




点击上方 网络技术干货圈,选择 设为星标
优质文章,及时送达

Nosql概述
随着web2.0的快速发展,非关系型、分布式数据存储得到了快速的发展,它们不保证关系数据的ACID特性(原子性、一致性、隔离性、持久性,一个支持事务的数据库,必需要具有这四种特性,否则在事务过程当中无法保证数据的正确性)。NoSQL概念在2009年被提了出来。NoSQL最常见的解释是“non-relational”,“Not Only SQL(不仅仅是sql)”也被很多人接受(“NoSQL”一词最早于1998年被用于一个轻量级的关系数据库的名字)。
NoSQL被我们用得最多的当数key-value存储,当然还有其他的文档型的、列存储、图型数据库、xml数据库等。在NoSQL概念提出之前,这些数据库就被用于各种系统当中,但是却很少用于web互联网应用。比如cdb、qdbm、bdb数据库。
1、单机时代Mysql
传统的关系数据库具有不错的性能,高稳定型,久经历史考验,而且使用简单,功能强大,同时也积累了大量的成功案例。在互联网领域,MySQL成为了绝对靠前的王者,毫不夸张的说,MySQL为互联网的发展做出了卓越的贡献。
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。在那个时候,更多的都是静态网页,动态交互类型的网站不多,对服务器根本没有太大的压力
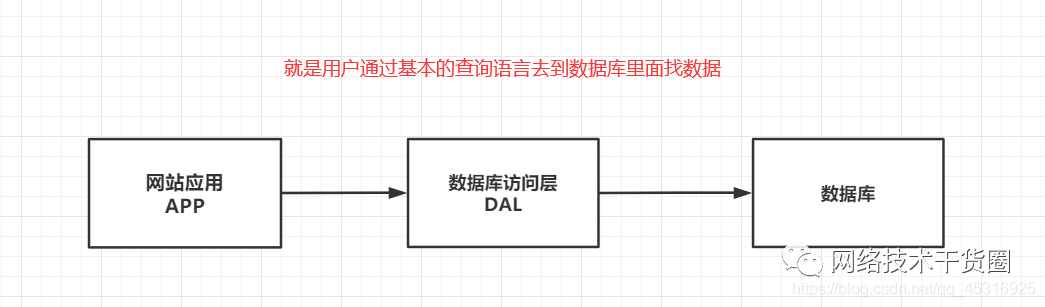
传统关系数据库的瓶颈
数据量如果太大,一个数据库放不下 如果数据量过大就需要建立索引,但是大量的索引,一个机器内存也放不下 访问量过大(就是读写都是在这个库里面实现的),一个服务器承受不了
到了最近10年,网站开始快速发展,随着访问量的上升,几乎大部分使用MySql架构的网站在数据库上都出现性能问题!
2、Memcached(缓存)+ Mysql + 垂直拆分
出现了性能问题之后,程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。
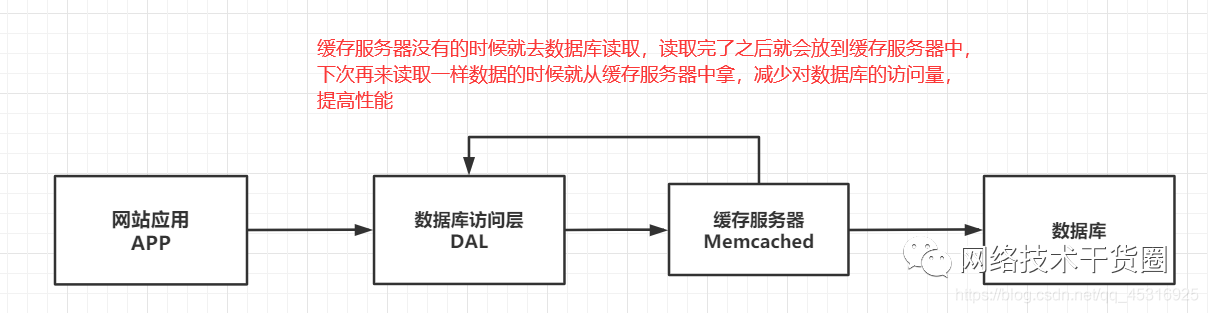
开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带了了比较高的IO压力。 在这个时候,Memcached就自然的成为一个非常时尚的技术产品。
Memcached作为一个独立的分布式的缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务,在Memcached服务器上,又发展了根据hash算法来进行多台Memcached缓存服务的扩展,然后又出现了一致性hash,在增加 或 减少 的时候 缓存服务器导致重新hash带来的大量缓存失效的弊端。
垂直拆分:
在数据库分表分库原则中,遵循二个设计理论 垂直拆分、水平拆分。垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。
垂直拆分就是根据不同的业务进行拆分的,拆分成不同的数据库,比如会员数据库、订单数据库、支付数据库、消息数据库等,垂直拆分在大型电商项目中使用比较常见。
优点:拆分后业务清晰,拆分规则明确,系统之间整合或扩展更加容易。
缺点:几乎完全重复的轮子,难于维护。部分业务表无法join,跨数据库查询比较繁琐(必须通过接口形式通讯(http+json))、会产生分布式事务的问题,提高了系统的复杂度。举例子:不可能出现,在订单服务中,订单服务直接连接会员服务的数据库这种情况。
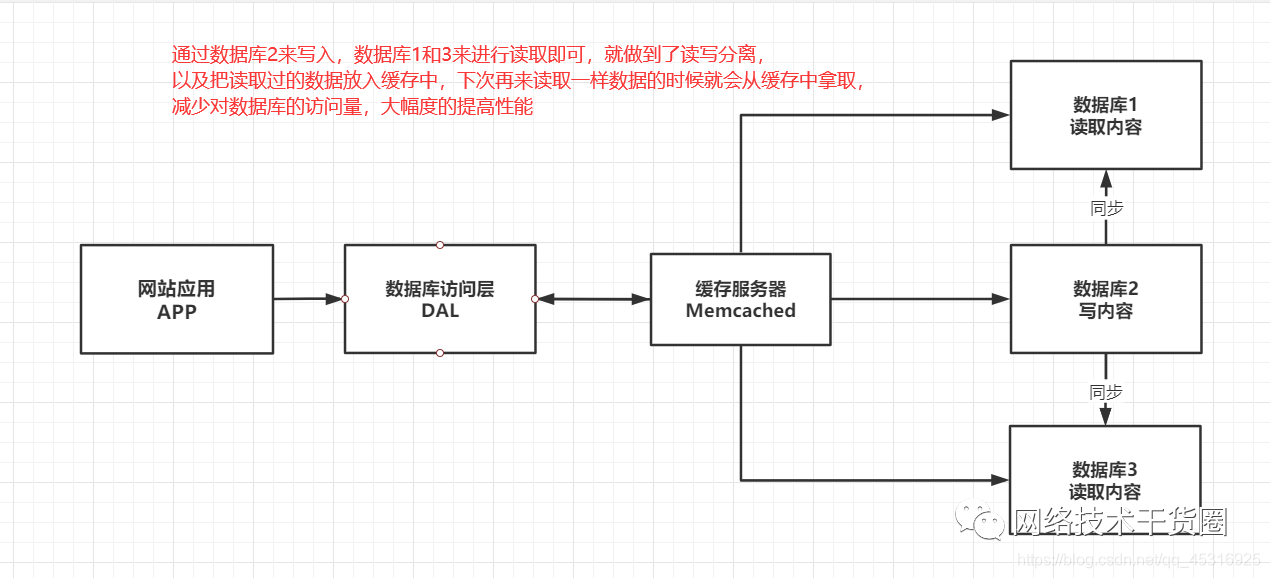
3、Mysql主从读写分离
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为这个时候的网站标配了。
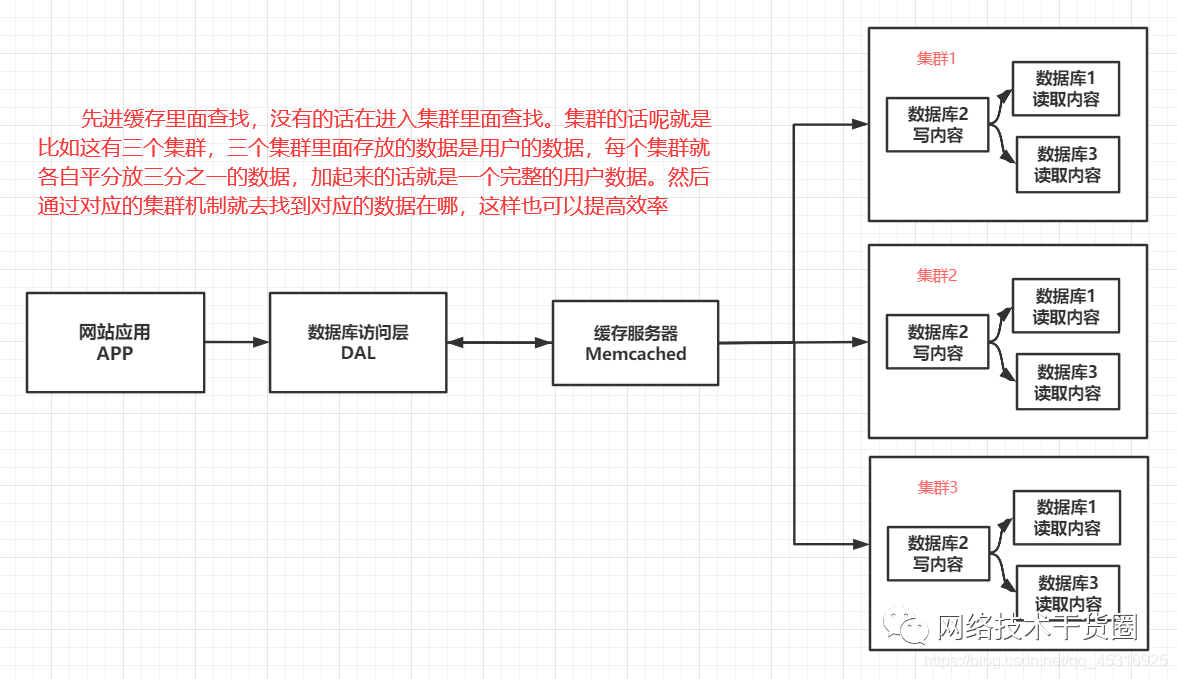
4、分表分库+水平拆分+mysql集群
随着web2.0的继续高速发展,在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁(比如我查询一条数据,但是这个表里面有一百万条数据,然后就去锁住那条数据的那个表,剩下的进程由于加锁了就只能等待那条数据查询出来,就十分的影响效率),在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB(行锁,行锁就是每次查询只锁当前查询的数据那一行)引擎代替MyISAM。同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。
分库分表:
字面意思就是:
分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。 分表:从单张表拆分成多张表的过程,将数据散落在多张表内。
分库分表的作用就是提升性能、增加可用性。
比如一个数据9000万,如果只挂在一张表上,不管如何优化都会很慢。但如果分库分表,将1-3000,3001-6000,6001-9000分别进入三个库,这样数据库的压力就减轻了。
水平拆分:
在数据库分表分库原则中,遵循二个设计理论 垂直拆分、水平拆分。垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。
水平拆分就是把同一张表中的数据拆分到不同的数据库中进行存储、或者把一张表拆分成 n 多张小表。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式 该方式提高了系统的稳定性跟负载能力,但是跨库join性能较差。’
优点:不同业务,往往性能要求,以及请求量是不一样的。拆分后保证业务之间的可用性影响最小化。
缺点:拆分过程中,多个系统中可能存在重复的轮子,难于维护
mysql集群:
MySQL Cluster 是一组计算机构成,适合于分布式计算环境的高实用、高冗余版本。它采用了NDB Cluster 存储引擎,允许在1个 Cluster 中运行多个MySQL服务器。
MySQL集群是一个无共享的、分布式节点架构的存储方案,其目的是提供容错性和高性能。
数据更新使用读已提交隔离级别来保证所有节点数据的一致性,使用两阶段提交机制保证所有节点都有相同的数据(如果任何一个写操作失败,则更新失败)。无共享的对等节点使得某台服务器上的更新操作在其他服务器上立即可见。传播更新使用一种复杂的通信机制,这一机制专用来提供跨网络的高吞吐量。通过多个MySQL服务器分配负载,从而最大程序地达到高性能,通过在不同位置存储数据保证高可用性和冗余。
NDB 引擎: MySQL Cluster 使用了一个专用的基于内存的存储引擎——NDB引擎,这样做的好处是速度快, 没有磁盘I/O的瓶颈,但是由于是基于内存的,所以数据库的规模受系统总内存的限制, 如果运行NDB的MySQL服务器一定要内存够大,比如4G, 8G, 甚至16G。NDB引擎是分布式的,它可以配置在多台服务器上来实现数据的可靠性和扩展性,理论上 通过配置2台NDB的存储节点就能实现整个数据库集群的冗余性和解决单点故障问题。
5、Mysq的l性能瓶颈
在互联网,大部分的MySQL都应该是IO密集型的,Mysql的扩展性差,大数据下IO压力大,表结构更改困难(比如你的表里面有一条亿数据,这时候你添加个字段,或者修改字段,就需要修改或者添加一亿条记录),正是当前使用Mysql的开发人员面临的问题。
6、目前一个基本的互联网项目
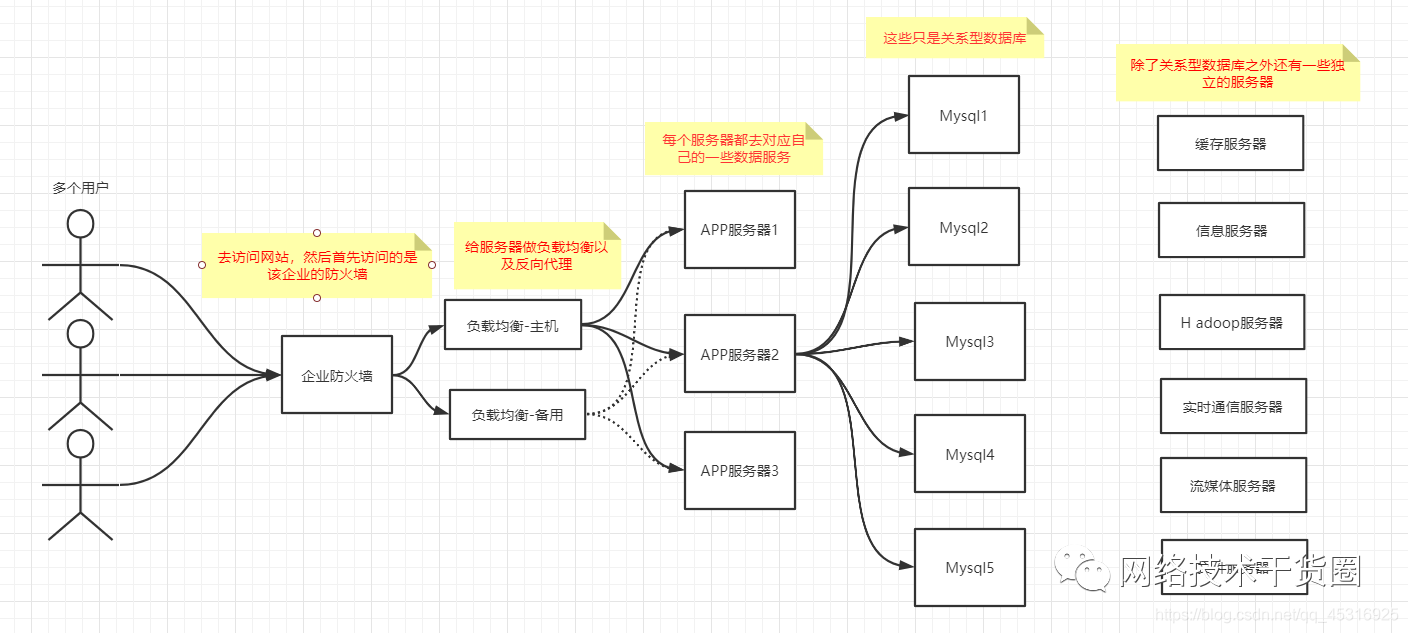
什么是Nosql
NoSql = not only sql 不仅仅是sql
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
关系型数据库:
关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。用户通过查询来检索数据库中的数据,而查询是一个用于限定数据库中某些区域的执行代码。关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织
为什么使用Nosql
很多网站现在都可以很容易的访问和抓取数据,例如用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加,我们如果要对这些用户数据进行挖掘,那么SQL数据库已经不合适这些应用了,NoSQL数据库的发展能很好的处理这些大的数据
NoSql的优势
易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
大数据量,高性能
NoSQL数据库都具有非常高的读写性能(Redis 一秒写8万次,读取11万),尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache,每次表的更新 Cache就失效,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了。
灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系型数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。这点在大数据量的web2.0时代尤其明显。
高可用
NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra(流行的分布式结构化数据存储方案),HBase模型(它是一个适合于非结构化数据存储的数据库),通过复制模型也能实现高可用。
传统RDBMS(关系型数据库) VS NOSQL(非关系型数据库)
传统RDBMS(关系型数据库) - 高度组织化结构化的数据 - 结构化查询语句sql - 数据和关系都存储在单独的表中 - 数据操控语言,数据定义语言 - 严格的一致性, 基础事务 NOSQL(非关系型数据库) - 代表不仅仅是数据 - 没有声明性查询语言 - 没有预定义的模式 - 键值对存储(Redis), 列存储(HBase), 文档存储(MongoDB), 图形数据库 - 最终一致性, 非acid属性 - cap定理 - 高性能, 高可用, 可伸缩性
各种NoSql间的对比
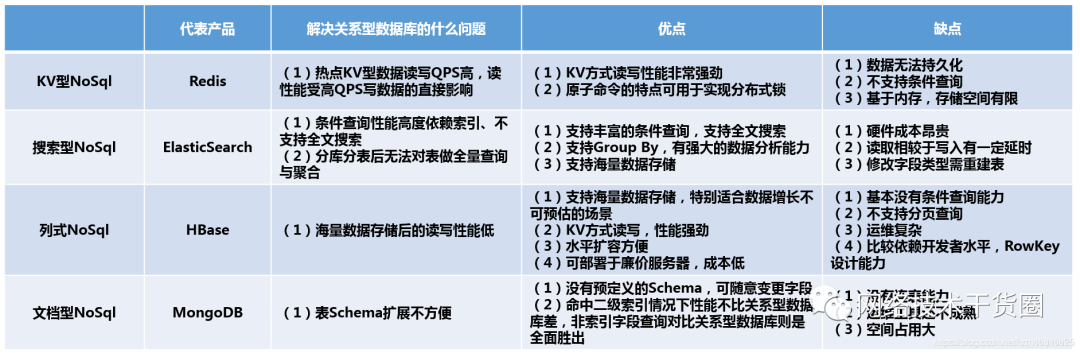
NoSql的四大分类
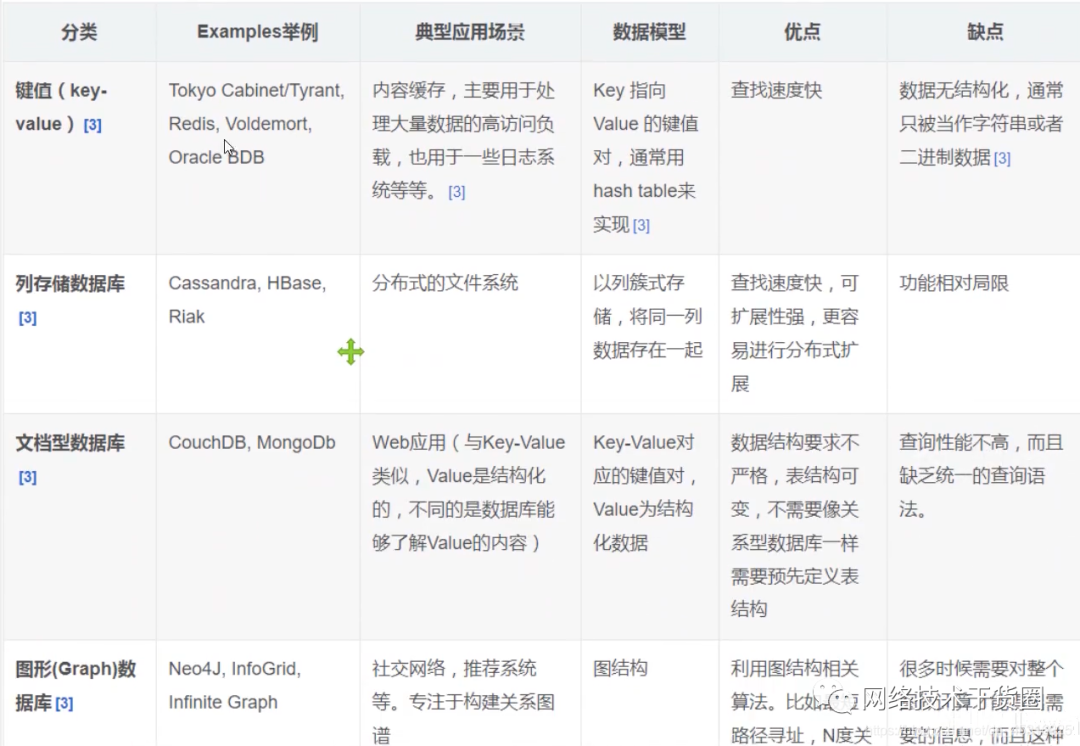
KV键值对:
新浪:Redis 美团:Redis + Tair 阿里、百度:Redis + memecache
文档型数据库(bson格式 和 json一样):
MongoDB MongoDB是一个基于分布式文件存储的数据库,使用C++编写,主要用来处理大量的文档! MongoDB是一个介于关系型数据库和非关系型数据库中间的产品!MongoDB是非关系型数据库中功能最丰富,最像关系型数据库的! ConthDB
列存储数据库:
HBase 分布式文件系统
图关系数据库:
他不是存图形,放的是关系,比如:朋友圈社交网络,广告推荐!
Neo4j,InfoGrid
列存储数据库:
HBase 分布式文件系统
图关系数据库:
他不是存图形,放的是关系,比如:朋友圈社交网络,广告推荐!
Neo4j,InfoGrid
四者对比

Docker常用命令大集合,收藏后血赚!

Linux常用命令,特别适合小白哦

什么是5G专用网络?为什么它更具有吸引力?

对链路聚合Eth-Trunk最佳总结,非本文也!
---END---
重磅!网络技术干货圈-技术交流群已成立
扫码可添加小编微信,申请进群。 一定要备注:工种+地点+学校/公司+昵称(如网络工程师+南京+苏宁+猪八戒),根据格式备注,可更快被通过且邀请进群

▲长按加群
Docker常用命令大集合,收藏后血赚!
Linux常用命令,特别适合小白哦
什么是5G专用网络?为什么它更具有吸引力?
对链路聚合Eth-Trunk最佳总结,非本文也!

