




背景知识 跨主机通信解决方案 虚拟化网络 Netfilter Kube-proxy代理方案 包转发路径 userspace模式 iptables模式 ipvs模式 BPF模式
背景知识
跨主机通信解决方案
主机 A 上的实例(容器、VM 等)如何与主机 B 上的另一个实例通信?有很多解决方案:
直接路由:BGP 等 隧道:VxLAN, IPIP, GRE 等 NAT:例如 docker 的桥接网络模式 其它方式
虚拟化网络
LAN
缺点: 广播风暴
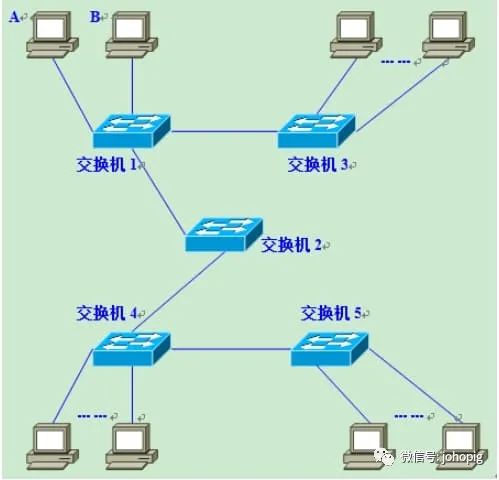
假设图中的计算机A需要与B通信,必须在数据帧中指定B的MAC地址,因此A必须先广播 ARP
请求来获取B的MAC地址。交换机1收到广播帧(ARP)请求后,会将它转发到自己的除接收端口之外的所有端口,交换机2、3亦是如此,那这样就会导致广播风暴的发生,这样消耗了整个网络的整体带宽和CPU运算资源。
VLAN
特点:快啊,传输效率高
原理:将原先的网络架构改造为互通的大二层网络并划分出一个个广播域,即通过普通的交换机或者三层交换机直接路由
解决的问题: 跨主机/容器通信
方式:
静态VLAN------基于端口 动态VLAN 基于MAC地址 基于IP地址(基于子网的VLAN,是通过所连计算机的IP地址,来决定端口所属VLAN的) 基于用户
缺点:
需要二层网络设备的支持,通用性和灵活性差;
通常交换机可用的
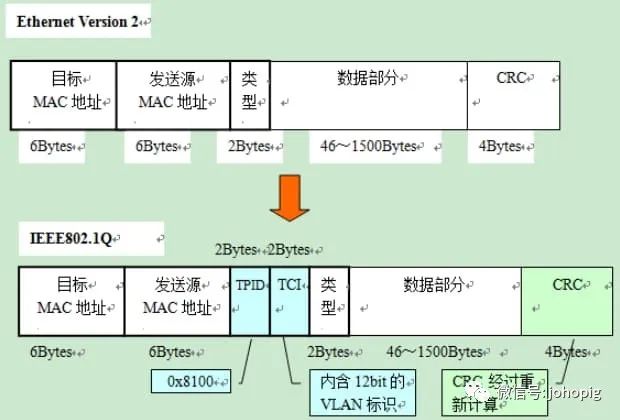
VLAN
数量在4000个左右,这对容器集群规模造成了限制,不能满足大型的公/私有云场景;VLAN tag 总共有 4 个字节,其中有
12 bit
用来标识不同的二层网络(即LAN ID
或叫TCI
),故而最多只能支持 []{.math .math-inline .is-loaded},即4096
个子网的划分
VXLAN
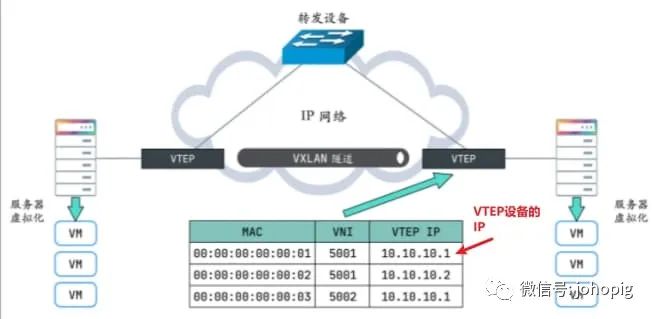
原理: 始报文经过 VTEP
,被 Linux 内核添加上 VXLAN
头部以及外层的UDP
头部,再发送出去,对端 VTEP
接收到 VXLAN 报文后拆除外层 UDP
头部,并根据 VXLAN 头部的 VNI
把原始报文发送到目的服务器。但这里有一个问题,第一次通信前双方如何知道所有的通信信息(类ARP)?这些信息包括:
哪些 VTEP
需要加到一个相同的 VNI 组?答: 管理员一开始进行分组发送方如何知道对方的 MAC
地址?如何知道目的服务器在哪个节点上(即目的 VTEP 的地址)?答: 实际上, VTEP
也会有自己的转发表,转发表通过泛洪和学习机制来维护,对于目标 MAC地址在转发表中不存在的未知单播,广播流量,都会被泛洪给除源 VTEP外所有的 VTEP,目标 VTEP 响应数据包后,源 VTEP 会从数据包中学习到MAC
,VNI
和VTEP
的映射关系,并添加到转发表中,后续当再有数据包转发到这个 MAC地址时,VTEP 会从转发表中直接获取到目标 VTEP地址,从而发送单播数据到目标 VTEP。
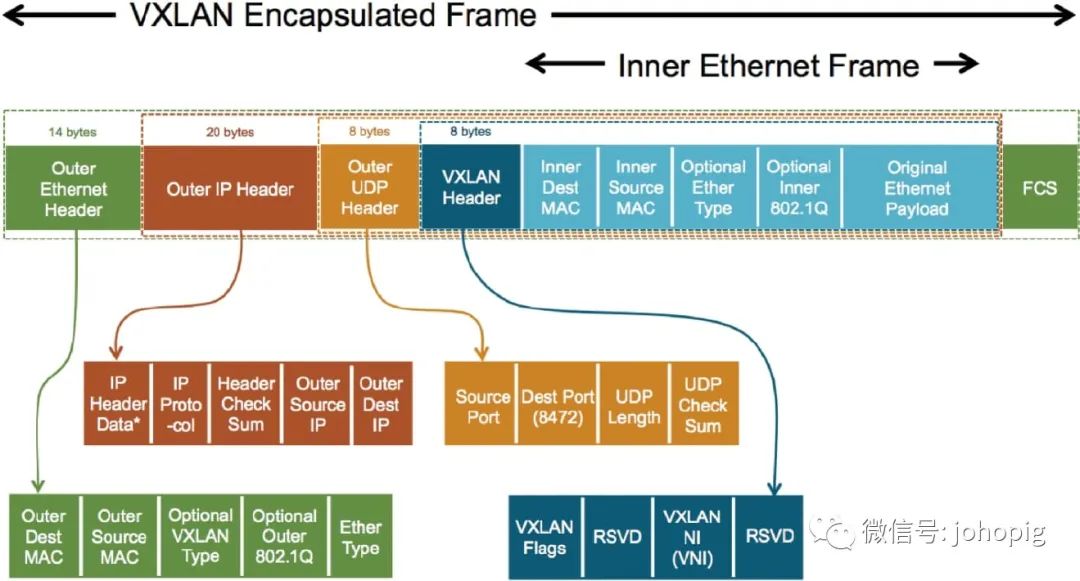
数据包传输过程
绿色的 10.0.0.1 会将 IP 数据包发送给 VTEP; 服务器 1 的 VTEP 收到 10.0.0.1 发送的数据包后; 从收到的 IP 数据包中获取目的虚拟机的 MAC 地址; 在本地的转发表中查找该 MAC 地址所在服务器的 IP 地址,即204.79.197.200; 将服务器1所在的虚拟网络标识符(VxLAN NetworkIdentifier、VNI)以及原始的 IP 数据包作为负载,构建新的 UDP数据包; 将新的 UDP 数据包发送到网络中; 服务器 2 的 VTEP 收到 UDP 数据包后; 去掉 UDP 数据包中的协议头; 查看数据包中VNI(根据VNI转发到指定的子网中,这里也就是10.0.0.2); 将 IP 数据包转发给目标的绿色服务器 10.0.0.2; 绿色的 10.0.0.2 会收到绿色服务器 10.0.0.1 发送的数据包;

解决的问题:
相比于VLAN最多支持的4096个子网来说,VXLAN 的报文 Header 预留了 24 bit
来标识不同的二层网络(即VNI
,VXLAN Network Identifier),即 3 个字节,可以支持 []{.math .math-inline .is-loaded} 个子网。
Overlay Network
特点:不改变网络基础设施的前提下将二层报文封装在IP报文上的新的数据格式原理:使用虚拟局域网拓展技术(Virtual Extensible LAN,VxLAN)组建Overlay
网络。在下图可以看到两台物理机能够通过三层的IP网络互相访问。
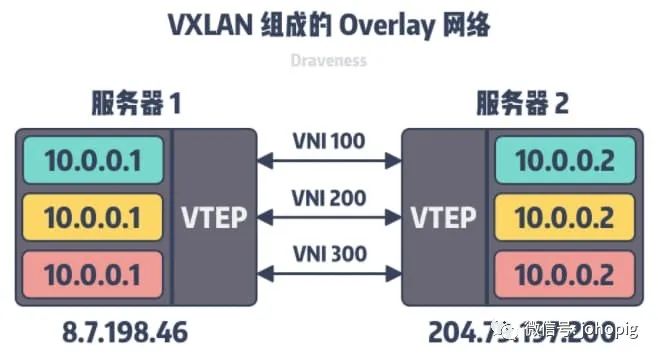
VxLAN使用虚拟隧道端点(Virtual Tunnel EndPoint、VTEP)设备对服务器发出和收到的数据包进行二次封装和解析。
在数据包传输的过程中,通信双方都不知道底层网络做的转换,它们认为两者可以通过二层的网络相互访问,但其实经过了三层的IP网络中转,通过VTEP
之间建立的隧道实现了联通。除了VxLAN之外,Overlay还有很多的实现方案,大同小异。
解决的问题:
方便云计算集群内、跨集群、虚拟机和实例的迁移 前面VLAN提到的缺点
缺点: 封包和拆包带来额外的开销
Netfilter
Netfilter 是 Linux内核内部的包过滤和处理框架,我们平常使用的iptables就是依赖它而做的客户端工具。
一些要点:
主机上的所有数据包都将通过 netfilter 框架 在 netfilter 框架中有 5 个钩子点: PRE_ROUTING
,INPUT
,FORWARD
,OUTPUT
,POST_ROUTING
,此外,这 5个钩子还可以与内核的其他网络设施,如内核路由子系统进行协同工作。命令行工具 iptables
可用于动态地将规则插入到钩子点中可以通过组合各种 iptables
规则来操作数据包(接受/重定向/删除/修改,等等)
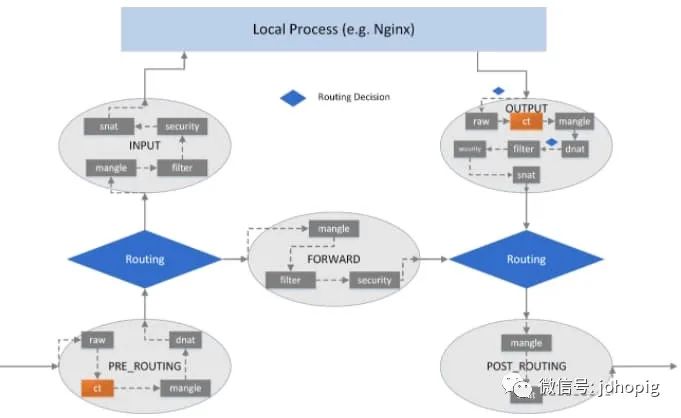
默认有四表五链
,在下面的文章中无论是docker还是kube-proxy都会在filter、nat
表中添加新链
Kube-proxy代理方案
K8s 里实现 Service 的组件是 kube-proxy,实现的主要功能就是将访问 VIP的请求转发(及负载均衡)到相应的后端pods。下文提到的iptables规则都由它创建以及管理。kube-proxy 是 K8s 的可选组件,如果不需要 Service功能,可以不启用它
包转发路径
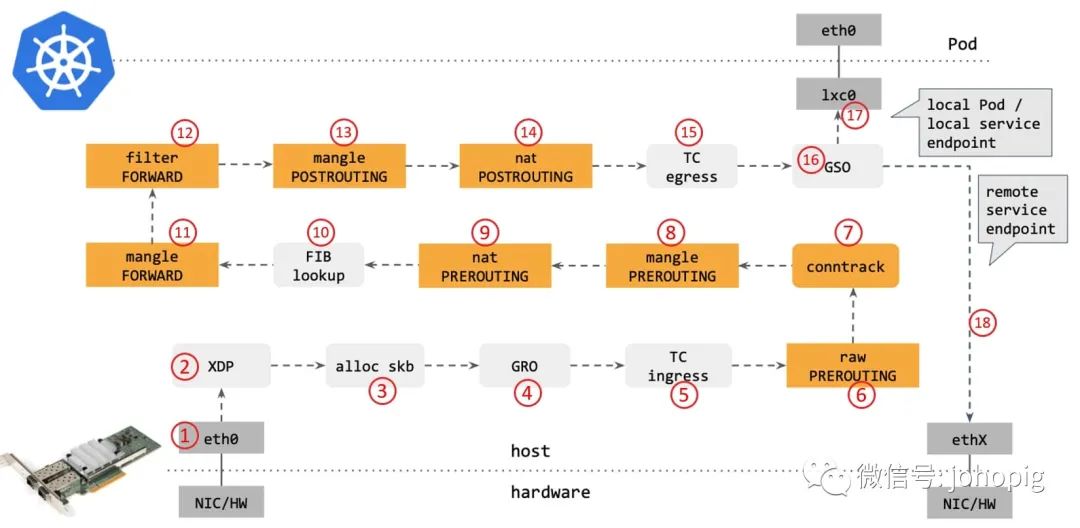
步骤:
网卡收到一个包(通过 DMA 放到 ring-buffer)。 包经过 XDP hook 点。 内核给包分配内存,此时才有了大家熟悉的 skb
(包的内核结构体表示),然后 送到内核协议栈。包经过 GRO 处理,对分片包进行重组。 包进入 tc(traffic control)的 ingresshook。接下来,所有橙色的框都是 Netfilter 处理点。 Netfilter:在 PREROUTING
hook 点处理raw
table 里的 iptables规则。包经过内核的连接跟踪(conntrack)模块。 Netfilter:在 PREROUTING
hook 点处理mangle
table 的 iptables规则。Netfilter:在 PREROUTING
hook 点处理nat
table 的 iptables规则。进行路由判断(FIB:Forwarding InformationBase,路由条目的内核表示,译者注) 。接下来又是四个 Netfilter处理点。 Netfilter:在 FORWARD
hook 点处理mangle
table 里的 iptables规则。Netfilter:在 FORWARD
hook 点处理filter
table 里的 iptables规则。Netfilter:在 POSTROUTING
hook 点处理mangle
table 里的 iptables规则。Netfilter:在 POSTROUTING
hook 点处理nat
table 里的 iptables规则。包到达 TC egress hook点,会进行出方向(egress)的判断,例如判断这个包是到本地设备,还是到主机外。 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会: 发送到一个本机 veth 设备,或者一个本机 service endpoint, 或者,如果目的 IP 是主机外,就通过网卡发出去。
XDP
是位于网卡驱动程序里的一个快速处理包的HOOK点,位于linux网络栈最底层(在网卡的驱动程序处),无需将包送到复杂的协议栈进行处理(通过将eBFP
字节码规则灌进XDP
中作为过滤规则),所以能够用来处理高速数据流量,相比于使用原始的iptables防火墙来丢包亦或者使用带有连接跟踪模块的iptables防火墙来说,性能提高了数倍。
顺便推荐了解一下
eBPF
,eBPF技术和XDP
、TC
(traffic control)组合使用可以实现功能更强大的网络功能
userspace模式
在内存中维护一份VIP:Port到Real IP:Port的映射关系,通过反向代理转发请求并返回客户端。该模式下kube-proxy会为每一个Service创建一个socket套接字用于接收和转发Client的请求。
缺点
需要来回在用户空间和内核空间交互通信,因此效率很差。
iptables模式
iptables的基础知识不是本文重点,下面的内容需要老哥提前了解相关基础知识
NodePort Service
首先这是Service的yaml,并且Service的类型为nodePort
:
Service的类型还有
ClusterIP
、LoadBalancer
、ExternalName
这几种,但在流量拦截和转发方面底层实现非常相似
apiVersion: v1
kind: Service
meadata:
labels:
name: gym
name: gym
space:
ports:
- port: 6080
targetPort: 6080
nodePort: 30005
type: NodePort
selector:
app: gym复制
client通过节点的端口访问nodePort
时,会进入kube-proxy针对nodePort
流量入口创建的KUBE-NODEPORTS链,但是这次只匹配协议类型和目的端口号,匹配成功后才转到对应的KUBE-SVC链
-A PREROUTING -m -comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m -comment --comment "kubernetes service portals" -j KUBE-SERVICES
# 下面两条规则做的事情的实际含义是k8s会让所有k8s集群内部产生的数据包流经nat表的
# 自定义链“KUBE-MARK-MASQ”,然后在这里k8s会对这些数据包打一个标记(0x4000/0x4000),
# 在nat的自定义链“KUBE-POSTROUTING”中根据上述标记匹配所有的k8s集群内部的数据包,
# 匹配的目的是k8s会对这些包做SNAT操作
-A POSTROUTING -m -comment --comment "kubernetes postrouting rules " -j KUBE-POSTROUTING
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
# 10.254.0.40/32代表的是K8s分配到ClusterIP所在的网段,如果有该网段内访问的流量
# 说明是来自Cluster内的访问,则直接跳转到SVC链
-A KUBE-SERVICES -d 10.254.0.40/32 -p tcp -m -comment --comment \
"default/tomcat: cluster ip" -m tcp --dport 6080 -j KUBE-SVC-67RLXXX
# 如果上1条没匹配到(说明不是通过ClusterIP访问流量),并且 dst 是
# LOCAL,跳转到 KUBE-NODEPORTS
# 另外,可以看到iptables在处理报文时会优先处理目的IP为cluster IP的报文,匹配失败之后再去使用NodePort方式
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeport; NOTE: this must be the \
last rule in this chain " -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-NODEPORTS -p tcp -m -comment --comment "default/gym:"\
-m tcp --dport 30005 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m -comment --comment "default/gym:"\
-m -tpc --dport 30005 -j KUBE-SVC-67RLXXX复制
跳转到KUBE-SVC链后,采用了iptables的random模块,使连接有50%的概率进入KUBE-SEP-ID6YXXX链,50%的概率进入KUBE-SEP-IN2YXXX链。因此,kube-proxy的iptables模式采用随机数实现了服务的负载均衡
-A KUBE-SVC-67RLXXX -m comment --comment "default/gym:" -m \
statistic --mode random --probability 0.500000000 -j KUBE-SEP-ID6YXXX
-A KUBE-SVC-67RLXXX -m comment --comment "default/gym:" -j \
KUBE-SEP-IN2YXXX复制
KUBE-SEP-ID6YXXX链的具体作用就是将请求通过DNAT发送到192.168.20.1的6080端口
# 如果 src_ip=192.168.20.1/32,说明是 Service->client 流量,则
# 需要做 SNAT(MASQ 是动态版的 SNAT,能够自动的寻找外网地址并改为当前正确的外网IP地址),
# 替换 src_ip -> svc_ip,这样客户端收到回程包时,
# 看到就是从 svc_ip 回的包,跟它期望的是一致的。
-A KUBE-SEP-ID6YXXX -s 192.168.20.1/32 -m -comment --comment "default/gym:"\
-j KUBE-MARK-MASQ
# 如果没有命中上面一条,说明 src_ip != 192.168.20.1/32,则说明是 client-> Service 流量,
# 需要做 DNAT,将 svc_ip -> pod1_ip
-A KUBE-SEP-ID6YXXX -p tcp -m -comment --comment "default/gym:"\
-m tcp -j DANT --to-destination 192.168.20.1:6080复制
iptables模式最主要的链是KUBE-SERVICES、KUBE-SVC-*和KUBE-SEP-*
KUBE-SERVICES链是访问集群内服务的数据包入口点,它会根据匹配到的目标IP:port将数据包分发到相应的KUBE-SVC-*链或KUBE-NODEPORTS链 KUBE-SVC-*链相对于一个负载均衡器,它会将数据平均分发到KUBE-SEP-*链,每个KUBE-SVC-*链后面的KUBE-SEP-*都和Service的后端Pod数量一样。 KUBE-SEP-*链通过DNAT将连接目的地址和端口从Service的IP:port替换为后端Pod的IP:port,从而将流量转发到相应的Pod。
缺点
iptables模式与userspace模式相比,虽然在稳定性和性能上均有不小的提升,但可扩展性差。随着service数据达到数千个,其控制面和数据面的性能都会急剧下降。原因在于iptables控制面的接口设计中,每添加一条规则,需要遍历和修改所有的规则,其控制面性能是O(n²)。在数据面,规则是用链表组织的,其性能是O(n)。后果就是: 例如5k个service时,iptables规则将达到25k条,后果就是 packet latency
,每个包都要捋一遍这些规则直到匹配到某条规则iptables是不支持单独更新某条规则的,只能全部读出来,更新集合,再将集合下发到宿主机,规则一多慢的要死 iptables 依赖 Netfilter和连接跟踪模块(conntrack),在大流量场景下会出现一些竞争问题(raceconditions);UDP场景尤其明显,会导致丢包、应用的负载升高等问题。常见的就conntrack表被挤爆了。 LB调度算法仅支持随机转发
ipvs模式
当客户端访问Service(L4LB节点)时,Service将做双向 NAT,数据流如下图所示:
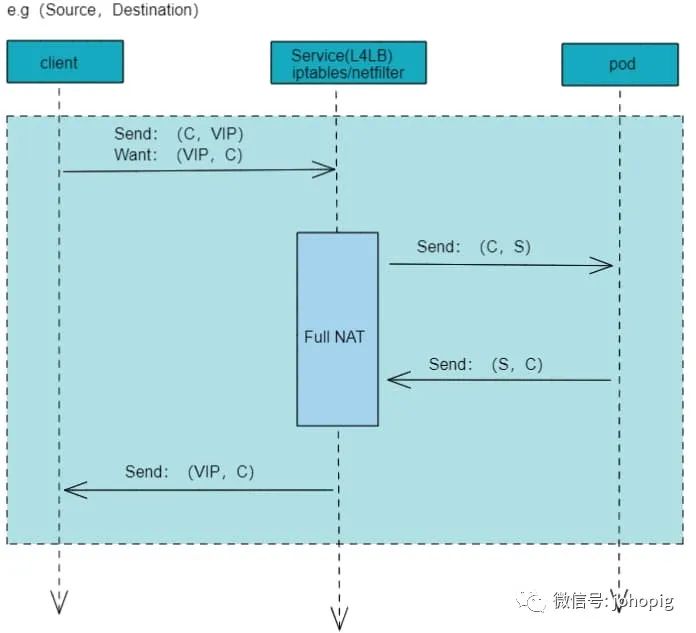
其实和普通的iptables
模式没有什么区别,主要是底层规则的数据结构变了,这样就提升了很多效率
Full NAT,依赖
connTrack
(connTrack
工作在三层),
不管是 iptables 还是 ipvs 转发模式,Kubernetes 中访问 Service 都会进行 DNAT,将原本访问
ClusterIP:Port
的数据包 DNAT 成 Service 的某个Endpoint (PodIP:Port)
,然后内核将连接信息插入conntrack
表以记录连接,目的端回包的时候内核从conntrack
表匹配连接并反向 NAT即SNAT,这样原路返回形成一个完整的连接链路
IPVS 是专门为LB设计的。它用hash table管理service,对service的增删查找都是O(1)的时间复杂度。不过IPVS内核模块没有SNAT功能,因此借用了iptables的SNAT功能。IPVS针对报文做DNAT后,将连接信息保存在nf_conntrack中,iptables据此接力做SNAT。该模式是目前Kubernetes网络性能最好的选择。但是由于nf_conntrack的复杂性,带来了很大的性能损耗。
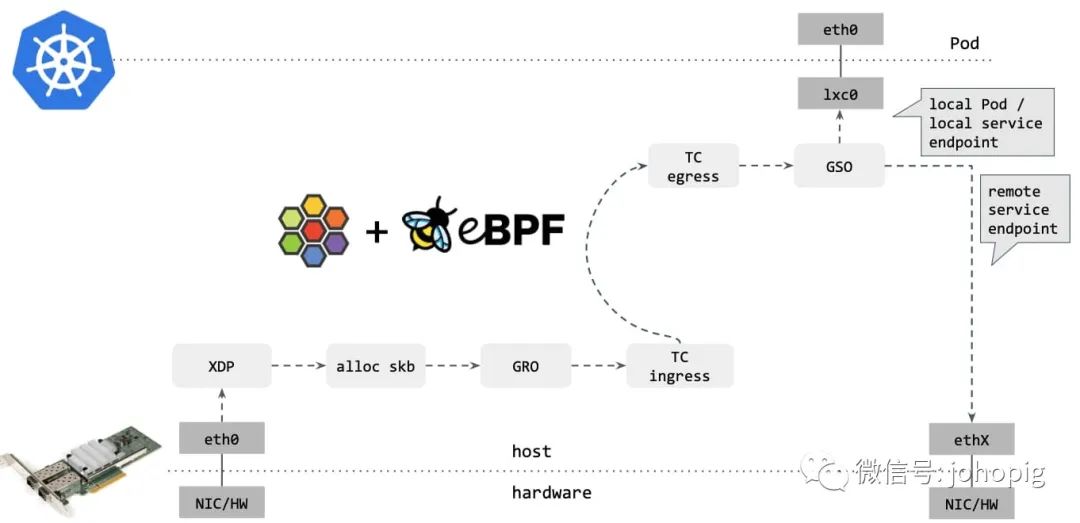
BPF模式
例如k8s的CNI插件Cilium
就使用到了eBPF
。通过将eBPF
字节码规则注入到XDP
中,直接就在最底层对数据包进行处理。对比上面Netfilter
的包转发路径,可以看到省去了很多环节。后续会写其他的文章来介绍这些CNI插件
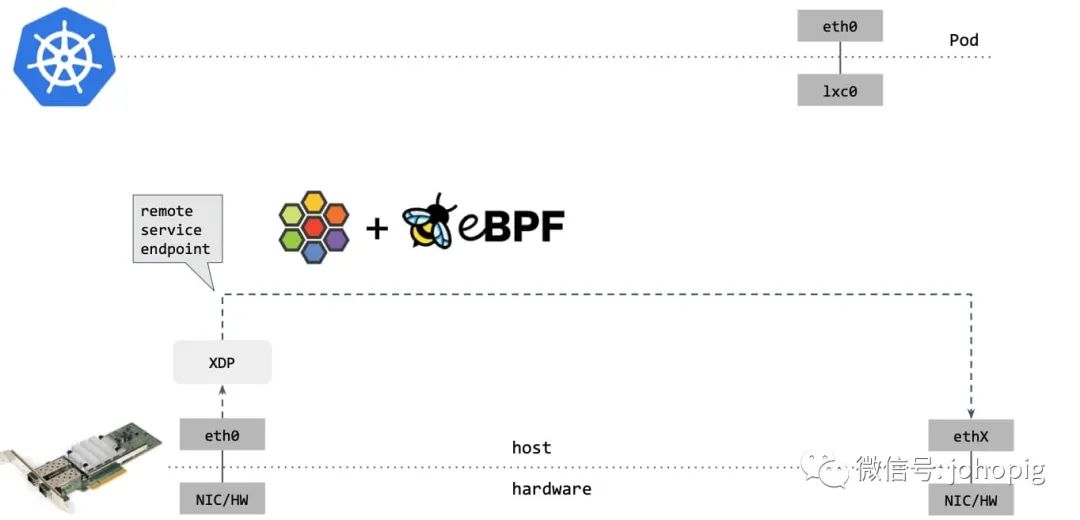
通过XDP
的redirect,如果包的目的端是另一台主机上的 service endpoint,那你可以直接在 XDP 框中完成包的重定向(包转发路径收包1->2
,在步骤 2
中对包 进行修改,再通过 2->1
发送出去),将其发送出去,如下图所示:
Reference
https://cloud.tencent.com/developer/article/1644114?from=article.detail.1470033 https://www.cnblogs.com/jojoword/p/11214256.html#autoid-2-1-0 http://arthurchiao.art/blog/conntrack-design-and-implementation-zh/#15-应用 https://zhuanlan.zhihu.com/p/35616289 https://cloudnative.to/blog/k8s-node-proxy/ https://zhuanlan.zhihu.com/p/130277008 https://draveness.me/whys-the-design-overlay-network/ http://arthurchiao.art/blog/ebpf-and-k8s-zh/
