




ApplicationExecution in Flink
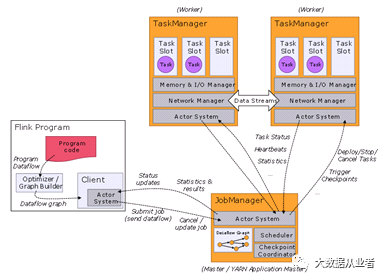
Flink应用程序执行涉及三个实体:Client、JobManager和TaskManagers。Client负责向集群提交应用程序,JobManager负责执行过程中必要的调度管理,Taskmanager负责实际的计算。
Flink在1.11版本中引入Application模式之前,Flink允许用户以Session或Per-Job模式执行应用程序。两者之间的差异主要在于集群生命周期、资源隔离。
Session Mode
该模式使用一个已经运行的集群来执行所有提交的应用程序。该集群中执行的应用程序竞争使用该集群的资源。这样做的好处是,不必为每个提交的作业启动一个集群,额外增加资源开销。但是,该模式下,如果集群中的一个作业行为不正常或导致TaskManager宕机,则在该TaskManager上运行的所有作业都将受到故障的影响。也就是说,一个作业也会影响其他作业可能导致大规模的重启。所有重新启动的作业都会同时访问文件系统,可能导致其他服务无法使用该文件系统。此外,让单个集群运行多个作业意味着JobManager的负载更大。该模式适合于对启动延迟要求较高且运行时间较短的作业,例如交互式查询。
Per-Job Mode
该模式下,集群管理框架(例如YARN或Kubernetes)会为每个提交的作业启动一个单独Flink集群,该集群仅对该作业可用。作业运行完成,集群将被关闭,所有用到的资源(例如文件)也将被清理。此模式提供更好的资源隔离。一个作业故障不会影响其他作业的运行。此外,由于每个作业都有自己的JobManager,负载被分散到多个实体上。考虑到Session模式的资源隔离问题,对于需要长时间运行的作业,通常选择Per-Job模式,这些作业愿意承受增加启动延迟以提升作业的恢复能力。
总之,在Session模式下,集群生命周期独立于集群上运行的任何作业,并且集群上运行的所有作业共享集群资源。Per-Job模式为每个提交的作业启动一个集群,以提供更好的资源隔离保证。在这种情况下,集群的生命周期与作业的生命周期绑定。
Application Submission
Flink应用程序执行包括两个阶段:调用main()方法时的pre-flight(即准备阶段);调用execute()方法时的runtime(即运行阶段)。main()方法使用Flink API(如:DataStreamAPI、Table API、DataSet API)构造应用程序。当main()方法调用env.execute()时,应用程序被转换成Flink运行时能理解的形式,即jobgraph,并被发送到集群。Session模式和Per-Job模式都在客户端执行应用程序的main()方法,即准备阶段。对于单个用户在已经有作业所有依赖的客户机上提交应用程序来说,这通常不是问题。
但如果通过远程实体(Deployer)提交,此过程包括:在本地下载应用程序的依赖项,执行main()方法来提取job graph,将job graph及其依赖发送到集群执行,等待结果。这一系列过程使得客户机资源消耗高,因为它可能需要大量的网络带宽来下载依赖,并将二进制文件发送到集群,以及CPU周期来执行main()方法。随着越来越多的用户共享相同的客户机,这个问题将更加明显。
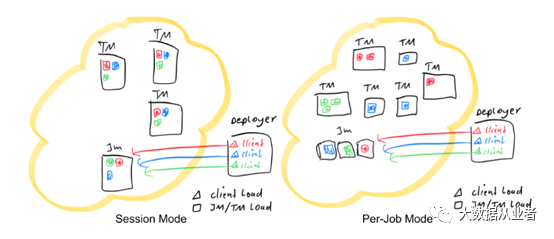
上图展示了3个应用程序分别以两种部署模式提交,分别用红色、蓝色和绿色表示。每个作业的平行度为3。黑色矩形表示不同的进程:TaskManagers、JobManagers和Deployer;假设在所有场景中都有一个Deployer流程。彩色三角形表示提交进程的负载,而彩色矩形表示TaskManager和JobManager进程的负载。如图所示,Session模式和Per-Job模式下,Deployer有相同的负载,区别在于tasks分布和JobManager负载。在Session模式下,集群中的所有作业共用一个JobManager,而在Per-Job模式下,每个作业都有一个JobManager。此外,Session模式下的tasks随机分配给TaskManager,而在Per-Job模式下,每个TaskManager只能有单个作业的tasks。
Application Mode
Application模式将Per-Job模式的资源隔离与轻量级、可扩展的作业提交过程结合起来。Application模式为每个提交的作业创建一个集群,但作业的main()方法将在JobManager上执行,以节省提取job graph所需的CPU周期,也节省客户端下载依赖及将job graph及其依赖关系传送到群集所需的带宽。
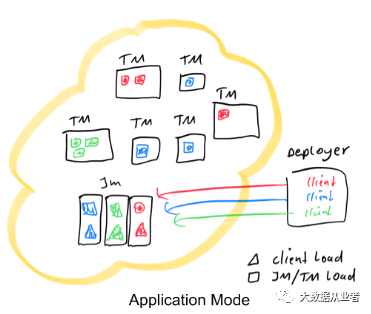
上图说明了这一点,与Session模式和Per-Job模式部分相同的场景,但这次客户端负载已转移到每个应用程序的JobManager。
注意:在Application模式中,main()方法是在集群上执行而不是在客户机。这可能会影响代码,例如使用registerCachedFile()注册路径都必须保证JobManager能够访问。
与Per-Job模式相比,Application模式允许提交由多个作业组成的应用程序。作业的执行顺序不受部署模式的影响,而是由调用顺序控制。使用blocking execute()方法建立一个顺序,将导致“next”作业的执行推迟到“this”作业完成。相反,non-blocking executeAsync()方法将在提交当前作业后立即继续提交“下一个”作业。
Reducing Network Requirements
Application模式下,客户机仍然需要将用户jar发送到JobManager。提交每个应用程序,客户机必须向集群发送“flink dist”目录,包括flink-dist.jar,lib/和plugin/目录等,占用客户端大量带宽。此外,每次提交应用程序时,都发送相同的flink dist二进制文件,不仅浪费带宽,还浪费存储空间。如果每个应用程序共享相同的flink dist二进制文件就可以避免这种浪费。Flink 1.11引入了一些选项,允许用户指定一个远程目录,YARN可以通过该目录找到Flink二进制文件和用户jar文件。利用YARN的分布式缓存,允许应用程序共享这些二进制文件。因此,如果一个应用程序碰巧在其TaskManager的本地存储中发现了Flink的副本,那么它不必下载它。
Example: ApplicationMode on Yarn
Application模式下,提交应用程序,命令如下:
./bin/flink run-application -tyarn-application./MyApplication.jar复制
也可以通过-D传入一些配置项,命令如下:
./bin/flink run-application -t yarn-application \-Djobmanager.memory.process.size=2048m \-Dtaskmanager.memory.process.size=4096m \./MyApplication.jar复制
为进一步节省将Flink jar发送到集群的带宽,可以将Flink jar预上传到YARN能访问的远程存储(如:hdfs),通过使用yarn.provided.lib.dirs配置项实现,如下所示:
./bin/flink run-application -t yarn-application \-Djobmanager.memory.process.size=2048m \-Dtaskmanager.memory.process.size=4096m \-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \./MyApplication.jar复制
最后,为进一步节省提交应用程序jar所需的带宽,同样可以将其预上传到HDFS,提交应用程序时指向远程路径/MyApplication.jar即可,如下所示:
./bin/flink run-application -t yarn-application \-Djobmanager.memory.process.size=2048m \-Dtaskmanager.memory.process.size=4096m \-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \hdfs://myhdfs/jars/MyApplication.jar复制
通过以上步骤,使作业提交变得格外轻量级,所需的Flink jar和应用程序jar从指定的远程位置获取,而不是由客户机传送到集群。客户机传送到集群的唯一内容是应用程序的配置。
Conclusion
我们希望本次讨论能帮助您理解Flink提供的各种部署模式之间的差异,并帮助您做出明智的选择,确定哪种部署模式适合您自己的设置。
评论

 0 点赞
0 点赞 1 1
1 1


