




一、问题域
1.1 问题背景
JVM设计之初,自动化内存管理一直是一个亮点,降低了很大的入门门槛,但是自动化的东西有一个很致命的缺点就是没有办法管理。例如没有办法做精细化的管控和资源隔离,比如有多个业务功能在同一台JVM上,只要有一个业务出现了内存问题,其他业务由于雪崩效应都会不可用,所以有必要对每个业务做资源隔离,防止雪崩。
1.2 已经存在方案的分析
内存由开发者自己管理其实在许多网络框架以及大数据领域出现的比较多,是因为这些框架处理的数据量非常的大,不加以管理非常容易导致系统奔溃。我知道的已经实现的内存保护方案有两种:自己实现内存缓冲池、序列化/反序列化。
例如网络通信框架的绝对霸主Netty,在高可靠方面就实现了内存保护机制,他将网络流量数据的内存申请交由一个内存缓冲池来管理,其在网络流量处理Pipeline的第一个节点申请了内存,在网络流量处理Pipeline的最后一个节点释放了内存。
例如流处理框架Flink通过将对象序列化成字节数组进行内存统计,使用时在反序列化成具体的对象。
1.3 新思路
由于Java对象在JVM虚拟机中的数据结构是有规律可循的,因此可以通过程序计算得出对象会占用的内存大小。
1.4 问题研究的价值
BB了那么多,研究这玩意儿有什么用呢?我总结大概有以下两点:
用作内存熔断器,通过预设某一项业务可使用的内存大小,当其使用超过了预设值的时候,通过主动抛出异常来避免内存无节制申请,实现提前熔断。
预估业务规格,例如业务分配的机器可使用的内存是2G,那么可以通过预估数据内存占用来确定可以支持的规格大小。
二、方案设计
2.1 基础知识
方便大家理解,简单的介绍一下JVM中对象的数据结构。
2.1.1 JVM内存结构
下面用一个String对象举例,当new一个String对象时候,JVM堆里面会创建哪些对象。
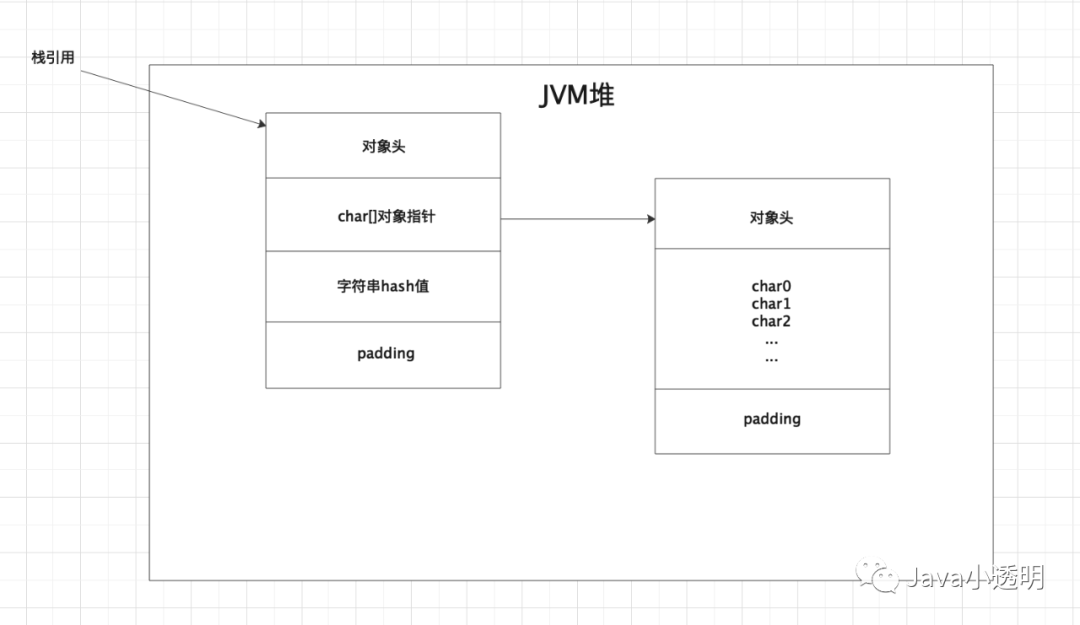
如上图,JVM在堆里面实际上创建了两个对象,左边的是String对象,String对象有两个成员变量(非静态),分别是char[]类型的value和int类型的hash。右边的是char[]数组对象,数组里面就是字符串的每一个char字符。
一个对象的内存组成部分由以下三部分组成:
对象头的组成部分:MarkWord(8字节) + 对象Class指针(4/8字节) + 数组长度(4字节,只有数组对象才有)
成员属性数据:图示有两个成员属性,分别为:
1)char[]对象指针:可以作为普通对象类型的代表,占用4/8个字节
2)字符串hash值:int基本数据类型,占用4个字节
padding:补全空白字节,默认会将对象占用的内存补足成8字节的整数倍
注:4/8字节如何判断参照2.1.2节
2.1.2 Oops指针压缩和字节对齐
在JVM参数中关于内存分配有两个比较重要的参数:
-XX:+UseCompressedOops
在64位虚拟机中开启指针压缩,将原本占用8个字节的指针压缩到4个字节,以节约内存。这个参数生效的范围包括2.1.1节中对象头里面的对象Class指针以及非基本数据类型对象指针(char[]对象指针)。
注:在jdk1.8中这个参数是默认开启的,所以下面进行讨论的时候会按照开启讨论
-XX:ObjectAlignmentInBytes=8
由于JVM要求每一个对象都必须是某一个值的整数倍,这个值就是由这个参数控制的,默认值是8。即对象头加上成员变量的字节数如果不是8的整数倍,由padding负责补全。
2.2 方案设计
我们先来对堆java里面的对象进行一个分类,可以分为
基本数据类型
byte
,short
,int
,long
,float
,double
,char
,boolean普通对象类型(基本数据类型的包装类也算在里面)
数组对象
2.2.1 基本数据类型占用大小大家都知道,如下图所示。
| 基本数据类型 | 占用大小 |
|---|---|
| byte | 1字节 |
| short | 2字节 |
| int | 4字节 |
| long | 8字节 |
| float | 4字节 |
| double | 8字节 |
| boolean | 1字节 |
| char | 2字节 |
2.2.2 普通对象类型(以String举例)的计算公式
对象头分为 MarkWord(8字节)
+ 对象Class指针(4字节)
= 12字节
String中的hash成员变量(int类型) = 4字节
String中的value成员变量引用(char[]类型) = 4字节
上面加起来的总字节大小是20字节,由于必须是8的倍数,所以padding
占用4个字节
2.2.3 数组对象类型(以char[]举例)的计算公式
对象头分为 MarkWord(8字节)
+ 对象Class指针(4字节)
+ 数组长度(4字节)
= 16字节
成员变量为char的占用字节(2字节) * 数据长度(假设为10) = 20字节
上面加起来的总字节大小是36字节,所以padding
是4字节
注:数组的成员也可以分为基本数据类型和普通对象,如果是普通对象递归套用普通对象类型的公式即可
2.3 测试验证
我这边利用随机字符串生成工具生成了一千万个长度为10的随机字符串(必须是随机字符串,原因后面会讲)。
按照上一节的设计,一个长度为10的随机字符串占用内存空间大小为24字节+40字节 = 64字节。所以一千万个字符串占用大小为64bytes * 10000000 = 610.35MB。
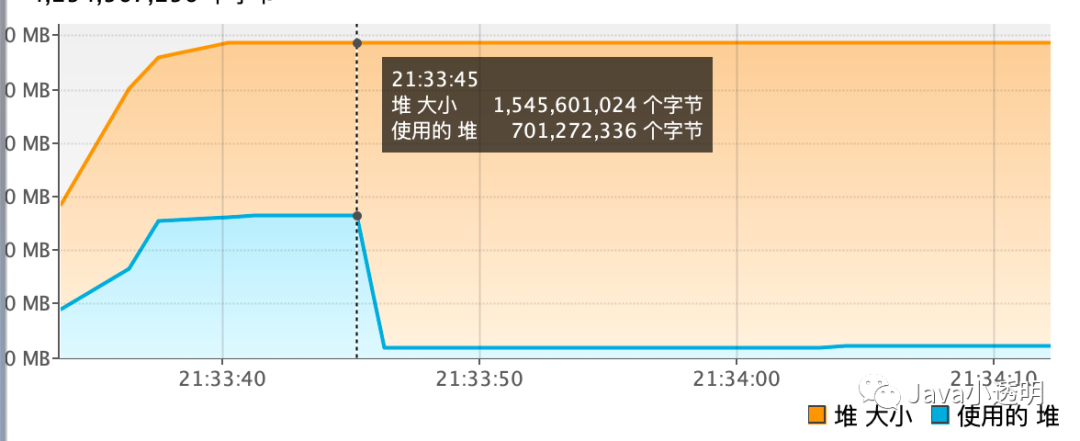
验证程序设计方式为:用一个list持有所有的字符串,并记录下此时的内存占用大小A,再将list清空并手动执行一次gc,再次记录下内存占用大小B,那么A-B就是这些字符串实际占用的大小。
GC前
GC后
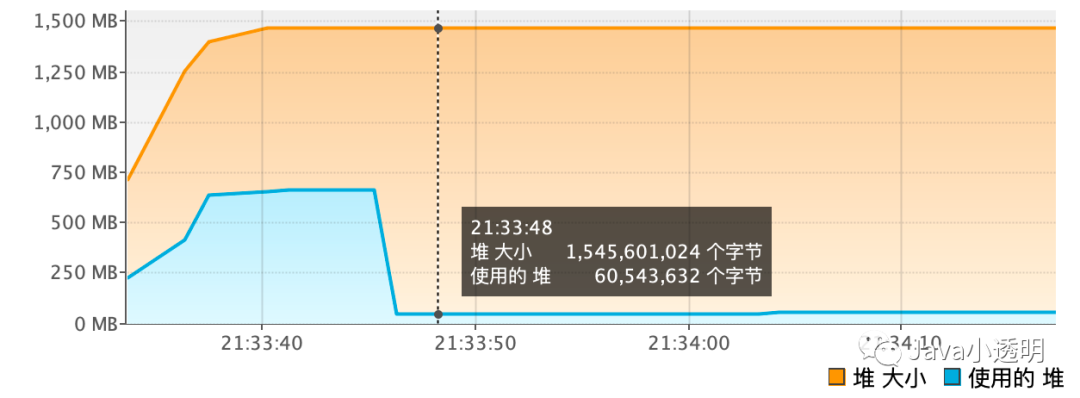
从图中可以看出 A-B = 701272336 - 60543632 = 611.05MB。与程序预测的610.35MB吻合。
三、方案回顾
3.1 无法支持深度递归
虽然一切看似都很完美,但实际上这个方案还是有不足的。例如此方案不能支持无限的深度递归,什么是深度递归呢?就是指的对象A的成员变量是对象B,B的成员变量又有成员C的情况。如果程序要支持无限深度递归会存在两个比较大的问题:
可能会存在循环引用,如果存在循环引用,程序将会陷入死循环。
支持深度递归的ROI不高,往往在业务场景下,不会出现很多次的嵌套,往往最多两层就能满足业务需求了,再极端一点的情况通过将对象扁平化也能解决,这样既可以保证实现业务,也可以保证程序尽可能的简单易维护。
3.2 什么情况下会有误差?
虽然从测试情况来看,预测的很准,但是有些情况下还是会存在偏差的(预测的比实际使用的内存要高):
JVM本身的共享字符串机制,JVM对字符串有特殊的处理,对于一些出现频率高的相同字符串会采用字符串常量池的机制,导致实际占用的内存比预计的要小,这也是为什么在2.3节强调一定要使用随机字符串,如果使用相同字符串的话,你会发现一千万个字符串实际内存占用只会有几十个字节。如果硬要对共享字符串的情况进行针对性适配也是可以的,但是成本实在是太高了,不建议这么做。
较小的int型/long类型(-128~127)也会采用类似共享对象的机制。
统计对象占用内存大小的过程本身也是需要内存支持的。
