




声明:文章是网上看到的,作者不详,仅仅整理成更好的格式供学习参考之用!不作为其他用途目的!
Oracle的块清除有两种:
数据库块的最前面有一个“开销”空间(overhead),这里会存放该块的一个事务表,对于锁定了该块中某些数据的各个“实际”事务,在这个事务表中都有一个相应的条目。
COMMIT时候Oracle需要将回滚段上的事务表信息标记为非活动,以便空间可以重用;此外所做的一个操作是块清除(Block cleanout),如果事务修改的某些块还在缓冲区缓存中,会清除块首部的ITL事务信息(包括提交标志、SCN等)和锁定信息。
在与我们的事务相关的提交列表中,Oracle会记录已修改的块列表(每个列表可以有20个块指针),Oracle会根据需要分配多个这样的列表,直至达到某个临界点。如果我们修改的块加起来超过了块缓冲区缓存大小的10%,Oracle 会停止为我们分配新的列表。例如,如果缓冲区缓存设置为可以缓存3,000个块,Oracle 会为我们维护最多300个块。
COMMIT时,Oracle会通过这些列表找到块,如果块仍在块缓冲区中,Oracle会执行一个很快的清理,这叫做 快速块清除(FAST BLOCK CLEANOUT)。
所以,只要我们修改的块数没有超过缓存中总块数的10%,而且块仍在块缓存区中(如果已经被写回到数据文件上再次读出该数据块进行修改成本过于昂贵),Oracle就会在COMMIT时清理这些块。否则,就会延迟块清除到下次访问该块的时候。通过延迟块清除(DELAYED BLOCK CLEANOUT)可以提高数据库的性能,加快提交操作。
所以如果执行一个大的INSERT、UPDATE或DELETE,影响数据库中的许多块,就有可能在此之后,第一个“接触”块的查询会需要修改某些块首部并把块弄脏,生成REDO日志,会导致DBWR把这些块写入磁盘。 (--所以说select 语句也有可能会产生redo日志)
如果Oracle不对块完成这种延迟清除,那么COMMIT的处理可能很长,COMMIT必须重新访问每一个块,可能还要从磁盘将块再次读入(它们可能已经刷新输出)。
在一个OLTP系统中,可能从来不会看到这种情况发生,因为OLTP系统的特点是事务都很短小,只会影响为数不多的一些块。
如果你有如下的处理,就会受到块清除的影响:
比较好的做法是:在批量加载了数据后,通过运行DBMS_STATS实用程序来收集统计信息,就能自然的完成块清除工作。

如果在一个查询(时间较长的查询)开始后,对表进行了dml操作,因为oracle的一致性读,那么查询就需要用到相应的回滚数据。但是因为查询的时间较长,在我们需要用那些回滚段来构造cr块时发现回滚段已经被其他数据覆盖了。这样就会报oracle-01555错误!
比较直观的解决方法是DBA告诉数据库应用最长的查询需要多长时间,并把UNDO_RETENTION设为这个值,同时相应增大undo表空间大小。
在此我给大家稍微介绍一下orale中UNDO_RETENTION这个参数。oracle回滚段中区有四种状态 active,inactive,expired,free
active表示事物还在活动;
inactive表示事物已提交(区可用但是尽量避免使用);
expired表示undo区可以被覆盖;
free表示空闲的区
这里我们主要关注一下inactive和expired两个状态的区别
inactive表示事物已经提交,理论上此时区已经可以被重新使用,但是因为oracle的一致性读,所以我们可能还需要把inactive区中的数据再保留一段时间,保留多长时间由UNDO_RETENTION参数决定。在保留了UNDO_RETENTION时间后,区的状态就改成expired。 (--注意如果一个事物需要用回滚段,而回滚表空间中此时已经没有free,和expired状态的区,那么就算inactive区没有被保留够UNDO_RETENTION时间,也是可以被使用的)
这种情况比较少见,特别是在OLTP系统里,在OLAP系统里可能会碰到,解决方法是在每次大量的insert或update之后,记得用DBMS_STATS包扫描相关对象。
前面我已经说了为什么会有延时块清除,主要是为了提高事物的效率!
延迟清除的块的下一个读者,首先根据块中的记录的回滚信息去查找回滚段中记录的commit时的SCN,但回滚段可能已回绕,找不到提交时的scn了,但是,从回滚段中可以得到一个最小的提交scn并且该事务已经提交肯定小于这个从回滚段中还存在的最小scn。那么oracle给这个块清除的事务分配一个从回滚段中找到的最小事务scn。这虽然不准确,但是是安全的,对于数据访问也不构成影响。所以叫 upper bound ,猜测的一个scn的上限。
延迟清除的块在被select 时,如果读的select 的scn 比这个回滚段里面最小的scn 还要小的话(回滚段已回绕),那么在回滚段里面找不到数据了,oracle 就没有办法判断select 的SCN 与被要清除的数据块的大小关系,于是ora-01555就出现了,这个时候oracle 就不知道数据块里面的数据是不是是查询时刻需要的数据.
如果select scn 大于回滚段里面最小的scn 的话,那么oracle 就使用这个最小的scn 来做为这个事务的 scn 来更新块的itl ,从而完成块的清除.
上面的描述有点绕,下面是我总结的一个非常直观的理解:
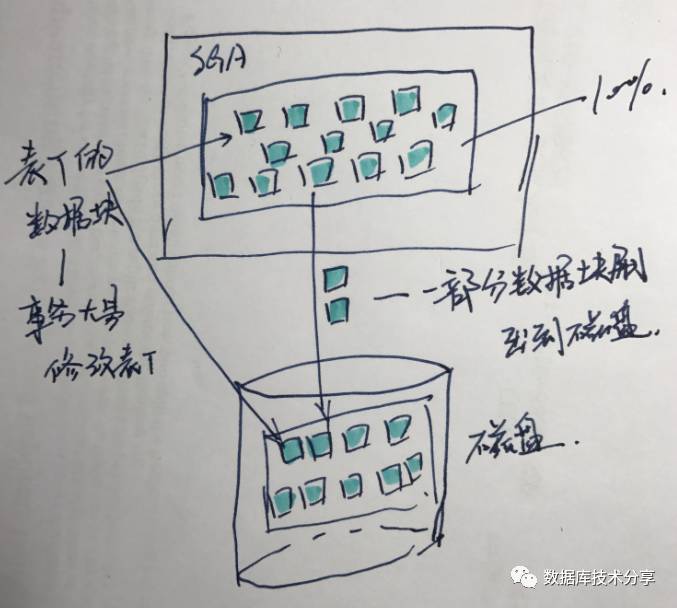
图 1
如上图所示,
(1)有事务大量修改了T表的数据,或者A表的数据虽然被事务少量修改,但是一部分(超过内存10%的块)修改过的块已经刷出内存并写到了磁盘上。随即事务提交,提交时刻为SCN1。而提交时写到磁盘的数据块上的事务没有被清除(延迟块清除)。

图 2
(2)在SCN2 时间点,开始了一个select查询语句,假如SCN2与SCN1之间间隔比较长,也就是关于T表之前的undo信息全部被重用,所以找不到commit时刻的准确SCN(SCN3<>SCN1),此时oracle会从undo段中找一个最小的SCN(如SCN3),因为undo已经重用,所以即使是undo中最小的SCN3也是大于SCN1的(如图),oracle会把SCN3分配给块清除事务进而完成块清除。这时有两种情形:
ORA-01555 “Snapshot too old” – Detailed Explanation [ID 40689.1] 文章见下一篇文章
