






PS: 这是根据笔者去年写的这篇《Alibaba Sentinel是如何统计QPS实现限流的》修改而来,去掉与Dubbo相关的内容,并加以修改。
如果不了解Sentinel,可以看下官方的文档,这里给个传送门:
https://github.com/alibaba/Sentinel/wiki。
要理解Sentinel实现限流的源码,首先我们要了解其核心,比如如何统计QPS,只要了解核心功能的实现,我们也可以自己实现一个简单的限流器。限流是在服务端实现的,Sentinel支持的限流规则有:按最大并线程数限流、按QPS限流。
Sentinel实际上并不需要关心Dubbo、Tomcat等的实际工作线程数,实现按最大线程数限流可以在接收到请求且不拦截请求时,将当前工作线程数加1,完成一个请求之后将工作线程数减1,当当前工作线程数等于限流规则配置的最大线程数时,就可以拦截请求,抛出请求被限流的异常。
为了简单,我不直接分析Sentinel的源码,而是分析我从Sentinel中摘抄的,且经过改造后的qps-helper代码。总体上是一样的,我就去掉一些不需要的统计数据,以及将Sentinel一些自定义的类替换成JDK提供的类,封装成通用的QPS统计工具包。https://github.com/wujiuye/qps-helper
Sentinel以Bucket(桶)为单位记录一个时间窗口内的请求总数、异常总数、总耗时,而一个Bucket可以是记录一秒内的数据,也可以是10毫秒内的数据,我们称这个时间窗口为Bucket的统计单位,由使用者自定义。
public class MetricBucket {/*** 存储各事件的计数,比如异常总数、请求总数等*/private final LongAdder[] counters;/*** 这段事件内的最小耗时*/private volatile long minRt;}复制
Bucket存储一段时间内的请求数、异常数等这些数据用的是一个LongAdder数组,LongAdder保证了数据修改的原子性,数组的每个元素分别代表一个时间窗口内的请求总数、异常数、总耗时。
Sentinel用枚举类型MetricEvent的ordinal属性作为下标,ordinal的值从0开始,按枚举元素的顺序递增,正好可以用作数组的下标。在qps-helper中,LongAdder被我替换为j.u.c包下的atomic类了。
// 事件类型public enum MetricEvent {EXCEPTION,// 异常 对应数组下标为0SUCCESS, // 成功 对应数组下标为1RT // 耗时 对应数组下标为2}复制
当需要获取Bucket记录的总的成功请求数、或者异常总数、或者总的请求处理耗时时,可以通过MetricEvent从Bucket的LongAdder数组中获取对应的LongAdder,并调用sum方法获取总数。
// 假设事件为MetricEvent.SUCCESSpublic long get(MetricEvent event) {// MetricEvent.SUCCESS.ordinal()为1return counters[event.ordinal()].sum();}复制
当需要往Bucket添加1个请求、或者一个异常,或者处理请求的耗时时,可以通过MetricEvent从LongAdder数组中获取对应的LongAdder,并调用add方法。
// 假设事件为MetricEvent.RTpublic void add(MetricEvent event, long n) {// MetricEvent.RT.ordinal()为2counters[event.ordinal()].add(n);}复制
有了Bucket之后,假设我们需要让Bucket存储一秒钟的数据,这样我们就能够知道每秒处理成功的请求数(成功QPS)、每秒处理失败的请求数(失败QPS),以及处理每个成功请求的平均耗时(avg RT)。
我们如何才能确保Bucket存储的就是精确到1秒的数据呢?最low的做法就是启一个定时任务每秒创建一个Bucket,但统计出来的数据误差绝对很大。
而Sentinel是这样实现的,它定义一个Bucket数组,根据时间戳来定位到数组的下标。假设我们需要统计每1秒处理的请求数等数据,且只需要保存最近一分钟的数据。那么Bucket数组的大小就可以设置为60,每个Bucket的windowLengthInMs时间窗口大小就是1000毫秒(1秒)。
 由于每个Bucket存储的是1秒的数据,那么就可以将当前时间戳去掉毫秒部分,就能得到当前的秒数,假设Bucket数组的大小是无限大的,那么得到的秒数就是当前要获取的Bucket所在的数组下标。
由于每个Bucket存储的是1秒的数据,那么就可以将当前时间戳去掉毫秒部分,就能得到当前的秒数,假设Bucket数组的大小是无限大的,那么得到的秒数就是当前要获取的Bucket所在的数组下标。
但我们不能无限的存储Bucket,一秒一个Bucket得要多大的内存才能存一天的数据。所以,当我们只需要保留一分钟的数据时,Bucket数组的大小就是60,将得到的秒数与数组长度取余数,就得到当前Bucket所在的数组下标。这个数组是循环使用的,永远只保存最近1分钟的数据。
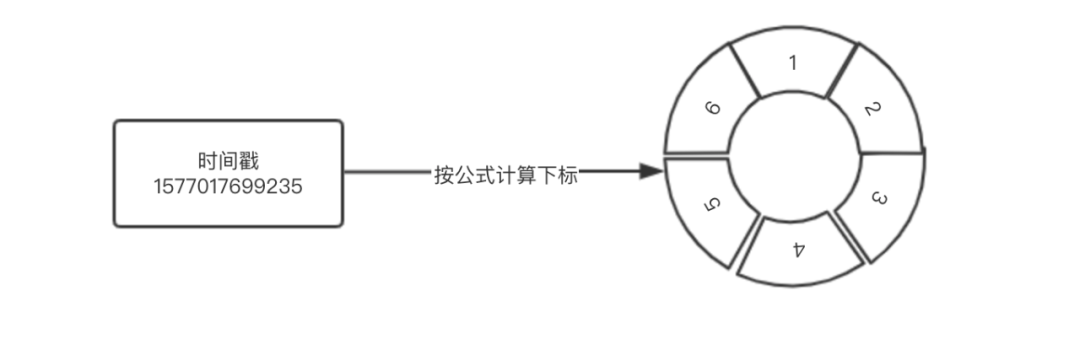
/*** 计算索引,将时间戳映射到Bucket数组。** @param timeMillis 时间戳(毫秒)* @return*/private int calculateTimeIdx(long timeMillis) {/*** 假设当前时间戳为1577017699235* windowLengthInMs为1000毫秒(1秒)* 则* 将毫秒转为秒 => 1577017699* 映射到数组的索引为 => 19*/long timeId = timeMillis / windowLengthInMs;return (int) (timeId % array.length());}复制
取余数就是循环利用数组。如果想要获取连续的一分钟的Bucket数据,就不能简单的从头开始遍历数组,而是指定一个开始时间和结束时间, 从开始时间戳开始计算Bucket存放的数组下标,然后循环每次将开始时间戳加上1秒,直到开始时间等于结束时间。
但由于循环使用的问题,当前时间戳与一分钟之前的时间戳和一分钟之后的时间戳都会映射到数组的同一个下标,因此,必须要能够判断数组下标的数据是否是当前时间的,这便要数组每个元素存储一个Bucket统计的时间窗口的开始时间戳。
比如当前时间戳是1577017699235,Bucket统计一秒的数据,所以将时间戳去掉毫秒数后补0,就得到Bucket统计的时间区间的开始时间戳1577017699000。
拿到Bucket后,计算Bucket的开始时间戳的实现如下。
/*** 获取bucket开始时间戳** @param timeMillis* @return*/protected long calculateWindowStart(long timeMillis) {/*** 假设窗口大小为1000毫秒,即数组每个元素存储1秒钟的统计数据* timeMillis % windowLengthInMs 就是取得毫秒部分* timeMillis - 毫秒数 = 秒部分* 这就得到每秒的开始时间戳*/return timeMillis - timeMillis % windowLengthInMs;}复制
因为Bucket自身并不保存统计数据的时间窗口,所以Sentinel给Bucket加了一个包装类WindowWrap<Bucket>。用于给Bucket记录统计的时间窗口。WindowWrap<Bucket>源码如下。
public class WindowWrap<T> {/*** 单个bucket存储桶的时间长度(毫秒)*/private final long windowLengthInMs;/*** bucket的开始时间戳(毫秒)*/private long windowStart;/*** 统计数据*/private T value;public WindowWrap(long windowLengthInMs, long windowStart, T value) {this.windowLengthInMs = windowLengthInMs;this.windowStart = windowStart;this.value = value;}}复制
如前面所说,假设Bucket以秒为单位统计请求数信息,那么它记录的就是一秒内的请求总数、异常总数这些信息。换算毫秒为单位,比如时间窗口为:1577017699000 ~ 1577017699999,那么1577017699000就被称为该时间窗口的开始时间windowStart。一秒转为毫秒是1000,所以1000就称为窗口的长度windowLengthInMs。windowStart+windowLengthInMs等于该时间窗口的结束时间。
因此,只要给定一个时间戳,就能知道该时间戳是否在该Bucket统计的时间窗口内,代码实现如下。
/*** 检查给定的时间戳是否在当前bucket中。** @param timeMillis 时间戳,毫秒* @return*/public boolean isTimeInWindow(long timeMillis) {return windowStart <= timeMillis && timeMillis < windowStart + windowLengthInMs;}复制
有了Bucket,也有了Bucket数组,也能通过WindowWrap判断一个Bucket所统计的时间窗口。最后就是要能够通过当前时间定位到一个Bucket,当接收到一个请求时,根据当前时间戳计算出一个数组下标,从Bucket数组中获取一个Bucket,调用Bucket的add方法添加事件数,例如给当前时间窗口统计的成功请求数+1。
前面也分析了如何根据时间戳计算出Bucket在Bucket数组的下标的方法,以及根据时间戳计算出Bucket所统计的时间窗口的开始时间。现在要做的就是能够根据当前时间戳找到对应的Bucket。

上图所示代码实现的是:通过当前时间戳,计算出当前Bucket(New Buket)所在的数组下标(cidx),以及Bucket统计时间窗口的开始时间。通过下标拿到当前数组存储的Bucket(Old Bucket)。
当数组下标cidx不存在Bucket时,创建一个新Bucket,并且确保线程安全写入到数组cidx处,将此Bucket返回;
当Old Bucket不为空时,且Old Bucket的开始时间与当前计算得到的New Buket的开始时间相等时,该Bucket就是当前要找的Bucket,直接返回;
当计算出New Bucket的开始时间大于当前数组下标cidx位置存储的Old Bucket的开始时间时,可以复用这个Old Bucket,确保线程安全重置Bucket,并返回。
当计算出New Bucket的开始时间小于当前数组下标cidx位置存储的Old Bucket的开始时间时,直接返回一个空的Bucket(时间不会倒退)。
一个QPS的统计功能,实现起来还是挺复杂的,可能看代码更容易理解,github地址已在文章开头给出。当然,你也可以直接去看Sentinel的源码,在sentinel-core的slots包下。
其实还有很多统计QPS的方法,比如我们看Redis的每秒执行的命令总数,就是通过redis-cli --stat每秒打印一次从Redis启动开始到目前为止的总的执行命令总数,然后减去前一秒打印的命令执行总数,就得到这一秒内执行的命令数。我们可以通过这种方式,启一个定时任务,每秒钟统计一次,这个方法适用于非实时的QPS统计。Sentinel需要获取实时的QPS来实现限流,因此这种方法是不可取的。

