




前言
详细大家在读 Golang 相关的代码的时候,见到的最多的 Go 标准库工具就是 context。
context 翻译成中文是“上下文”的意思,在生活或者工作中我们需要上下文来判断某些话或者某个工作所处背景或者环境。比如说我们在写一个需求文档的时候,往往会在第一部分写上基本背景,这个就是上下文,它能够让读者更快速地感知到当前需求产生的背景和必要性等等。同理,在开发场景中,上下文也是不可缺少的,它能够告诉我们完整的程序信息。
我们可以想象一个开发场景:在服务端处理一个客户端请求的过程中,我们可能需要打印一些必要的日志信息,并且想要通过 LogID 将这些日志串联起来,形成 trace 信息,代表它们是来自于同一次请求的。如果不使用 context,我们可能需要在每一次函数调用中都需要把 LogID 作为入参传递下去,如果只有一个 LogID 可能还好,那么假设我们后面又希望把客户端的 IP 地址以及 UserID 等信息也一并传递下去呢?这个时候如果一个函数一个函数地调整它们的参数显然不现实,更好的做法是将这些参数封装到一个结构体里面,这样可以避免频繁地调整函数参数,然而这一步我们现在不需要自己来做了,context 已经提供了这样的能力。
当然,Golang 标准库中的 context 的作用远不止传递参数这么简单,它还提供了超时和取消的机制,利用 context 的这些能力,我们可以很方便地协调协程之间的工作,从而开发出更加灵活的并发任务的场景。
本文目录结构如下:
Context 的诞生
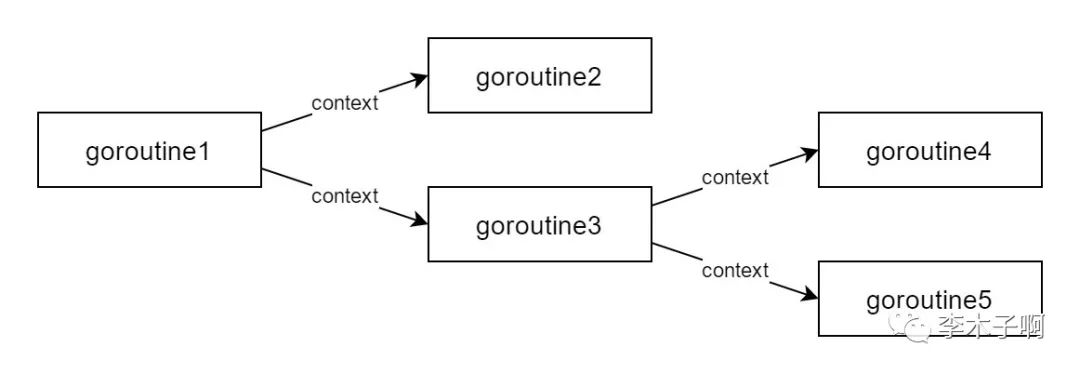
Context 并不是从 Golang 伊始就存在的,相反,它是从 Go1.7 版本才被引入到 Golang 标准库的。我们都知道 Golang 比较擅长用来写服务端代码,并且由于其特有的协程机制,我们通常在每个请求到来的时候都去启动若干个协程去分别处理不同的任务,然后等待所有协程执行成功之后,统一返回给客户端。那么如何将一些通用的参数(例如 LogID、用户 session 等)传给每个协程就成了一个问题。同时主协程如何统筹子协程的生命周期,例如超时取消等机制在当初也是一个很棘手的问题。
在 Go1.7 之前,很多 Web 框架在定义自己的 handler 时,都会传递一个自定义的 Context,把客户端的信息和客户端的请求信息放入到 Context 中。Go 最初提供了 golang.org/x/net/context 库用来提供上下文信息,但最终还是在 Go1.7 中把此库提升到标准库 context 包中,同时标准库的 context 包还提供了手动取消以及超时自动取消等能力,从而可以更好地统筹协程的运行。
接下来就让我们深入 context 源码,充分解读一下 context 的工作机制和实现原理。
以下代码基于 Go1.17 版本
context 简称 ctx,下文中出现的 ctx 都代表 context
实现原理与源码解读
context 相关的代码主要在 context/context.go
文件中,加上注释一共 567 行,如果排除掉注释的话,大概也就 300 行左右,十分短小精悍。
Context 接口定义
Context 是以接口的形式对外提供的,其接口定义如下:
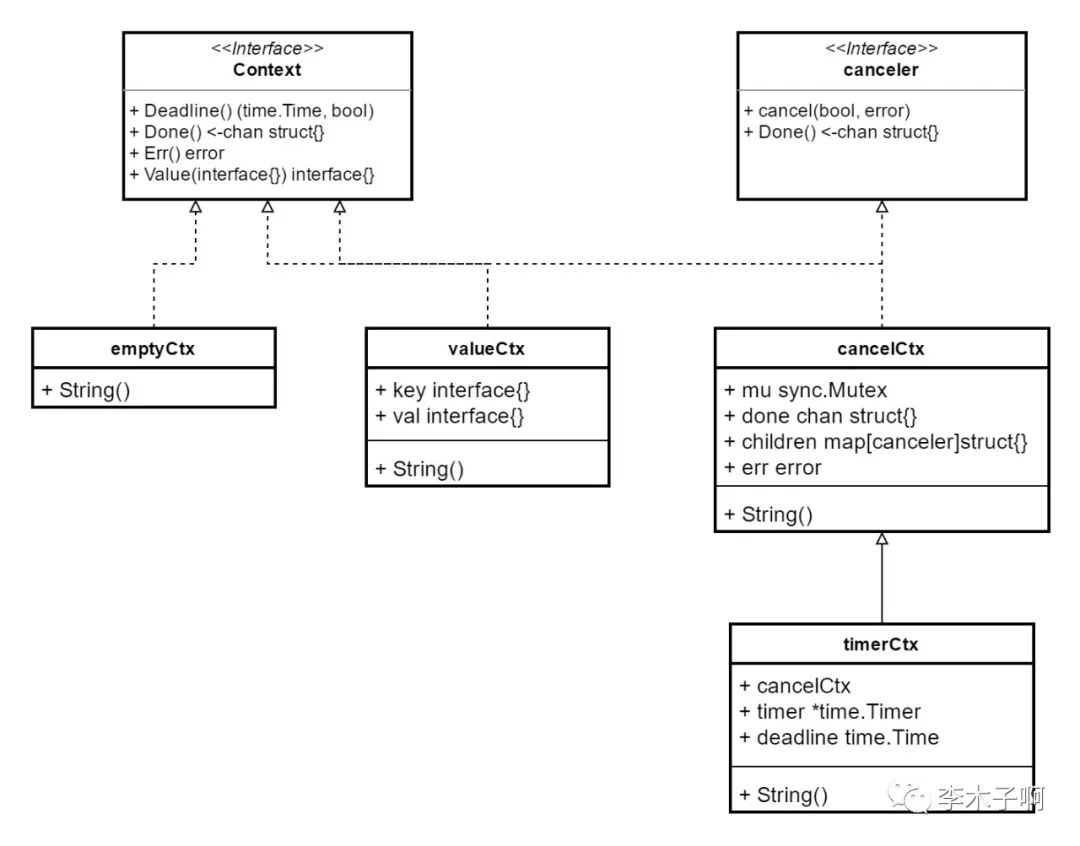
type Context interface {// 返回 context 是否设置了超时时间以及超时的时间点// 如果没有设置超时,那么 ok 的值返回 false// 每次调用都会返回相同的结果Deadline() (deadline time.Time, ok bool)// 如果 context 被取消,这里会返回一个被关闭的 channel// 如果是一个不会被取消的 context,那么这里会返回 nil// 每次调用都会返回相同的结果Done() <-chan struct{}// 返回 done() 的原因// 如果 Done() 对应的通道还没有关闭,这里返回 nil// 如果通道关闭了,这里会返回一个非 nil 的值:// - 若果是被取消掉的,那么这里返回 Canceled 错误// - 如果是超时了,那么这里返回 DeadlineExceeded 错误// 一旦被赋予了一个非 nil 的值之后,每次调用都会返回相同的结果Err() error// 获取 context 中保存的 key 对应的 value,如果不存在则返回 nil// 每次调用都会返回相同的结果Value(key interface{}) interface{}}复制
Context 中 error 对应的错误类型包含两个,如下:
var Canceled = errors.New("context canceled")var DeadlineExceeded error = deadlineExceededError{}type deadlineExceededError struct{}func (deadlineExceededError) Error() string { return "context deadline exceeded" }func (deadlineExceededError) Timeout() bool { return true }func (deadlineExceededError) Temporary() bool { return true }复制
细心点的同学从上述接口的四个方法的注释中都能找到 "Successive calls to xxx return the same xxx" 字眼,这表明以上四个方法都是幂等的,也就是每次(被赋值之后)调用它们都能返回相同的结果。那么为什么会这样呢?其实通过下面的源码分析我们就能得到答案了。
Context 类型的结构体
emptyCtx
emptyCtx 不是一个结构体,它只是 int 类型的一个别名,实现的 Context 的四个方法都是返回 nil 或者默认值:
type emptyCtx intfunc (*emptyCtx) Deadline() (deadline time.Time, ok bool) {return}func (*emptyCtx) Done() <-chan struct{} {return nil}func (*emptyCtx) Err() error {return nil}func (*emptyCtx) Value(key interface{}) interface{} {return nil}复制
这意味着 emptyCtx 永远不能被取消,没有 deadline,并且也不会保存任何值。它是一个私有类型,没有提供相关的导出方法,但是却被包装成了两个可以被导出的 ctx,用作顶层 Context:
var (background = new(emptyCtx)todo = new(emptyCtx))func Background() Context {return background}func TODO() Context {return todo}复制
其实这两个实例本身也不具有任何含义,本质上就是一个 emptyCtx,但是从其注释上我们可以发现 Golang 官方赋予(规定)了使用它们的不同场景:
•background
:通常可以用于 main 函数、初始化和测试,作为请求上下文的最顶层(根节点)。•todo
:当你不知道需要传入什么样的 context 的时候,就可以使用它,它可以随时被替换成其他类型的 context。
实际上这俩完全没有任何区别,但是通过不同的命名,Golang 希望我们在不同的场合选择不同的实例,当然这只是建议,如果你任性的话,完全可以在 main 函数中使用 todo
,甚至可以自己实现一个新的 ctx 作为根节点。
valueCtx
相比 emptyCtx,valueCtx 要稍微复杂一些,它维护了一个键值对,可以保存一组 kv(只有一组),其结构体类型定义如下:
type valueCtx struct {// 父 ctxContext// kvkey, val interface{}}复制
它的定义比较简单,只是维护了它的父 ctx 以及 kv 共三个字段,创建 valueCtx 的函数如下:
WithValue(Context, interface{}, interface{})
func WithValue(parent Context, key, val interface{}) Context {if parent == nil {panic("cannot create context from nil parent")}if key == nil {panic("nil key")}if !reflectlite.TypeOf(key).Comparable() {panic("key is not comparable")}return &valueCtx{parent, key, val}}复制
除了常规的 nil 检查之外,唯一的要求就是需要 key 是可比较的(这个很好理解,因为我们需要通过 key 来定位相应的 value 嘛)。并且由于它是将 Context 作为匿名字段的,因此它不需要自己去实现 Context 接口的方法,只需要继承自父 ctx 即可。因此 valueCtx 只实现了下述两个方法:
String()
func (c *valueCtx) String() string {return contextName(c.Context) + ".WithValue(type " +reflectlite.TypeOf(c.key).String() +", val " + stringify(c.val) + ")"}复制
Value(interface{})
Value() 方法用于获取 key 对应的 value,如果从当前的 ctx 找不到,那么会递归去它的父 ctx 中去找。
func (c *valueCtx) Value(key interface{}) interface{} {if c.key == key {return c.val}// 如果当前 ctx 没有找到,那么会去父 ctx 上面去找return c.Context.Value(key)}复制
一个 ctx 只能保存一对 kv,那么如果我们想要在 ctx 中保存多个 kv 键值对该怎么办?
其实很简单,我们只需要多次调用 WithValue()
函数,每次塞进去一对 kv 即可,在取值的时候,Value()
方法会自动地从整个 ctx 的树形结构中递归地往上层查找。所以,我们可以通过子 ctx 找到 父 ctx 维护的 kv,但是反过来是不可以的,这一点在使用的过程中需要注意。
举个例子,如下图所示,假设当前在 Context3,我们想要查 key1 的值,发现当前 ctx 维护的 key 不是 key1,那么会从它的父节点也就是 Context2 去找,还没找到,便继续往上层去找,发现 Context1 维护的 key 就是我们想要的,那么 Value
方法便会返回它对应的 val1。

从 valueCtx 提供的相关方法中我们可以发现,它并没有提供改变 key 对应的 value 的值(结构体指针)的能力,因此 Value()
方法返回的结果总是一样的。
cancelCtx
在讲 cancelCtx 之前,我们先看一下 canceler 接口,因为 cancelCtx 正是实现了这个接口:
type canceler interface {cancel(removeFromParent bool, err error)Done() <-chan struct{}}复制
它包含两个方法:
•cancel
:取消操作,第一个参数代表取消的时候是否要将当前 ctx 从父 ctx 维护的子 ctx 中移除,第二个参数代表要传给 ctx 的 err(通过 Context.Err() 方法可以捕获);•Done
:与 Context.Done()
一致。
cancelCtx 是更加复杂的一个 ctx,它实现了 canceler 接口,支持取消操作,并且取消操作能够往子节点蔓延,其结构体定义如下:
type cancelCtx struct {// 父 ctxContext// 通过互斥锁来保证对下面三个 field 操作的安全性mu sync.Mutex// 保存一个 chan struct{},第一个 cancel() 调用会关闭这个通道done atomic.Value// 维护所有子 canceler// 当前 ctx 被取消之后,它的所有子 canceler 都会被取消,并且这个属性会被置空children map[canceler]struct// 第一个 cancel() 调用会赋值err error}复制
WithCancel(Context, CancelFunc)
通过 WithCancel
函数我们可以返回一个 cancelCtx 的实例:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {if parent == nil {panic("cannot create context from nil parent")}// 初始化一个 cancelCtx 实例c := newCancelCtx(parent)// 将当前 ctx 挂载到父节点上,从而实现 cancel 操作的向下传播propagateCancel(parent, &c)return &c, func() { c.cancel(true, Canceled) }}复制
该函数返回一个 cancelCtx 实例以及一个取消函数,一旦这个函数被我们调用,那么当前 ctx 及其子 cancelCtx 会被马上取消。
value(interface{})
我们先来看一下 cancelCtx 实现的 Value()
方法。
var cancelCtxKey intfunc (c *cancelCtx) Value(key interface{}) interface{} {// 特殊路径,如果传入的 key 是 &cancelCtxKey,那么直接返回当前的 ctxif key == &cancelCtxKey {return c}// 否则去它的父 ctx 上面查找对应的 valuereturn c.Context.Value(key)}复制
可以看到,cancelCtx 的 Value
方法提供了一个特殊路径,就是如果传入的 key 是 &cancelCtxKey,那么直接返回当前的 ctx。记住这一点,它在下面会被用到。
cancel(bool, error)
接着我们看一下 cancel()
方法,理解它我们便可以理解上面 cancel 函数传递的参数的作用。
func (c *cancelCtx) cancel(removeFromParent bool, err error) {if err == nil {panic("context: internal error: missing cancel error")}c.mu.Lock()// 如果 c.err 不是 nil,代表已经被取消了,直接返回if c.err != nil {c.mu.Unlock()return}// 标记已经被取消c.err = errd, _ := c.done.Load().(chan struct{})// 关闭 channel,从而可以通知到其他协程// 如果 d == nil,代表之前没有调用过 Done() 方法,这里直接传入一个 closedchan(关闭的通道)if d == nil {c.done.Store(closedchan)} else {// 否则的话,需要关闭当前的 channelclose(d)}// cancel 子节点for child := range c.children {child.cancel(false, err)}c.children = nilc.mu.Unlock()// 如果需要从父节点中移除当前节点,那么执行 remove 操作if removeFromParent {removeChild(c.Context, c)}}// removeChild 移除一个子节点func removeChild(parent Context, child canceler) {p, ok := parentCancelCtx(parent)if !ok {return}p.mu.Lock()if p.children != nil {// 从 map 中移除当前元素delete(p.children, child)}p.mu.Unlock()}复制
cancel
的实现很简单,它会先取消自己(err 赋值,同时关闭 channel),然后将它维护的子节点也给取消掉,最后判断(第一个入参)需不需要将自己从父节点中移除,如果需要的话,就执行 removeChild
函数(内部就是调用 delete 内置函数)将自己移除。
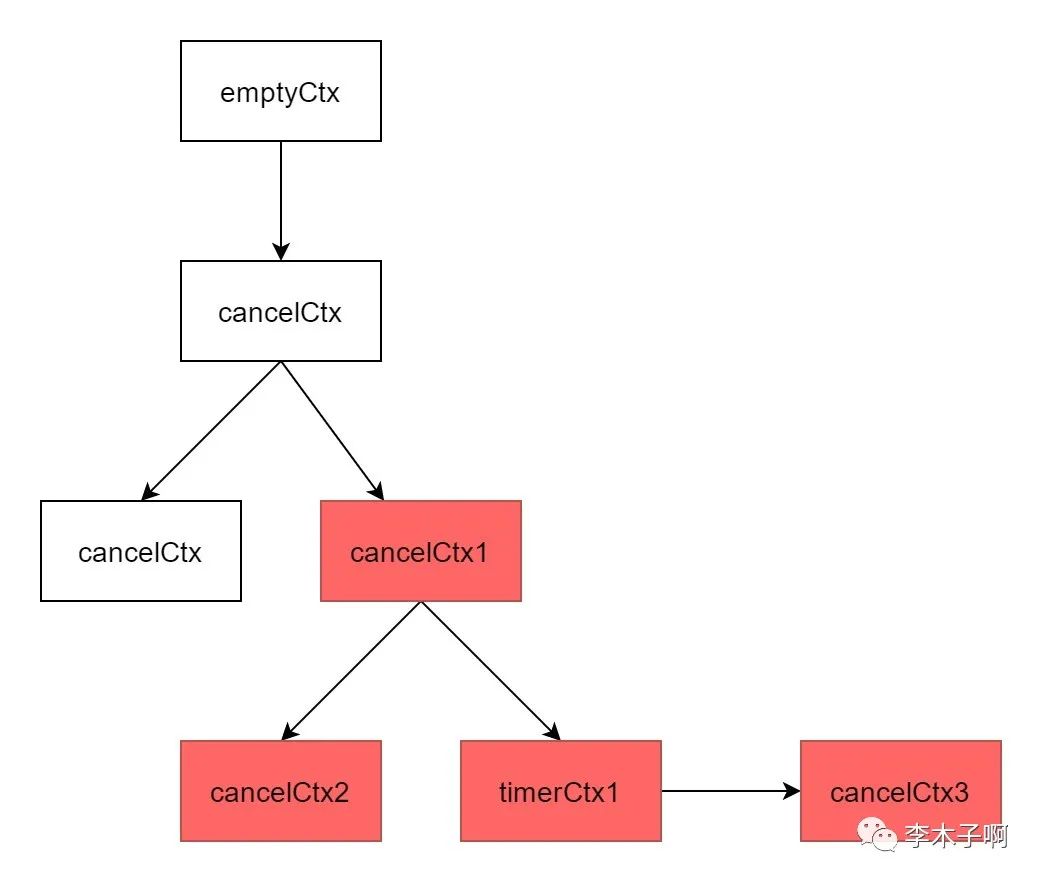
如下图所示,当 cancelCtx1 取消之后,它的子节点 cancelCtx2 和 timerCtx1 以及子节点的子节点 timerCtx2 都会被取消。
那么子节点是如何挂载到父节点上面的呢?这个就需要依赖下面这个函数了。
propagateCancel(Context, canceler)
propagateCancel
的作用是将子 cancelCtx 挂载到父 cancelCtx 上面,这样的话,当父 cancelCtx 被取消之后,它下面挂载的所有子 cancelCtx 都可以被取消。这个方法是实现 cancel 传播的前提。
func propagateCancel(parent Context, child canceler) {done := parent.Done()// done == nil 代表父 ctx 不是一个可以被 cancel 的 ctx,直接返回if done == nil {return}select {case <-done:// parent ctx 已经被 cancel 了,那么直接 cancel 当前 ctxchild.cancel(false, parent.Err())returndefault:}// 判断父节点是不是一个(合法的) cancelCtx// yesif p, ok := parentCancelCtx(parent); ok {p.mu.Lock()// 双重检查if p.err != nil {// 父节点已经被 cancel 了,那么直接 cancel 当前 ctx// 第一个参数传 false 是因为当前节点还没有添加到父节点下面,自然没必要执行 remove 操作child.cancel(false, p.err)} else {if p.children == nil {p.children = make(map[canceler]struct{})}// 将当前节点挂载到父节点上面p.children[child] = struct{}{}}p.mu.Unlock()} else {atomic.AddInt32(&goroutines, +1)go func() {select {// 如果当前父节点取消,那么取消对应的子节点// 对应 parentCancelCtx 函数中 done == closedchan 的场景case <-parent.Done():child.cancel(false, parent.Err())// 子节点自己取消,退出 selectcase <-child.Done():}}()}}func parentCancelCtx(parent Context) (*cancelCtx, bool) {// 由于只有 cancelCtx 实现了 Done() 方法(emptyCtx 除外)// 通过继承机制,这里会返回向上查找的第一个 cancelCtx 的 channeldone := parent.Done()// done == closedchan 代表已经父节点取消了// done == nil 代表不是一个 cancelCtxif done == closedchan || done == nil {return nil, false}// 可以联想一下 cancelCtx.Value() 以及 valueCtx.Value() 的实现// 它们都会递归往上层取值// 并且由于 key 是 &cancelCtxKey,它会向上取第一个 cancelCtx 实例p, ok := parent.Value(&cancelCtxKey).(*cancelCtx)// 如果最终断言失败,代表从当前节点一直往上层都找不到 cancelCtx// 直接返回失败if !ok {return nil, false}pdone, _ := p.done.Load().(chan struct{})// 这里检查两次拿到的 channel 是不是同一个// 如果不是,代表这个 *cancelCtx 被用户自定义的包装实现中提供了一个不同的 done channel// 如果是这种情况,那么会直接拦截,返回 false// 之所以要拦截,是因为在这里不清楚调用者会怎么使用自定义的 done channel// 由于 cancel 操作依赖这个 channel,如果依然把子节点放进当前节点中,可能会产生预期之外的效果if pdone != done {return nil, false}return p, true}复制
parentCancelCtx
函数巧妙地利用了继承(匿名属性)的机制,实现了 parent cancelCtx 的往上查找,这种通过匿名属性实现继承的方式,我们在自己的项目开发过程中也可以有选择性地去使用。
好了,到目前为止,取消操作我们讲完了,那么 ctx 是如何将取消操作通知出去的呢?这里就涉及到 Context 的 Done
和 Err
两个方法了。
Done()
Done()
方法返回一个只读的 channel,在 ctx 被取消之前,对它的读操作会被阻塞,直到 channel 被关闭,一旦接收到了 channel 关闭的信号,那就代表当前 ctx 已经被取消了。
func (c *cancelCtx) Done() <-chan struct{} {d := c.done.Load()if d != nil {return d.(chan struct{})}c.mu.Lock()defer c.mu.Unlock()d = c.done.Load()// 懒汉式if d == nil {d = make(chan struct{})c.done.Store(d)}return d.(chan struct{})}复制
Done()
一般配合 select 关键字来使用,用于检查 ctx 是否被 cancel 了,使用示例如下:
func cancelled(ctx context.Context) bool {select {case <-ctx.Done():return truedefault:return false}}复制
Err()
Err()
方法则更简单,就是将 ctx 当前维护的 err 属性返回出去。如果得到的值是 nil,代表当前 ctx 还没有被取消(也有可能是一个不可取消的 ctx),否则代表已经被取消了。
func (c *cancelCtx) Err() error {c.mu.Lock()err := c.errc.mu.Unlock()return err}复制
timerCtx
有了上面 cancelCtx 的铺垫,timerCtx 就好理解许多了。我们知道 cancelCtx 可以被手动取消(cancel),timerCtx 则在此基础上增加了超时自动取消的能力,其结构体定义如下:
type timerCtx struct {// 维护一个 cancelCtxcancelCtx// 通过 cancelCtx.mu 加锁保护timer *time.Timer// 超时时间deadline time.Time}复制
timerCtx 的结构体定义很简单,维护了一个 cancelCtx 用来提供手动取消的能力,同时维护了一个 timer 和 deadline 用来实现到时间(deadline)自动(timer)取消。
timeCtx 提供了两种初始化实例的方法:
WithTimeout(Context, time.Duration)
入参是 time.Duration
代表 ctx 会在多长时间之后自动取消,内部还是调用了 WithDeadline
函数。
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {return WithDeadline(parent, time.Now().Add(timeout))}复制
WithDeadline(Context, time.Time)
WithDeadline
入参是 deadline 的截至时间点,代表到了这个时间就会自动取消。
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) {if parent == nil {panic("cannot create context from nil parent")}if cur, ok := parent.Deadline(); ok && cur.Before(d) {// 如果父节点的截止日期比新的早// 那么新的截止日期实际上不会产生作用,因为它会被父节点提前 cancel// 所以这里直接返回一个 cancelCtx 即可return WithCancel(parent)}c := &timerCtx{cancelCtx: newCancelCtx(parent),deadline: d,}// 挂载到父节点上,这样父节点取消的话,当前节点也能被取消propagateCancel(parent, c)dur := time.Until(d)// 如果已经超过截止时间了,那么直接取消if dur <= 0 {c.cancel(true, DeadlineExceeded)return c, func() { c.cancel(false, Canceled) }}c.mu.Lock()defer c.mu.Unlock()if c.err == nil {// 开启一个定时器,用于到时间自动取消c.timer = time.AfterFunc(dur, func() {c.cancel(true, DeadlineExceeded)})}return c, func() { c.cancel(true, Canceled) }}复制
这段代码很好理解,执行流程已经在代码中注释了,这里不再赘述。需要注意的是,这个方法也会返回一个 CancelFunc
,代表除了自动取消,我们也可以在到达 deadline 之前手动取消。其实往往有时候手动取消要比自动取消更好,因为手动取消能够在需要取消的时候就取消,有时候能够节约很多资源;相反,如果完全依赖自动取消,那么假设自动取消的 deadline 设置的过晚,那么很有可能会导致同一时间有大量的协程堆积,造成资源浪费。
好了,对应 context 包的相关源码这里讲的差不多了,当然以上只是深入讲解了一些与 context 操作相关的大部分代码,很多其他常规的方法都没有讲到,例如 String()
等等。context 方法的实现特别简洁,充分利用了“继承”(匿名属性)这一面向对象的设计范式。通过使用匿名属性,子 ctx 可以直接操作父 ctx 的一些方法,从而简化了一些特殊 ctx 的实现成本,例如 timerCtx
继承了 cancelCtx
,它可以直接继承 cancelCtx
的 cancel
和 Done
等方法;再例如 parentCancelCtx
函数的巧妙设计。也正是通过匿名属性的方式,context 实现了它的层级结构。
经过上述的源码分析,我们可以大致画一下 context 的整体类图:
典型应用
context 包提供的几种特殊的 Context 分别具有不同的功能,按照能力上划分,主要分别适用于如下的几个场景。
数据传递
Context 的应用场景之一就是实现数据的传递。有时候我们希望将某些参数能够在函数调用链当中层层传递下去,例如用户的登录信息、操作的 logID 等等,这些可以作为函数参数的一部分,但是显然这么设计会使函数参数异常臃肿,函数间耦合程度太高。利用 context 我们可以很优雅地实现此功能。虽然每个 context 实例都只有一个 key-value 键值对,但是由于它实现了链式查找的机制,也就是如果从当前的 context 找不到对应的 key,那么会一层一层递归地向父 context 去找,我们可以链式地为每一个 kv 都创建一个对应的 valueCtx。使用示例如下:
const KEY_LOG = "LOG_ID"const KEY_USER_ID = "USER_ID"func TestWithValue(t *testing.T) {// 通过 WithValue() 生成一个保存 key-value 键值对的 ctxctx := context.WithValue(context.Background(), KEY_LOG, "2021082900001")// 链式存入第二个 keyctx = context.WithValue(ctx, KEY_USER_ID, "112233")logId := GetLogID(ctx)t.Log(logId)}func GetLogID(ctx context.Context) string {// 通过 Value() 方法查找if logId := ctx.Value(KEY_LOG); logId != nil {return logId.(string)}return ""}复制
可以看出,valueCtx 的使用很简单,我们只需要通过 WithValue
方法生成一个带有 key-value 的 ctx,然后在需要获取值得地方调用 Value
方法即可。
取消协程执行
Context 最常用的场景就是利用它取消一个 goroutine 的执行,通过检查 Context 的 Done
方法我们可以判断它是否被 cancel 了。同时 context 还提供了两个带有超时功能的方法,分别是 WithTimeout
和 WithDeadline
,它们本质上是一样的,只不过前者的入参是超时时间,后者的入参是截至的时间,通过这两个方法生成的 ctx,都能够实现在时间到了之后,自动执行 cancel
方法,当然我们也可以选择(最好)在超时时间到来之前手动调用 cancel
。在很多微服务调用的实现场景,都是通过它们来实现远程调用的超时控制的。
下面的代码是一个简单的示例:
func TestWithCancel(t *testing.T) {ctx, cancel := context.WithCancel(ctx)// WithTimeout 可以实现超时自动调用 Cancel()// ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)go TakeTasks(ctx, "c1")// ctx2 是 ctx 的子 context,当 ctx 被取消之后,ctx2 也会被取消ctx2, _ := context.WithCancel(ctx)go TakeTasks(ctx2, "c2")time.Sleep(500 * time.Millisecond)// 也可以手动提前取消cancel()time.Sleep(100 * time.Millisecond)}func cancelled(ctx context.Context) bool {select {case <-ctx.Done():fmt.Println("finish taking tasks!")return truedefault:fmt.Println("continue!")return false}}func TakeTasks(ctx context.Context, flag string) {for {if cancelled(ctx) {break}fmt.Printf("%s taking tasks!\n", flag)time.Sleep(100 * time.Millisecond)}}复制
其实通过上面的源码分析已以及面的示例我们可以知道,context 的取消操作是一层一层往下传递的。也就是说在调用 cancel()
之后,对应的 ctx 会先标记自己已经被取消,然后它会向它的所有子 ctx 传达取消信号,通知它们也应该被取消掉了。
context 使用中的注意事项
同样的,我们来总结一下使用 context 的一些注意事项:
•context 携带的 kv 是向上查找的,如果当前节点查不到对应的 key,那么会继续从其父节点中查找;•context 的取消操作是向下蔓延的,如果当前节点取消,那么它的子节点(cancelCtx)也会被取消;•使用带有超时的 timerCtx,如果能提前取消,那么最好手动提前取消,从而可以快速释放资源,同时需要注意的是 context 的取消操作针对的只是 context,如果还涉及到一些其他的操作,例如和数据库通信、文件读写等,这些也需要我们手动取消。
以下几点是使用 context 的一些约定俗成的建议:
•不要将 context 塞到结构体里面,相反的它应该作为函数的第一个参数,并且统一命名成 ctx;•不要传入一个 nil context,如果不知道传啥,可以使用 context.TODO() 传入一个 emptyCtx;•context 中存储的应该是贯穿整个生命周期的数据,例如用户的 session、cookie 等,不要把本应该作为函数参数的数据放进 context 中;•key 的类型最好不要是字符串类型或者其它内建类型,否则容易在包之间使用 Context 时候产生冲突。使用 WithValue
时,key 的类型最好是自己定义的类型;•context 是天然并发安全的,不需要担心多个 goroutine 对它的并发操作。
总结
本文我们主要讨论的是 context 包中的函数和 Context 类型。Context 主要有四种,分别是 emptyCtx、valueCtx、cancelCtx 以及 timerCtx,它们从根 Context 开始,由上往下进行传递,可以形成一个上下文树。我们可以从这棵树中的 valueCtx 获取数据,也可以取消其中的一些 cancelCtx 或者 timerCtx,其中获取数据是从下往上寻找,而取消操作则是从上往下蔓延。
其实从这里我们也可以发现,context 取值操作和取消操作就相当于是对链表的遍历操作,时间复杂度是 O(n),效率并不是很高,但是考虑到 context 的层级不会那么深,权衡利弊之下,context 还是非常实用的一个工具。
参考
•Context:信息穿透上下文 - 晁岳攀[1]•Context isn’t for cancellation - Dave Cheney[2]
往期 Golang 源码系列
•深入浅出 WaitGroup 及其升级版•Golang 之 Mutex 源码详解•Golang 之 RWMutex 源码解读
