




一、问题背景
问题概述
线上接口人工采集excel数据进行录入的时候系统报了OOM错误:java.lang.OutOfMemoryError: GC overhead limit exceeded
。
这个错误类型出现的时机是JVM花了绝大多数的CPU执行GC,但是只回收了很小的一部分内存空间时,JVM会抛出这个类型的OOM错误。
存在问题
优化前的接口由于内存占用非常大,上传大一点的文件直接GG,需要对代码进行优化。但是代码优化后发现录入时候内存一直居高不下。
二、优化方案&测试场景
方案分析
java领域对excel进行处理的框架基本上都是Apache的POI,但是POI的问题在于他会存在excel中的各种样式、批注等我们实际上并不关心的内容,一旦读取文件到内存中会占用翻几番的内存。
其实对于任何大数据量的问题,核心思路都是一样的:
内存放不下?搞到硬盘上!
一次数据量太大?少食多餐分批搞!
项目里面针对excel读取用的是EasyExcel框架,在硬盘上存放文件,用类似滑动窗口的形式读取整个文件,以此来减少一次性加载占用大内存,并且以1W行记录为一批,用完就丢弃以释放内存,避免一次性读取所有对象撑爆内存。
测试环境
系统环境

测试数据
测试数据为20W11列的excel数据,文件格式是.xlsx,文件大小是12.7MB
注:xlsx文件底层是xml+zip压缩存储的,因此解压后的文件会占用非常大的内存,xml的信息熵你懂的
JVM参数
为了快速复现问题,JVM的堆大小配置成了500M
-Xms500M -Xmx500M复制
三、问题定位分析
一般来说,Java领域出现非bug类的问题百分之九十都是由于内存/GC出现了问题导致的。但是具体是哪方面比如网络、上下游系统、内存泄漏等,需要具体问题具体分析,要分析问题第一步就是要获取系统的运行状态。
下面是上传文件时候的GC情况。
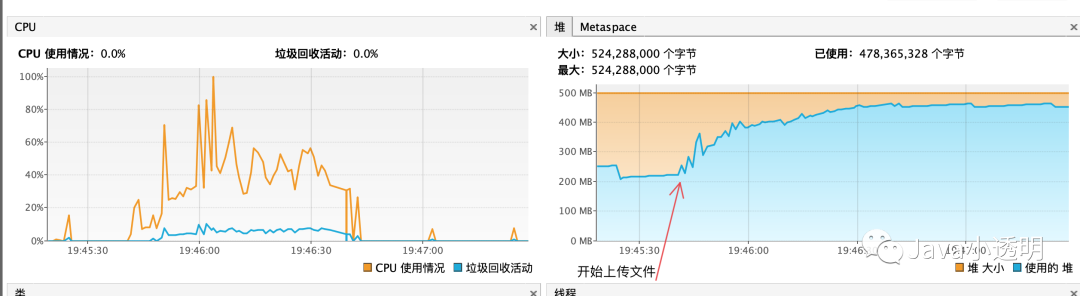
可以看出来是内存一直被占用,无法被释放(手动执行GC也不行),但是问题在于上传的请求已经结束,理论上此次上传占用的内存全部可以被回收掉,不应该出现内存占用的问题。
一般来说如果内存占用并且没有被释放掉,我的经验是有以下二种可能:
内存发生了泄漏,使用完对象后有全局变量引用,导致无法被GC
程序某个地方发生阻塞等待,导致方法栈帧里面引用的对象无法被释放,常见的有数据库阻塞
接下来就是要明确占用的内存里面到底是哪些东西?dump下来JVM的堆内存,在jvisualvm中进行分析。利用OQL对比较大的String进行筛选结果如下:

发现大量的String对象是SQL语句,这些就是文件解析后进行执行的SQL语句,那么问题来了,为啥这些SQL并没有被回收?一般第一直觉出现SQL往往会联想到Mybatis框架上去,因为他是与SQL关系非常紧密的地方,但是经过对Mybatis框架代码的review过后发现,并不是Mybatis缓存的问题。当然日志中也可能出现SQL,不过也很快被我排除了。
如果说请求完成了,一般请求中产生的对象也会被释放,那么有什么是不会释放的呢?最终想到一个:数据库连接Connection,Connection与执行SQL强相关,并且Connection一般都是从池中获取,使用完后会放回池中,与当前的现象非常的符合。而后对sql语句的GC Root分析也证明了这一点:
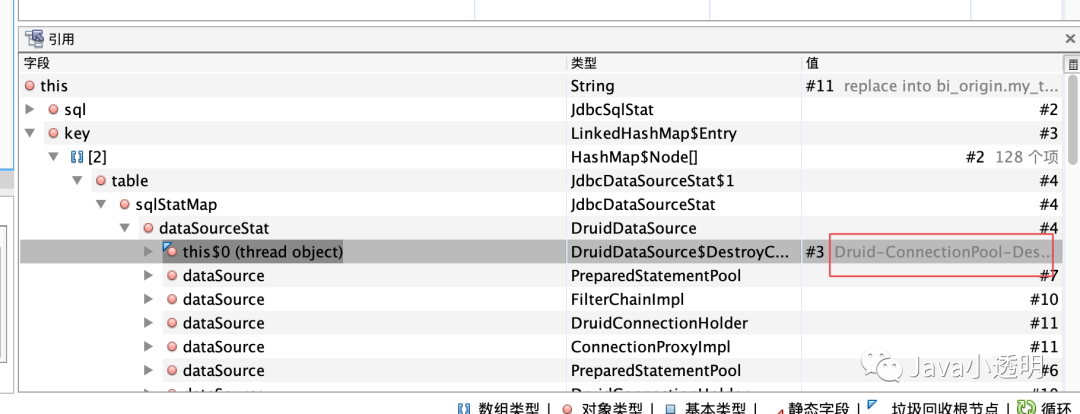
那么可能猜测,SQL被缓存在Connection中,并随着Connection一起被放回Connection Pool中去了,通过百度Druid的参数配置将数据源的SQL缓存关闭。

之后在进行一次文件上传,这时的GC就非常的丝滑,也并没有出现内存释放不掉的情况。
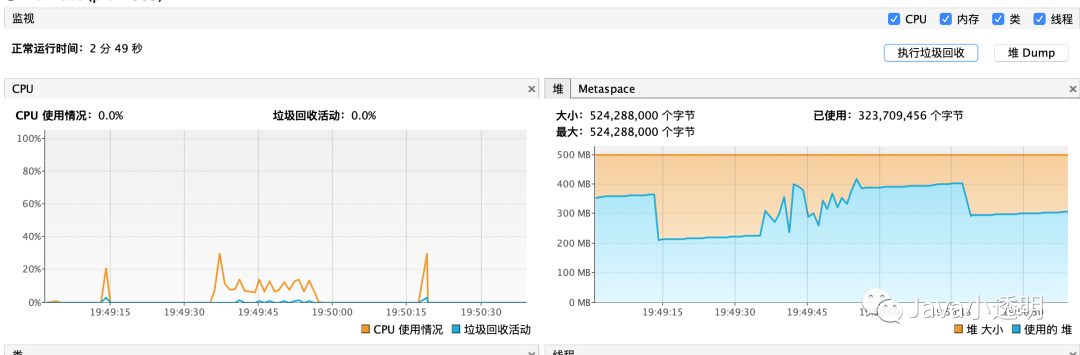
nice!~
四、总结
4.1 改进方式
其实这个问题可以有其他的解决办法,但是直接修改配置是最简单并且最快恢复业务的,应该是最优先采用的。但是从技术的角度来说不是这样,通过Druid数据源的代码review,发现Druid利用LinkedHashMap做了一个LRU Cache缓存SQL语句,Cache的容量是20个语句。
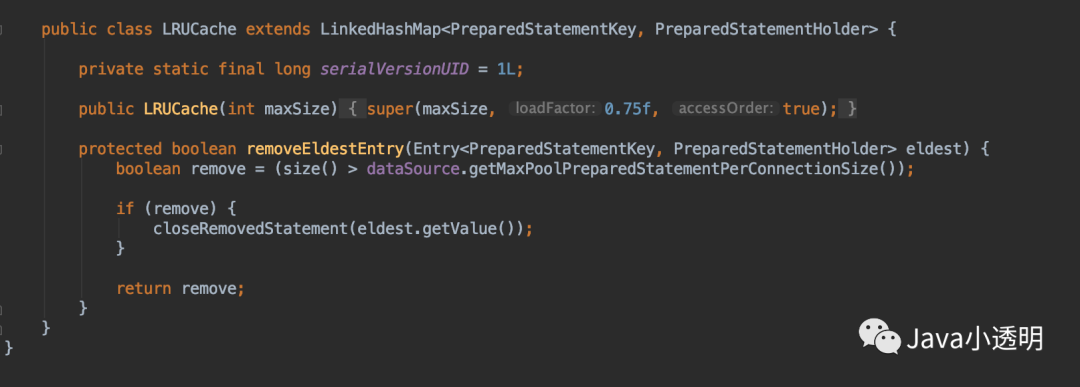
这种方式其实有个问题在于如果一个SQL语句非常大,20个SQL也可能导致内存被占用非常多。所以其实将LRU Cache中的强引用替换成SoftReference,就可以完美解决大SQL倾斜的问题。
4.2 归纳线上问题的一般思路
线上问题的一般步骤分为 1)指标监控观察 2)分析并猜想原因 3)验证猜想。
这其中我觉得最核心的能力应该是:证据链的查找以及分析决策树的建立。举个线上CPU占用率高的问题,下图就是应该在脑中建立起来的分析决策树,从现象到猜想到验证,而打印Stack以及查看GC日志就是证据链查找的一部分。
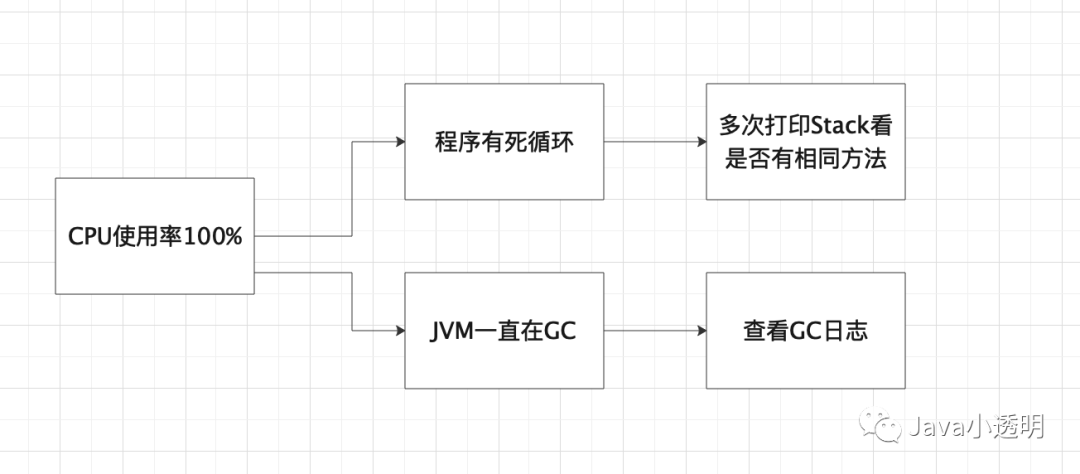
线上定位问题就是这样,改问题不难,难的是知道哪里会出问题,并且对知识广度也是有要求的,问题可能在网络、数据库、linux系统参数配置、内存等等,所以有空多看看跨领域的书也是有帮助的,哈哈。
最后,帮我的HR打个广告,招Java开发/前端/产品,主要是电商/数据可视化相关方向的,简历投递hfzhou@leqee.com,欢迎过来和我battle~

