




 文章转自作八怪(高鹏) 中亦科技数据库专家
文章转自作八怪(高鹏) 中亦科技数据库专家
原文:https://www.jianshu.com/p/39db1bb5041c
一、问题来源
这是一位客户的提供的案例如下,show processlist截图如下:
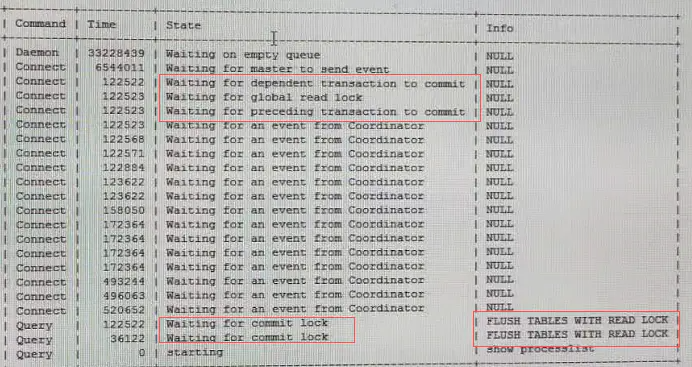
出现这种问题除非手动干预,杀掉FTWRL的session,复制线程方可以继续进行。版本社区版5.7.26。
二、堵塞图
如果分析上面的堵塞可以画图如下:
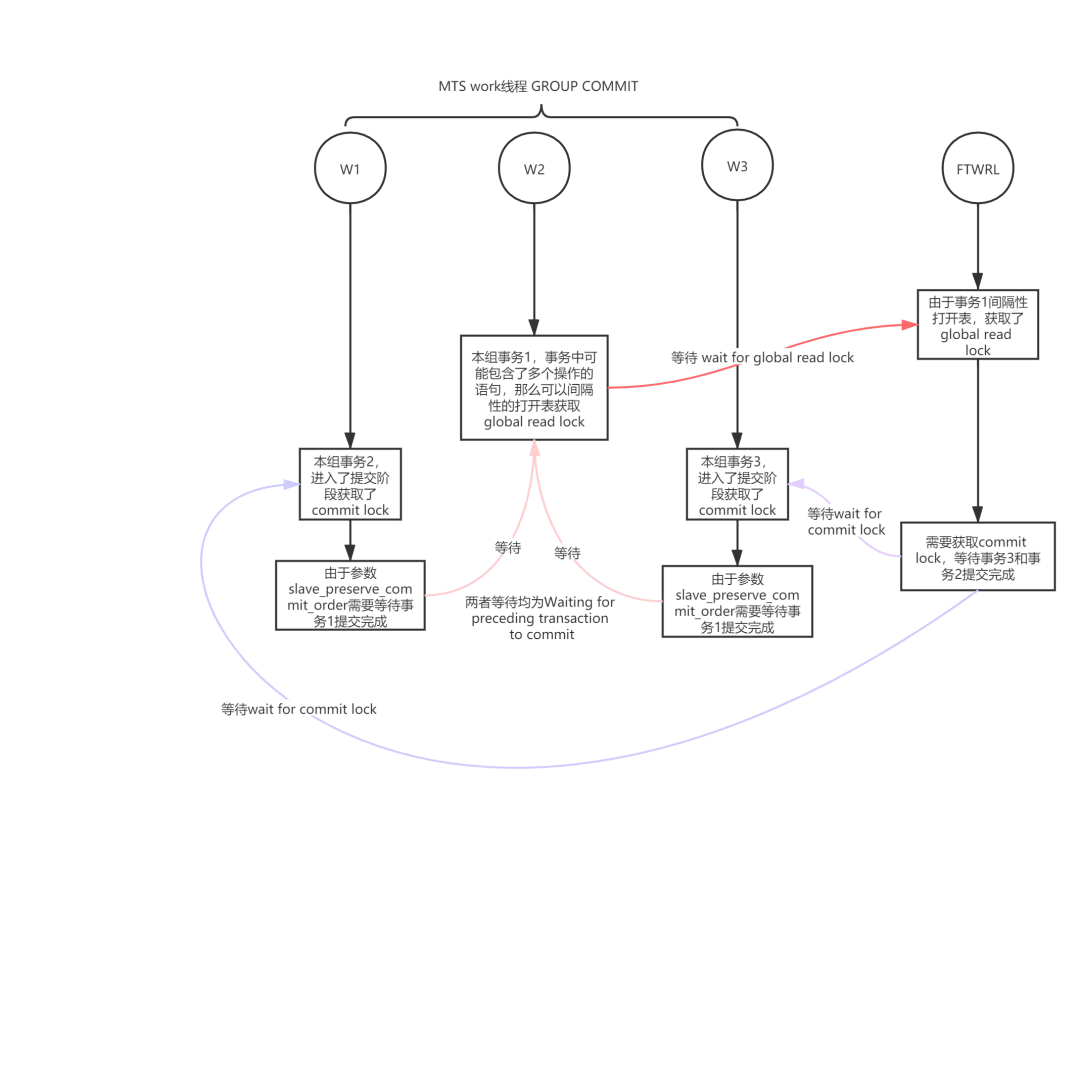
三、关于woker线程w1和w3的等待
这里我们需要重点关注参数 slave_preserve_commit_order,在我将要出版的《深入理解MySQL主从原理》一书中做了详细描述,这里简单说明如下:
这个参数是为了保证从库 group commit 中的每个工作线程的事务提交顺序和主库事务执行的顺序一致。它在 order commit 的flush阶段前就生效。工作线程的事务在等待获取自己提交权限期间会堵塞在状态 ‘Waiting for preceding transaction to commit’ 下。
但是我们知道在order commit的flush之前就会获取 MDL_key::COMMIT。因此这里w1和w3工作线程正在等待自己提交权限的到来,但是遗憾的是w2的事务由于不能获取 global read lock 而迟迟不能提交。同时它们堵塞了FTWRL。
四、关于FTWRL的等待
这个我也多次描述过了,FTWRL的过程大概如下:
第一步: 加MDL LOCK类型为GLOBAL,级别为S。如果出现等待状态为 ‘Waiting for global read lock’。注意select语句不会上GLOBAL级别上锁,但是DML/DDL/FOR UPDATE语句会上GLOBAL级别的IX锁,IX锁和S锁不兼容会出现这种等待。下面是这个兼容矩阵:
| Type of active | Request | scoped lock | type | IS(*) IX S X | ---------+------------------+ IS | + + + + | IX | + + - - | S | + - + - | X | + - - - |复制
第二步: 推进全局表缓存版本。源码中就是一个全局变量 refresh_version++。 第三步: 释放没有使用的table 缓存。可自行参考函数 close_cached_tables。 第四步: 判断是否有正在占用的table缓存,如果有则等待,等待占用者释放。等待状态为 'Waiting for table flush'。这一步会去判断table缓存的版本和全局表缓存版本是否匹配,如果不匹配则等待如下:
for (uint idx=0 ; idx < table_def_cache.records ; idx++) { share= (TABLE_SHARE*) my_hash_element(&table_def_cache, idx); //寻找整个 table cache shared hash结构 if (share->has_old_version()) //如果版本 和 当前 的 refresh_version 版本不一致 { found= TRUE; break; //跳出第一层查找 是否有老版本 存在 } }...if (found)//如果找到老版本,需要等待 { /* The method below temporarily unlocks LOCK_open and frees share's memory. */ if (share->wait_for_old_version(thd, &abstime, MDL_wait_for_subgraph::DEADLOCK_WEIGHT_DDL)) { mysql_mutex_unlock(&LOCK_open); result= TRUE; goto err_with_reopen; } }复制
而等待的结束就是占用的table缓存的占用者释放,这个释放操作存在于函数 close_thread_table中,如下:
if (table->s->has_old_version() || table->needs_reopen() || table_def_shutdown_in_progress) { tc->remove_table(table);//关闭 table cache instance mysql_mutex_lock(&LOCK_open); intern_close_table(table);//去掉 table cache define mysql_mutex_unlock(&LOCK_open); }复制
最终会调用函数 MDL_wait::set_status 将 FTWRL 唤醒,也就是说对于正在占用的table缓存释放者不是FTWRL会话而是占用者自己。不管怎么样最终整个table缓存将会被清空,如果经过FTWRL后去查看 Open_table_definitions 和 Open_tables 将会发现重新计数了。下面是唤醒函数的代码,也很明显:
bool MDL_wait::set_status(enum_wait_status status_arg) open_table{ bool was_occupied= TRUE; mysql_mutex_lock(&m_LOCK_wait_status); if (m_wait_status == EMPTY) { was_occupied= FALSE; m_wait_status= status_arg; mysql_cond_signal(&m_COND_wait_status);//唤醒 } mysql_mutex_unlock(&m_LOCK_wait_status);//解锁 return was_occupied;}复制
第五步: 加MDL LOCK类型COMMIT 级别为S。如果出现等待状态为 ‘Waiting for commit lock’。如果有大事务的提交很可能出现这种等待。
注意 这里的第五步,正是因为w1和w3获取了 MDL LOCK COMMIT,而又在等待w2的事务提交因此FTWRL也不得不等待。
五、关于woker线程w2的等待
这里可能的原因有2个:
多线程并行的情况下,线程执行的顺序本生就是不定的,很可能线程由于丢失CPU而落后其他线程的处理,因为CPU调度的最小单位是线程。如果保证某个共享内存操作的完整性需要用到mutex、原子变量等技术。 如果w2中的事务本生就包含了多个DML语句,那么获取 GLOBAL READ LOCK 本身就是间歇性的,也就是每个语句结束都会释放,然后下一个语句开始的时候再次open table来获取。
我们来看看第二点,只考虑row_format格式的binlog。
我们知道一个事务可以包含多个语句,每条语句都会包含一个map Event和多个DML Event,当本Event是语句的最后一个Event的时候会使用STMT_END_F进行标记,也正是在这个时候会释放 GLOBAL READ LOCK,源码有如下:
if (get_flags(STMT_END_F)) { if((error= rows_event_stmt_cleanup(rli, thd)))栈:#0 MDL_context::release_lock (this=0x7fffa8000a08, duration=MDL_STATEMENT, ticket=0x7fffa800ea40) at /opt/percona-server-locks-detail-5.7.22/sql/mdl.cc:4350#1 0x0000000001464bf1 in MDL_context::release_locks_stored_before (this=0x7fffa8000a08, duration=MDL_STATEMENT, sentinel=0x0) at /opt/percona-server-locks-detail-5.7.22/sql/mdl.cc:4521#2 0x000000000146541b in MDL_context::release_statement_locks (this=0x7fffa8000a08) at /opt/percona-server-locks-detail-5.7.22/sql/mdl.cc:4813#3 0x0000000001865c75 in Relay_log_info::slave_close_thread_tables (this=0x341e8b0, thd=0x7fffa8000970) at /opt/percona-server-locks-detail-5.7.22/sql/rpl_rli.cc:2014#4 0x0000000001865873 in Relay_log_info::cleanup_context (this=0x341e8b0, thd=0x7fffa8000970, error=false) at /opt/percona-server-locks-detail-5.7.22/sql/rpl_rli.cc:1886#5 0x00000000017e8fc7 in rows_event_stmt_cleanup (rli=0x341e8b0, thd=0x7fffa8000970) at /opt/percona-server-locks-detail-5.7.22/sql/log_event.cc:11782#6 0x00000000017e8c79 in Rows_log_event::do_apply_event (this=0x7fffa8017dc0, rli=0x341e8b0) at /opt/percona-server-locks-detail-5.7.22/sql/log_event.cc:11660#7 0x00000000017cfdcd in Log_event::apply_event (this=0x7fffa8017dc0, rli=0x341e8b0) at /opt/percona-server-locks-detail-5.7.22/sql/log_event.cc:3570#8 0x00000000018476dc in apply_event_and_update_pos (ptr_ev=0x7fffec14f880, thd=0x7fffa8000970, rli=0x341e8b0) at /opt/percona-server-locks-detail-5.7.22/sql/rpl_slave.cc:4766#9 0x0000000001848d9a in exec_relay_log_event (thd=0x7fffa8000970, rli=0x341e8b0) at /opt/percona-server-locks-detail-5.7.22/sql/rpl_slave.cc:5300#10 0x000000000184f9cc in handle_slave_sql (arg=0x33769a0) at /opt/percona-server-locks-detail-5.7.22/sql/rpl_slave.cc:7543(gdb) p ticket->m_lock->key.mdl_namespace()$1 = MDL_key::GLOBAL(gdb) p ticket->m_type$2 = MDL_INTENTION_EXCLUSIVE(gdb) p ticket->m_duration$3 = MDL_STATEMENT复制
如果下一条语句开始又会重新获取GLOBAL READ LOCK,这就是我说的间歇性获取。
到这里死锁条件已经成熟,只要遇到这种情况就可能需要人为介入才能继续了。
六、关于mysqldump
社区版在如下情况下需要增加FTWRL:
设置了master-data 设置了singal-transaction和flush-logs
percona版在如下情况需要增加FTWRL:
设置了singal-transaction和flush-logs
我们来大概看看社区版的代码如下(代码版本8.0.21),下面是从FTWRL倒UNLOCK的过程:
if ((opt_lock_all_tables || opt_master_data || //如果设置了 master data 设置flush table with read lock (opt_single_transaction && flush_logs)) &&//如果设置了single transaction和flush logs 设置flush table with read lock do_flush_tables_read_lock(mysql)) //设置flush table with read lock goto err; /* /* Flush logs before starting transaction since this causes implicit commit starting mysql-5.5. */ if (opt_lock_all_tables || opt_master_data || (opt_single_transaction && flush_logs) || opt_delete_master_logs) { if (flush_logs || opt_delete_master_logs) {//如果设置了 flush logs 进行日志刷新 if (mysql_refresh(mysql, REFRESH_LOG)) { //进行日志刷新 DB_error(mysql, "when doing refresh"); goto err; } verbose_msg("-- main : logs flushed successfully!\n"); } /* Not anymore! That would not be sensible. */ flush_logs = false; } if (opt_delete_master_logs) { if (get_bin_log_name(mysql, bin_log_name, sizeof(bin_log_name))) goto err; } if (opt_single_transaction && start_transaction(mysql)) goto err; //开启事务 RR /* Add 'STOP SLAVE to beginning of dump */ if (opt_slave_apply && add_stop_slave()) goto err; /* Process opt_set_gtid_purged and add SET @@GLOBAL.GTID_PURGED if required. */ if (process_set_gtid_purged(mysql)) goto err; //设置GTID,如果设置了gtid_purged 这个函数会跳过 if (opt_master_data && do_show_master_status(mysql)) goto err; //获取主库binlog位置 if (opt_slave_data && do_show_slave_status(mysql)) goto err; //slave_data 设置相关 从show slave中获取 if (opt_single_transaction && do_unlock_tables(mysql)) /* unlock but no commit! */ goto err;复制
percona版本中增加了判断函数 check_consistent_binlog_pos,如下(不过多描述):
if (opt_single_transaction && opt_master_data) { /* See if we can avoid FLUSH TABLES WITH READ LOCK with Binlog_snapshot_* variables. */ consistent_binlog_pos= check_consistent_binlog_pos(NULL, NULL); } if ((opt_lock_all_tables || (opt_master_data && !consistent_binlog_pos) ||//consistent_binlog_pos 0 需要 1 不需要 (opt_single_transaction && flush_logs))) { if (do_flush_tables_read_lock(mysql)) goto err; }复制
七、如何解决
总结如下:
master-data 一般备份都会增加,因此只能在低峰期进行备份,尽量减少影响。 考虑关闭参数 slave_preserve_commit_order。但是FTWRL的堵塞还是存在,只是不会产生死锁。 如果压力不大可以考虑关闭MTS。但是FTWRL的堵塞还是存在,只是不会产生死锁。
全文完。
Enjoy MySQL :)
文章至此。
以下是个人微信公众号,欢迎关注:

近期热文
你可能也会对以下话题感兴趣。点击链接便可查看。
