




目录
多核处理器内存体系
总线锁
缓存一致性(MESI协议)
为什么需要缓存一致性?
MESI
缺点
写缓存
失效队列
内存屏障
前几天面试被问到:当多个线程同时加锁会发生什么?当场懵逼,只回答了会根据标志位来判断是否已经加锁,然后就开始沉默了....
回到家查了一些资料,发现这个问题其实就等于多核CPU对同一内存地址操作时会发生什么?(其实就是在补计组知识😭)
多核处理器内存体系
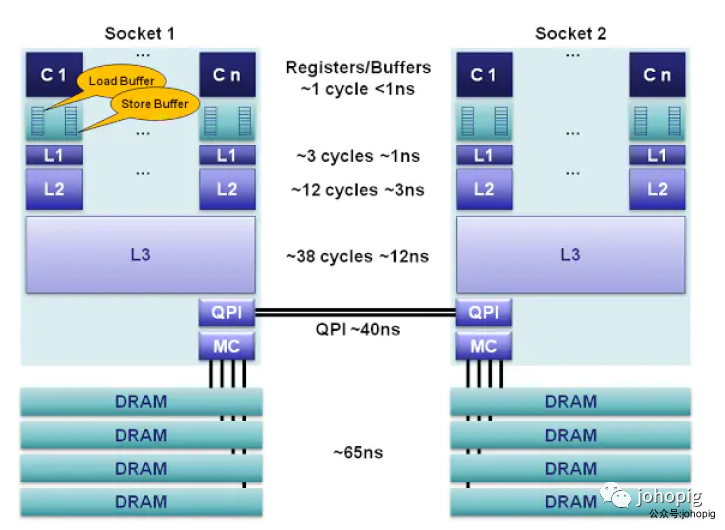
在多处理器系统中,各个核心共享主存,可同时访问主存。但是CPU和物理主存之间的通信速度相对于CPU的处理速度来说是相当慢的,为了能够减少这种消耗,每个CPU都有自己的内部缓存,根据一些额规则将主存中的数据读取到内部缓存中,以加快频繁的读取的速度。寄存器、缓存和主内存构建了内存体系。
寄存器
在每个核心里面,都有寄存器,访问寄存器只需一个时钟周期,这是cpu执行最快的内存区域了。编译器会将本地变量以及函数参数分配在寄存器上面,当使用超线程技术( hyperthreading)时,这些寄存器可以在超线程协同下共享
写缓存(store buffer)
写缓存位于核心和L1 cache之间,是一个FIFO的队列。有store buffer的cpu不会去执行写指令,而是把写指令交给store buffer去操作,cpu接着执行后面的指令(下面会讲到)。
L1缓存
L1缓存是核心本地的一个缓存,被分为32k数据缓存和32k指令缓存,访问需要3个时钟周期
L2缓存
L2缓存也是cpu核心的本地缓存,位于L1和L3缓存之间,其大小为256k,数据和指令同时存储。其主要功能是为L1和L3缓存提供高效的内存队列。L2缓存的延迟需要12个时钟周期
L3缓存
位于同一插槽的核心共享L3缓存,L3拥有L1和L2缓存的数据,虽然浪费了空间,但是拦截了访问核心的L1和L2缓存,减轻了L1和L2的压力
多核时代下并发操作是很正常的现象,操作系统必须要有一些机制和原语来保证某些基本操作的原子性,例如想要保证读写一个字节是原子的,那么就可以有两种机制实现:总线锁定和缓存一致性
总线锁
前端总线(CPU总线)是所有CPU与芯片组连接的主干道,负责CPU与外界所有部件的通信,包括高速缓存、内存、北桥,其控制总线向各个部件发送控制信号,如LOCK#信号,这时,其他CPU就不能操作缓存了该共享变量内存地址的缓存,也就是阻塞了其他CPU,使该处理器可以独享此共享内存。
但是这种操作开销较大,所以提出了下面的做法。
缓存一致性(MESI协议)
为什么需要缓存一致性?
假如说现在有core1和core2两个核心,在主存中存在int a = 0,core1进行写操作a = 1,但是cpu为了提升性能,不会将a=1写到主存,而是直接写到自己的cache(cpu操作主存很慢),core2这时候读取a = 0(主存中a=0),2个core互相观察对方,都是乱序执行的,在core1看来,指令顺序是store load(store是core1自己的写操作 a = 1,load是core2读取主存的操作a = 0),但是在core2看来,指令顺序是load(load是core2自己的读操作,那这里为什么没有core1的写操作?因为core2看不到,core之间只能看到对方对主存的操作),这里的乱序明显对core2造成了影响(没有读到最新的数据)。其实在并发编程里的各种问题,本质上都是指令乱序造成的。缓存一致性就是用来解决这种问题的(其实lock指令也可以解决这种问题,但是lock指令代价太大,其原理是锁住总线,其他cpu全部停止执行,只有当前cpu可以访问内存)
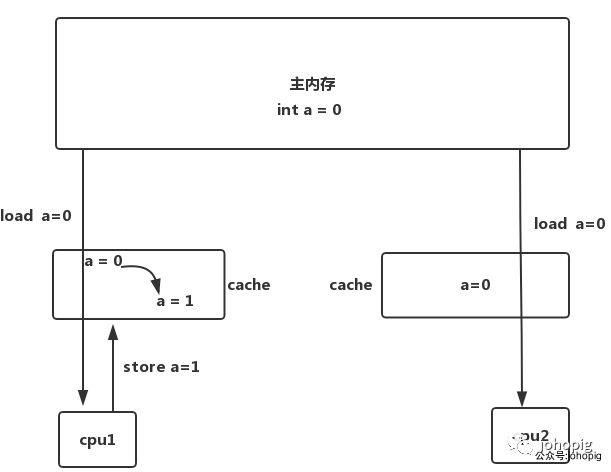
由于写缓存(store buffer)没有及时刷新到内存中,导致不同处理器缓存的值不一样,因此才有 缓存一致性协议来保证足够的可见性又不过多的损失性能(但还是有缺陷:),下面的内容会讲到)
并非所有情况都会使用缓存一致性的,例如被操作的数据不能被缓存在CPU内部或操作数据跨越多个缓存行(状态无法标识),则处理器会调用总线锁定
MESI
缓存一致性协议给缓存行(cache line,通常是64字节)定义了一个状态,用了描述该缓存行是否被多处理器共享、是否修改。所以缓存一致性也被称为MESI协
独占(exlcusive):仅当前处理器拥有该缓存行,并且没有修改过,是最新值。 共享(share):有多个处理器拥有该缓存行,每个处理器都没有修改过缓存,是最新的值。 修改(modified):缓存行被修改过了,需要写回主存,并通知其他拥有者该缓存已失效。 失效(invalid):缓存行被其他处理器修改过,该值不是最新的值,需要读取主存上最新的值。
当CPU需要读取数据时,如果其缓存行的状态是I的,则需要从内存中读取,并把自己状态变成S,如果不是I,则可以直接读取缓存中的值,但在此之前,必须要等待其他CPU的监听结果,如其他CPU也有该数据的缓存且状态是M,则需要等待其把缓存更新到内存之后,再读取。
当CPU需要写数据时,只有在其缓存行是M或者E的时候才能执行,否则需要发出特殊的RFO指令(Read Or Ownership,这是一种总线事务),通知其他CPU置缓存无效(I),这种情况下性能开销是相对较大的。在写入完成后,修改其缓存状态为M。
缺点
编译器为了优化性能,会将变量在寄存器存很长时间,如果要让其他核能够看见该变量,那么变量就不能在寄存器中分配,使用内存屏障可以解决这个问题,而Java的volatile也能保证变量不会在寄存器分配。 如果cpu和cache之间没有store buffer,而是直接由cpu来进行写操作,那么为了满足缓存一致性协议,cpu在写完之后,必须给其他cpu发送缓存失效的消息,然后等待其他core的响应(其他core把缓存改成无效后才响应),这样非常浪费cpu资源。store buffer就是用来解决这个问题的,cpu把写指令交给store buffer,然后接着执行后面的指令。由于store buffer是FIFO的,所以对于store store指令不会进行重排序,但是假如是store load的话,那么就会乱序了,当cpu进行写操作时,将写指令交给store buffer,但是还没有写入cache,那么读操作就不能读到store buffer的最新值了,为了解决这个问题,cpu读操作会从cache和store buffe里面读,那么在同一个core里面的store load操作是没问题的,但是在不同core之间:core1进行写操作,写操作交给core1的store buffer,但是没有写入core1的cache,这个时候core2是不会收到缓存失效的消息的(缓存控制器嗅探不到store buffer),然后core2进行读,这个时候读的就不是最新值了,所以说即使有了缓存一致性协议,也是无法保证并发编程中的的内存可见性的。
处理修改状态是比较耗时的操作,因为既要发送失效信息给其他的拥有者,还要写回主存,还要等待其他拥有者处理失效信息,直到收到失效信息的响应。这一段时间处理器都处于空等的状态,是十分浪费的操作。所以引入了 写缓存(store buffer) 和失效队列(invalid queue) 来让处理器不用“等”
写缓存
存储缓存(Store Buffers),也就是常说的写缓存,当处理器修改缓存时,把新值放到存储缓存中,处理器就可以去干别的事了,把剩下的事交给存储缓存(解决了处理器干等的问题)。属于FIFO操作,能够保证指令不会重排序
失效队列
因为当store buffer满的时候,cpu还是需要去等待其他core的invalid响应,所以添加了失效队列。
处理失效的缓存也不是简单的,需要读取主存。并且存储缓存也不是无限大的,那么当存储缓存满的时候,处理器还是要等待失效响应的。为了解决上面两个问题,引进了失效队列。
WorkFlow
收到失效消息时,放到失效队列中 为了不让处理器久等失效响应,收到失效消息需要马上回复失效响应 为了不频繁阻塞处理器,不会马上去读主存和设置缓存行状态为invalid,而是会在合适的时候再一块去处理失效队列
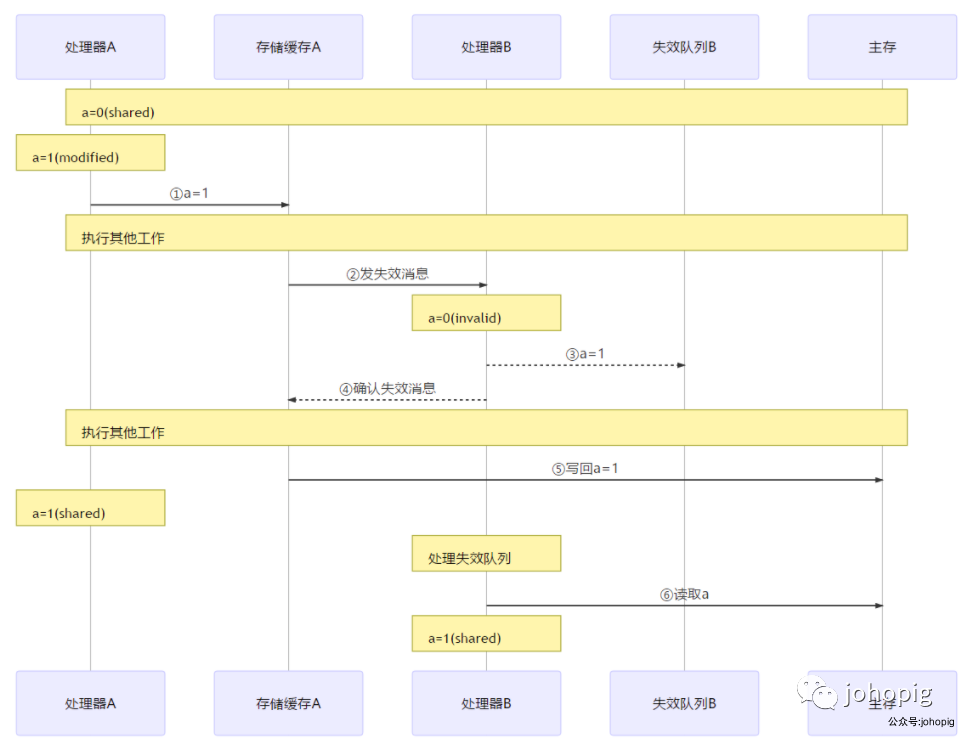
我们可以看到,即使遵守了缓存一致性协议,也还是无法保证内存可见性(1⃣️-6⃣️),所以还需要配合下面讲到的内存屏障
内存屏障
大部分处理器都会提供以下3种内存屏障:
store barrier:用来保证写操作会被其他core看到,仅仅保证写操作,以阻塞的方式 load barrier:用于保证读到最新的数据,仅仅保存读操作,以阻塞的方式 full barrier:保证指令之后的读写操作不会重排序到指令之前,以阻塞的方式
Intel x86架构下的实现为:
sfence:写屏障指令,保证store store操作不会乱序 lfence:读屏障指令,保证load load操作不会乱序(刷新invalid queue) mfence:读写屏障指令,防止读写操作之间重排序,性能相对lfence和sfence来说差很多
可以看到内存屏障可以阻止内存系统重排序,保证可见性。但其开销也很大,处理器需要阻塞等待,所以一般应用在锁的获取和释放中
由此,我们知道了多个线程同时获取锁,其实底层会提供一些原语来保证多核CPU并发操作同一内存地址时的一致性,及通过总线锁或是缓存锁(LOCK指令和缓存一致性)。
