




Oracle分析函数实际上操作对象是查询出的数据集,也就是说不需二次查询数据库,实际上就是oracle实现了一些我们自身需要编码实现的统计功能,对于简化开发工作量有很大的帮助,特别在开发第三方报表软件时是非常有帮助的。Oracle从8.1.6开始提供分析函数。
oracle分析函数的语法:
function_name(arg1,arg2,...)
over
(<partition-clause> <order-by-clause ><windowing clause>)
说明:
1. partition-clause 数据记录集分组
2. order-by-clause 数据记录集排序
3. windowing clause 功能非常强大、比较复杂,定义分析函数在操作行的集合。有三种开窗方式: range、row、specifying。
--Partition by,按相应的值(manager_id)进行分组统计
如下:
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id) avg_salary
FROM employees;复制

等同于如下代码:
SELECT
a.manager_id,
a.employee_name,
a.hire_date,
a.salary,
b.avg_salary
FROM
(
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary
FROM employees
) a,
(
SELECT
manager_id,
AVG(salary) avg_salary
FROM employees
GROUP BY manager_id
) b
WHERE a.manager_id=b.manager_id
ORDER BY a.manager_id复制
--Order by按相应的值(hire_date)进行排序并累计统计
--Order by按相应的值(hire_date)进行排序并累计统计复制
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (ORDER BY hire_date)
FROM employees;复制

--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date)
FROM employees;复制
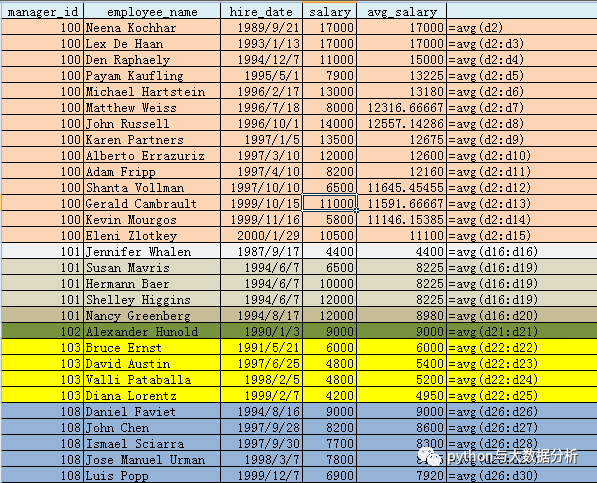
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理的前一个和后两个三者的平均数得来复制
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理的前一个和后两个三者的平均数得来
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING)
FROM employees;复制

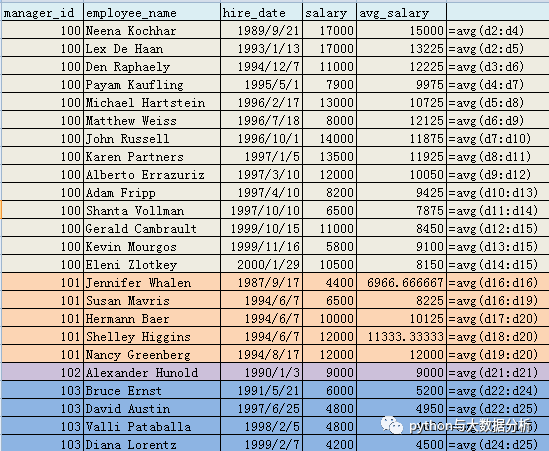
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理,并且雇用时间在该员工时间之前的50天以内和在该员工之后的150天之内员工的薪水的平均值
--range为取值范围,估计只有数字和日期能够进行取值了复制
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理,并且雇用时间在该员工时间之前的50天以内和在该员工之后的150天之内员工的薪水的平均值
--range为取值范围,估计只有数字和日期能够进行取值了
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING)
FROM employees;复制
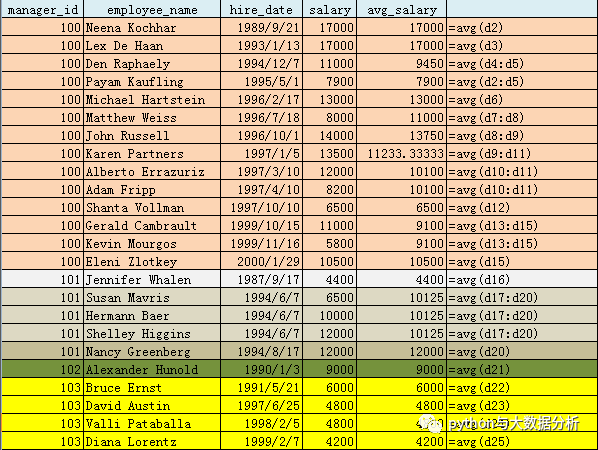
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理的平均值
--每行对应的数据窗口是从第一行到最后一行复制
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理的平均值
--每行对应的数据窗口是从第一行到最后一行
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date) avg_salary_part_order,
AVG(salary) OVER (PARTITION BY manager_id ) avg_salary_order,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) avg_salary_unbound1, --等同于仅partition时候的值
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) avg_salary_unbound2--等同于上面
FROM employees;复制


