




平常业务开发中我们经常有流式数据保存在Kafka里面,这部分数据很多场景也是需要分析的,今天给大家介绍下如果使用DataX把数据从Kafka同步到OSS,保存成对分析友好的Parquet格式,然后利用DLA进行分析的全流程。
为了后续叙述的方便,我们假设Kafka里面保存的是订单的数据,它包含如下字段:
* id, int类型
* name, string类型
* gmt_create, bigint类型, 时间戳字段
* map_col: MAP<string, string> 类型
* array_col: ARRAY<string> 类型
* struct_col: STRUCT <id:bigint,name:string> 类型复制
我们最终希望把Kafka上的这个数据最终保存到OSS上,并且映射到DLA里面的一个分区表,表结构如下:
CREATE EXTERNAL TABLE orders_p (
id int,
name string,
gmt_create timestamp,
map_col MAP<string, string>,
array_col ARRAY<string>,
struct_col STRUCT<id:bigint,name:string>
)
PARTITIONED BY (dt string)
STORED AS PARQUET
LOCATION 'oss://test-bucket/datasets/oss_demo/orders_p/';复制
注意我们最终表结构里面有一个分区字段 dt
, 因为分析场景下数据量都很大,进行分区才能提高分析的效率。而这个分区字段在原始数据里面是没有直接对应的。
因为从DataX过来的数据无法自动根据目录分区,因此我们建议从Kafka过来的数据放到中间表 orders
里面去, 在数据进入orders之后我们再跟一个任务做一个“数据拆分”的工作,把数据拆分到具体的分区里面去。总结一下:要把Kafka的数据正确的落到DLA里面的 orders_p
需要经过如下步骤:
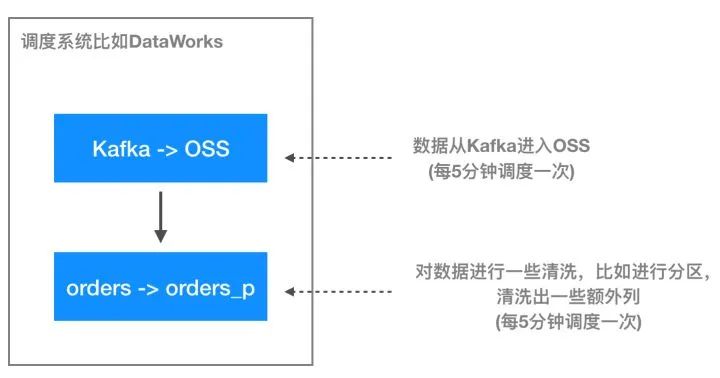
kafka -> oss
: DataX定时把数据同步到中间表: orders。orders -> orders_p
: DLA任务定时把数据从中间表orders同步到orders_p
这两个任务串行执行,第二个任务依赖第一个任务,每5分钟调度一次。这样就可以Kafka里面的数据以5分钟延时的粒度不断地写入到OSS里面去,然后使用DLA进行高效的分析。
kafka -> oss
: DataX定时把数据同步到中间表: orders
因为Kafka上的数据量很大,在DLA中一般会进行分区处理以获得更好的分析性能,但是DataX目前还无法支持直接把数据写入到分区表,因此我们要搞一个中间表: orders
过度一下,它的表结构跟最终表orders_p
几乎一样,只是没有分区
CREATE EXTERNAL TABLE orders (
id int,
name string,
gmt_create timestamp,
map_col MAP<string, string>,
array_col ARRAY<string>,
struct_col STRUCT<id:bigint,name:string>
)
STORED AS PARQUET
LOCATION 'oss://test-bucket/datasets/oss_demo/orders/';复制
那么我们第一步要做的事情就是要通过DataX把数据写到这个 orders
表对应的LOCATION
: oss://test-bucket/datasets/oss_demo/orders/
。
整个DataX的任务的JSON配置蛮复杂的,我们直接贴在这里:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 5
}
},
"content": [
{
"reader": {
"name": "kafkareader",
"parameter": {
"server": "127.0.0.2:9093",
"column": [
"id",
"name",
"gmt_create",
"map_col",
"array_col",
"struct_col"
],
"kafkaConfig": {
"group.id": "demo_test",
"java.security.auth.login.config": "/the-path/kafka/kafka_client_jaas.conf",
"ssl.truststore.location": "/the-path/kafka.client.truststore.jks",
"ssl.truststore.password": "KafkaOnsClient",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "PLAIN",
"ssl.endpoint.identification.algorithm": ""
},
"topic": "yucha",
"waitTime": "10",
"partition_": "0",
"keyType": "ByteArray",
"valueType": "ByteArray",
"seekToBeginning_": "true",
"seekToLast_": "true",
"beginDateTime": "20190501010000",
"endDateTime": "20190501010500"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "oss://test-bucket",
"fileType": "parquet",
"path": "/datasets/oss_demo/kpt",
"fileName": "test",
"writeMode": "truncate",
"compress":"SNAPPY",
"encoding":"UTF-8",
"hadoopConfig": {
"fs.oss.accessKeyId": "the-access-id",
"fs.oss.accessKeySecret": "the-access-key",
"fs.oss.endpoint": "oss-cn-hangzhou.aliyuncs.com"
},
"parquetSchema": "message test {\n required int64 id;\n optional binary name (UTF8);\n optional int64 gmt_create;\n required group map_col (MAP) {\n repeated group key_value {\n required binary key (UTF8);\n required binary value (UTF8);\n }\n }\n required group array_col (LIST) {\n repeated group list {\n required binary element (UTF8);\n }\n }\n required group struct_col {\n required int64 id;\n required binary name (UTF8);\n } \n}",
"dataxParquetMode": "fields"
}
}
}
]
}
}复制
这个配置分为两段: kafkareader
和 hdfswriter
, 分别负责读写数据。我们分别详细介绍一下。
kafkareader
里面大多数参数都比较好理解,比较重要的参数是 beginDateTime
, endDateTime
, 指定这个任务要消费的kafka数据的范围,比如我们任务每5分钟跑一次,那么这里指定的可能就是当前时间往前推5分钟的时间范围,比如我们示例代码里面的是 20190501010000
到 20190501010500
, 时间精确到秒。关于KafkaReader更详细的信息可以参考KafkaReader文档。
hdfswriter
, 这里我们使用hdfswriter来写oss数据是因为OSS实现了Hadoop File System的接口,我们可以通过HDFS Writer来向OSS导数据,因为倒过来的数据后面要通过DLA来分析,推荐使用Parquet这种列存格式来保存,目前HDFS Writer支持PARQUET的绝大部分类型,包括基本类型以及复杂类型如array
, map
, struct
, 要以Parquet格式同步数据,我们首先要描述一下这个Parquet的格式, 我们示例数据对应的Parquet的Schema如下:
message test {
required int64 id;
optional binary name (UTF8);
optional int64 gmt_create;
required group map_col (MAP) {
repeated group key_value {
required binary key (UTF8);
required binary value (UTF8);
}
}
required group array_col (LIST) {
repeated group list {
required binary element (UTF8);
}
}
required group struct_col {
required int64 id;
required binary name (UTF8);
}
}复制
上面DataX任务描述文件里面的parquetSchema
字段里面的内容就是上面这段,只不过缩成了一行以保证整个DataX描述文件符合JSON格式。关于Parquet Schema更多的信息可以查看Parquet Logical Type Definitions。
另外一个注意的配置点是 writeMode
, 在我们的这个方案里面,我们推荐使用 truncate
, 因为这个任务是每5分钟调度一次,下一次执行的时候需要把前一次执行的数据清空掉(truncate)。
orders -> orders_p
: DLA任务定时把数据从中间表orders同步到orders_p
拆分的SQL每个具体的业务会不一样,我们这个示例里面比较简单,主要干了两件事:
把原始的 bigint 类型的 gmt_create转成了timestamp类型。
从gmt_create里面生成新的dt字段。
INSERT INTO orders_p
SELECT
id,
name,
from_unixtime(gmt_create), -- bigint -> timestamp
map_col, array_col, struct_col,
cast(date(from_unixtime(gmt_create)) as string) -- 添加分区字段
FROM orders复制
这两个任务的串行操作可以通过任务调度服务比如阿里云上DataWorks来进行串联,在 kafka -> oss
的任务完成后,运行这个 数据拆分
的任务。
总结
这篇文章介绍了如何把Kafka里面的数据实时地流入OSS,利用DLA进行高效的数据分析。借助于DataX对于Parquet复杂类型的支持,我们已经可以帮助用户把各种复杂数据搬进OSS,希望对有类似场景的客户有所帮助。
