




并行计算指令
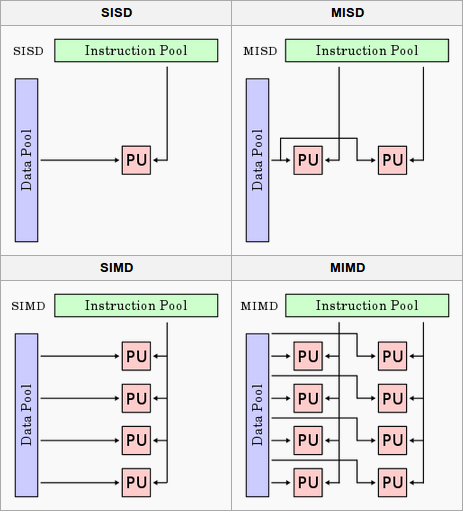
图1 并行计算指令分类[1]
SISD,Single Instruction Single Data,同时只能处理一条指令并处理一个数据的串行指令,绝大部分CPU都不支持SISD。
SIMD,Single Instruction Multiple Data,一条指令同时处理多条数据的指令,Nvidia的GPU以及AMD的SIMD都遵循这样的设计。
MIMD,Multiple Instructions Multiple Data,几乎所有的GPU和CPU都支持该指令。GPU由多个SM(Streaming Multiprocessor)单元组成,多个SM集成工作的方式也属于MIMD。
MISD,Multiple Instructions Single Data,主要用于高可靠性系统(航空、航天及军事领域),数据被多个处理器处理以保证容错性。
如图1所示,Instruction Pool负责指令的发射,Data Pool负责数据操作:数据访问、交换,PU,Processing Unit [2]。
GPU体系架构
GPU硬件设计
SP,Streaming Processor,Cuda Core,最终的指令和任务都是运行在SP上的。
SM,Streaming MultiProcessors,是SP以及其他资源(wrap scheduler,registers,shared memory)的总和。
在不同GPU体系架构中,SM中包含的SP的数量不同,这也直接影响的GPU的性能。
Fermi架构
Fermi架构GPU包含512个Cuda cores(SP),这512个core被分为16个SM(Streaming Multiprocessors),每个SM包含32个core。最大支持6GB的GDDR5内存空间。每个SM包含32个core,每个Cuda core包含一个整型处理单元和浮点处理单元(FPU).[3]

图2 Fermi架构
如图3所示,Fermi的SM的架构:
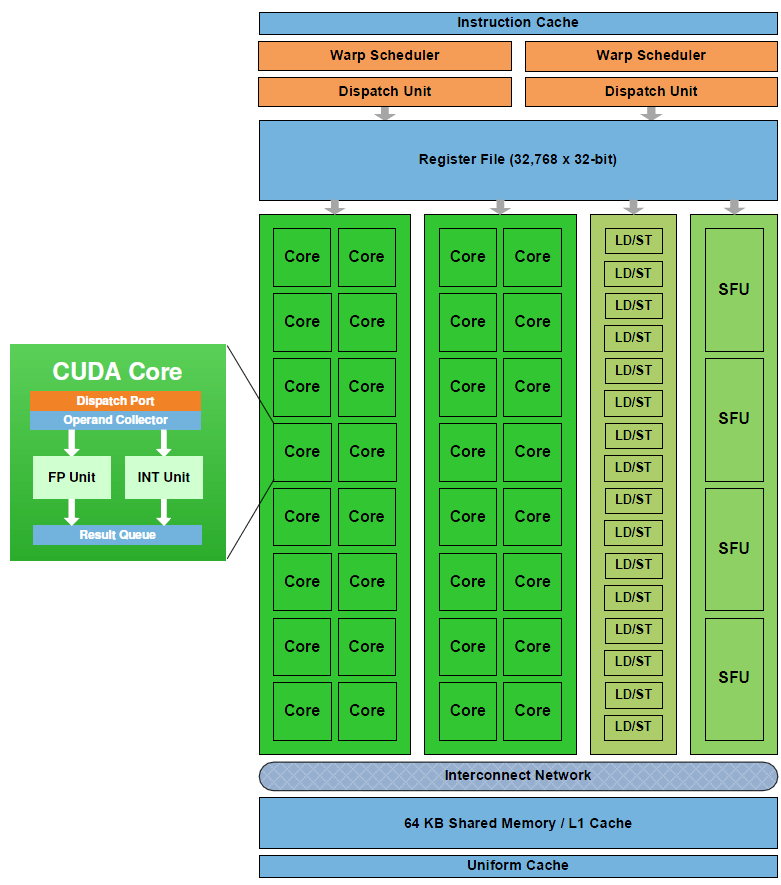
图3 Fermi SM架构
Kepler/HyperQ体系架构
制造工艺(40nm v.s. 28nm)、cache大小、SM包含的cuda core的个数、physical die的大小、功耗、精简的流水线指令等(图4所示)。
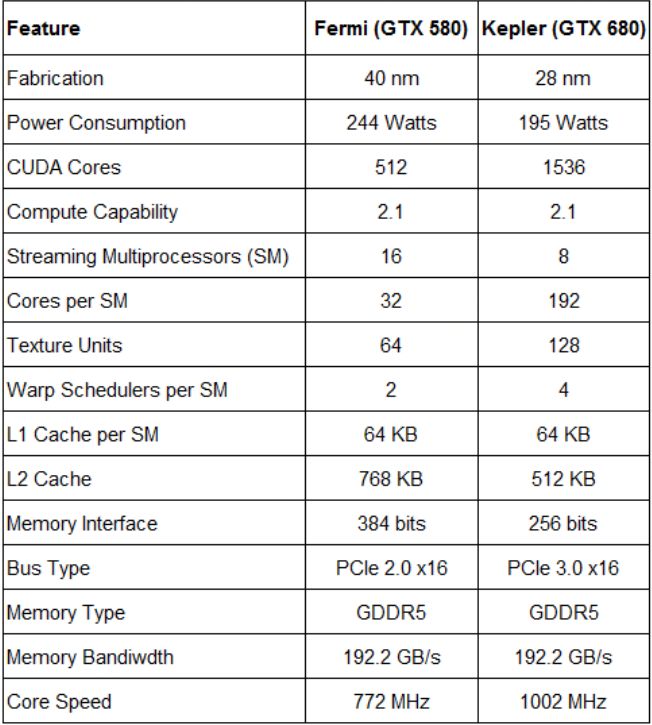
图4 Fermi v.s. Kepler物理比较
Kepler架构如图5所示:

图5 Kepler体系架构
Kepler SMX架构
- 从内存角度,Kepler架构增加了Read Only Data Cache
- 从并行化角度,Kepler动态并行,允许一个kernel里启动另一个kernel,较少了GPU和CPU之间的通信
- 增加了DP,在Cuda上使用Double
- Hyper-Q技术
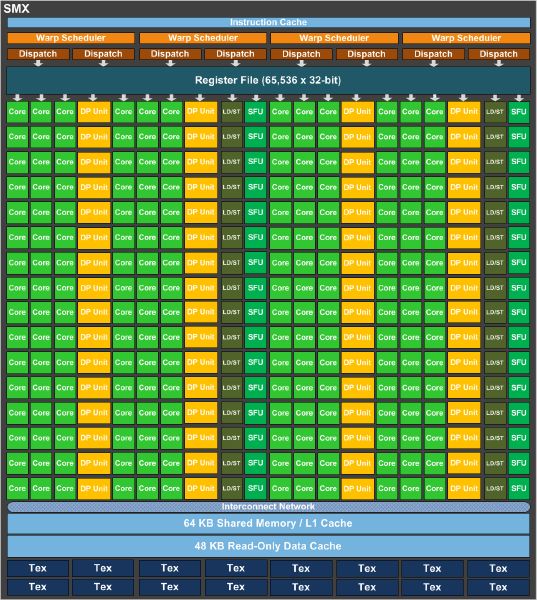
图6 Kepler SMX架构
Hyper-Q技术允许主机与GPU之间提供32个硬件工作队列,以减少任务在队列中阻塞的可能性,保证在GPU上可以有更多的并发执行,更大程度上提升GPU性能。如图7所示,Fermi下单队列与Hyper-Q技术间的对比。
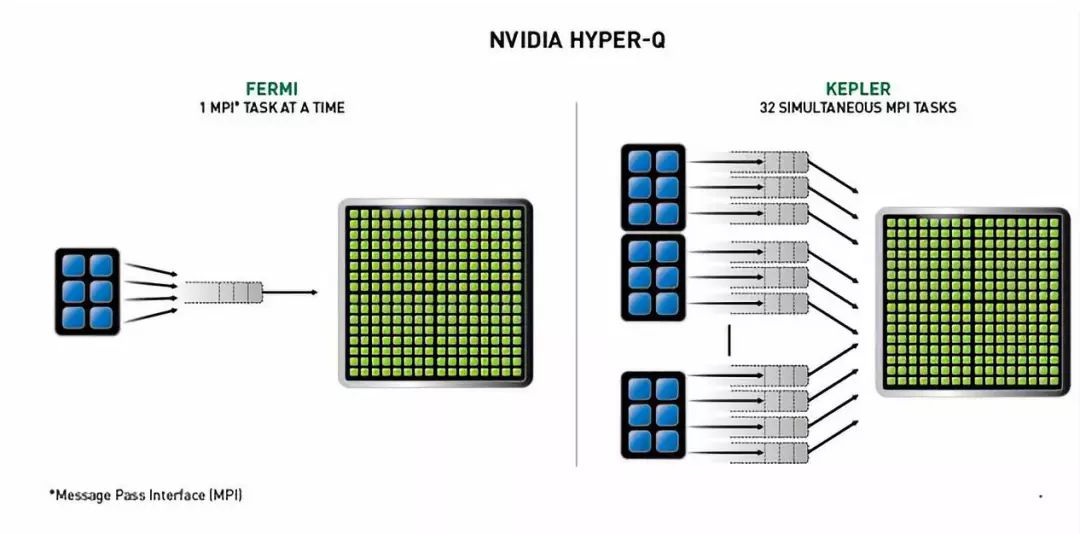
图7 Fermi v.s Kepler Hyper-Q工作队列
Cuda编程模型
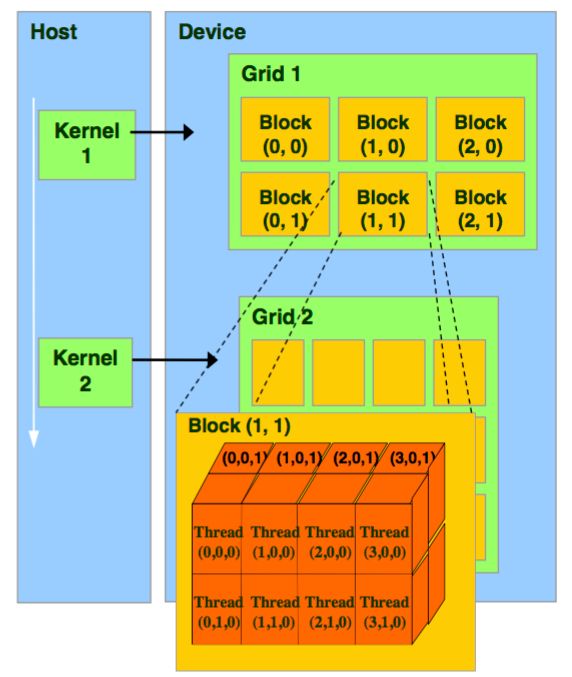
图8 Cuda编程模型
软件模型:Thread/Block/Grid/Kernel
Thread是Cuda编程里的最基本执行单元,多个threads组成一个block,多个blocks组成grid。Block中的threads可以是一维、二维、三维的,grid中的blocks也可以是一维、二维、三维的。Block可以通过blockIdx索引,block的维度可以用blockDim访问,同一个Block中的Thread通信可以通过共享内存的方式,如图9所示。
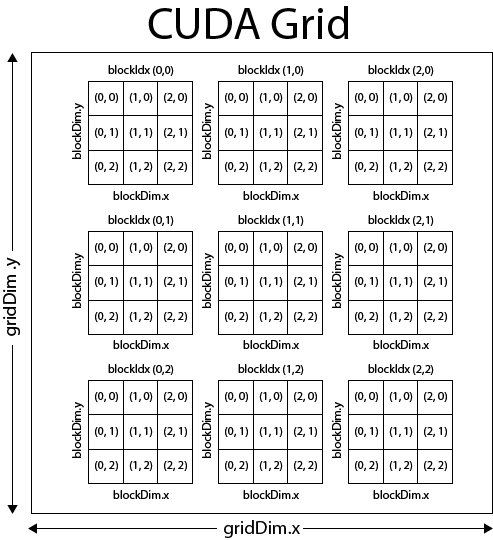
图9 Thread、Block和Grid之间的关系
Wrap是GPU调度的最小单位,同一个wrap的不同线程以不同的数据资源执行相同的指令就是SIMT(Single Instruction Multiple Threads),可以理解SIMT是SIMD的线程版,不同的是[5]:
PU处理的向量大小由软件定义,即线程块的大小
每个thread拥有自己的instruction address counter
每个thread拥有自己的状态寄存器
每个thread可以有自己独立的执行路径
一个block只由一个sm调度,block内部相应的线程信息描述在编程时进行说明,执行时的调度由sm的wrap scheduler负责,一个block在指定相应的sm后就会一直驻留在该sm中,一个sm可以享有多个blocks,调度时需顺序执行。相同wrap内的threads在调度时会有竞态发生,但不同wrap之间是可以完全并行的。GPU对每个thread都分配了独立的寄存器,无需保存/恢复上下文。
如图9所示的Grid,编写一个被线程网格中所有线程执行的函数称为kernel。调用kernel时需要特定的语法:<<<grid, block>>>来指定线程的组织层次。
修饰符host和device
Cuda编程与C语言相似,不同的是需要在kernel函数前声明修饰符,以保证该函数运行的上下文(CPU侧或GPU侧):
__device__,设备端调用并在设备端执行
__host__,主机端函数,仅能够被CPU调用
__global__,可以被GPU调用,也可以调用__device__声明的函数
[1] http://www.thephysicsmill.com/2014/07/27/parallel-computing-primer/
[2] http://www.thephysicsmill.com/2014/07/27/parallel-computing-primer/
[3] https://www.3dgep.com/cuda-thread-execution-model/#GPU_Architecture
[4] http://blog.cuvilib.com/2014/11/12/cuda-differences-bw-architectures-
and-compute-capability/
[5] https://blog.csdn.net/yu132563/article/details/60881130
