENCES country )
ATTRIBUTE customer DETERMINES
(cust_first_name, cust_last_name, cust_gender,
cust_marital_status, cust_year_of_birth,
cust_income_level, cust_credit_limit)
ATTRIBUTE country DETERMINES (countries.country_name);
复制维度中的列可以来自一个表 (反规范化) 或多个表 (完全或部分规范化)。例如,一个规范化的时间维度可以包含日期表、月份表、和一个年度表,使用联接条件,将每个日期行连接到一个月份行,每个月份行联接到一个年度行。在一个完全反规范化的时间维度中,日期、月份、和年度都在同一个表中。无论规范化或反规范化,列之间的层次关系必须在 CREATE DIMENSION 语句中指定。
同义词概述
同义词是一个模式对象的别名。例如,您可以为一个表或视图、序列、PL/SQL 程序单元、用户定义的对象类型、或另一个同义词等创建同义词。因为同义词只是一个别名,因此除了要在数据字典存储其定义之外,不需要其它存储。
同义词可以为数据库用户简化 SQL 语句。同义词也可以用于隐藏底层模式对象的标识和位置。如果必须重命名或移动底层对象,仅需要重新定义同义词。基于同义词的应用程序,可以无需修改而继续工作。
您可以创建私有同义词和公共同义词。私有同义词与其所有者在同一个模式中,只有其所有者对其可用性具有控制权。公共同义词由名为 PUBLIC 的用户组所有,并且能被每一个数据库用户访问。
例 4-6 公共同义词
数据库管理员为 hr.employees 表创建了一个叫做 people 的公共同义词。然后,用户连接到 oe 模式,并计算通过同义词引用的表中的行的数目。
SQL> CREATE PUBLIC SYNONYM people FOR hr.employees;
Synonym created.
SQL> CONNECT oe
Enter password: password
Connected.
SQL> SELECT COUNT(*) FROM people;
COUNT(*)
----------
107
复制请尽量少用公共同义词,因为它们使数据库整合更困难。如下例所示,如果另一个管理员尝试创建 people 公共同义词,则会创建失败,因为在一个数据库中只能存在一个叫做 people 的公共同义词。过度使用公共同义词会导致应用程序之间的命名空间冲突。
SQL> CREATE PUBLIC SYNONYM people FOR oe.customers;
CREATE PUBLIC SYNONYM people FOR oe.customers
*
ERROR at line 1:
ORA-00955: name is already used by an existing object
SQL> SELECT OWNER, SYNONYM_NAME, TABLE_OWNER, TABLE_NAME
2 FROM DBA_SYNONYMS
3 WHERE SYNONYM_NAME = 'PEOPLE';
OWNER SYNONYM_NAME TABLE_OWNER TABLE_NAME
---------- ------------ ----------- ----------
PUBLIC PEOPLE HR EMPLOYEES
复制同义词本身不是安全可控的。当您在一个同义词上授予对象权限时,你其实是在底层对象上授予权限。同义词在 GRANT 语句中只作为对象的别名。
评论

 0 点赞
0 点赞


