




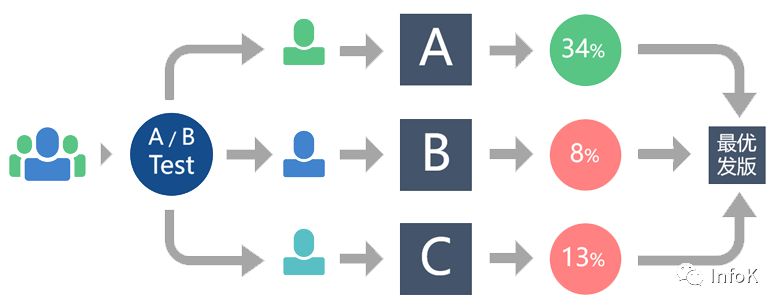
互联网效果广告的主要特点之一是可量化,即广告系统的所有业务指标都是可以计算并通过数字进行展示的。因此,想要通过业务指标来表示广告系统的迭代效果。在全量上线前确认迭代的结果,通用的方法是采用AB实验(如下图)。
A/B实验的本质是分离式组间试验,也叫对照试验,在科研领域中已被广泛应用(它是药物测试的最高标准)。自2000年谷歌工程师将这一方法应用在互联网产品以来,A/B测试在国外越来越普及,已逐渐成为互联网产品运营精细度的重要体现。
简单来说,A/B测试在产品优化中的应用方法是:在产品正式迭代发版之前,为同一个目标制定两个(或以上)方案,将用户流量对应分成几组,在保证每组用户特征相同的前提下,让用户分别看到不同的方案设计,根据几组用户的真实数据反馈,科学的帮助产品进行决策。(如下图)
先验性:A/B测试其实是一种“先验”的试验体系,属于预测型结论,与“后验”的归纳性结论差别巨大。同样是用数据统计与分析版本的好坏,以往的方式是先将版本发布,再通过数据验证效果,而A/B 测试却是通过科学的试验设计、采样样本代表性、流量分割与小流量测试等方式来获得具有代表性的试验结论,这样就可以用很少的样本量就能推广到全部流量可信。
A/B 测试的使用误区
误区一:轮流展现不同版本
首先需要明确,这种做法不是真正意义上的A/B测试。而这一现象,经常出现在如今的广告投放的环节。广告主为了提升着陆页的转化率,会选择将不同的广告版本进行轮流投放展示。但这一做法并不能保证每个版本所处的环境相同,例如选在工作日的晚七点黄金档和下午三点时段,受众群体会有明显区别,以至于最终效果是否有差异,甚至导致效果不同的原因是很难下定论的。
误区二:选择不同应用市场投放(随机选取用户测试)
正确做法: 科学的进行流量分配,保证每个试验版本的用户特征相类似。
误区三:让用户自主选择版本
误区四:对试验结果的认知和分析过浅
其二,单从试验的整体数据结果,就推论所有场景的表现效果。例如,当A/B测试的结果表明试验版本的数据差于原始版本时,就认定所有的地区或渠道的效果都是负面的。但如果细分每个版本中不同浏览器的数据,可能会发现:由于某一浏览器的明显劣势,导致整体试验数据不佳。因此,不要只专注于试验数据的整体表现,而忽略了细分场景下可能导致的结果偏差。
正确做法: 在分析试验整体数据的同时,需要从多个维度细分考量试验数据结果。
