




SCN在Oracle的文档上以多种形式出现,一种是System Change Number,一种是System Commit Number,在大多数情况下,Systems Change Numbers的定义更为确切。
1. SCN的定义
SCN(System Change Number),也就是通常我们所说的系统改变号,是数据库中非常重要的一个数据结构,用以标识数据库在某个确切时刻提交的版本。在事务提交时,它被赋予一个唯一的标示事务的SCN。SCN同时被作为Oracle数据库的内部时钟机制,可以被看作逻辑时钟,每个数据库都有一个全局的SCN生成器。
作为数据库内部的逻辑时钟,数据库事务依SCN而排序,Oracle也依据SCN来实现一致性读(Read Consistency)等重要数据库功能,另外对于分布式事务(Distributed Transactions),SCN也极为重要。
SCN在数据库中是唯一的,并随时间而增加,但是可能并不连贯。除非重建数据库,SCN的值永远不会被重置为0。
一直以来,对于SCN有很多争议,很多人认为SCN是指,System Commit Number,而通常SCN在提交时才变化,所以很多时候,这两个名词经常在文档中反复出现。即使在Oracle的官方文档中,SCN也常以System Change/Commit Number两种形式出现。
到底是哪个词其实不是最重要的,重要的是我们需要知道SCN是Oracle内部的时钟机制,Oracle通过SCN来维护数据库的一致性,并通过SCN实施Oracle至关重要的恢复机制。
SCN在数据库中是无处不在的,常见的事务表、控制文件、数据文件头、日志文件、数据块头等都记录有SCN值。冠以不同前缀,SCN也有了不同的名称,比如检查点SCN(checkpoint scn), Resetlogs SCN等等。
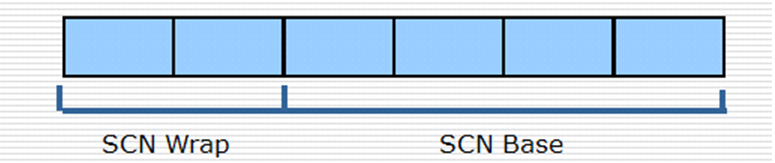
SCN由两部分组成,高位SCN Wrap由2 Bytes记录,低位SCN Base由4 Bytes记录:
SCN的6 Bytes记录,理论上可以存储281 trillion (兆)的数值,这是SCN的极限值:
SQL> select power(2,48) from dual; POWER(2,48) -------------------- 281474976710656复制
虽然SCN理论上可以容纳如此大的值,但是为了控制SCN的异常增长,Oracle也做出了一些限制,在Oracle 11g以前,每秒增进的SCN值不能超过16K,这个数字在11g中增加到32K/秒,最大值可以达到256K/秒。据此计算,在11g之前,SCN至少可以用500年左右:
SQL> select trunc(power(2,48)/12/31/24/3600/16/1024,2) Year from dual; YEAR -------------------- 534.51复制
基于每秒产生SCN的限制,SCN在任意时间的最大允许值就可以被计算出来.
以下两个参数在11g中引入以控制SCN的可能合理值,_max_reasonable_scn_rate用于限制每秒最大产生SCN的数量,_reasonable_scn_offset_seconds用于设定一个用于计算时间的偏移量:
_max_reasonable_scn_rate 32768 Max reasonable SCN rate _reasonable_scn_offset_seconds 0 Reasonable SCN offset seconds复制
最大可能SCN的计算是基于一个固定时间,Oracle 内部使用了一个4G范围的数据来表示01/01/1988 00:00:00 ~ 08/18/2121 06:28:15 这段时间,它的算法简单,每个月都是用31天来表示时间,每增加1秒,这个数值就增加1,有了这个时间起点,再加上每秒允许产生16384个SCN(11g之前),就可以计算当前最大的允许SCN:
col scn for 999,999,999,999,999,999 select ( ( ( ( ( ( to_char(sysdate,'YYYY')-1988 )*12+ to_char(sysdate,'mm')-1 )*31+to_char(sysdate,'dd')-1 )*24+to_char(sysdate,'hh24') )*60+to_char(sysdate,'mi') )*60+to_char(sysdate,'ss') ) * to_number('ffff','XXXXXXXX')/4 scn from dual / SYSDATE SCN --------- ------------------------ 16-JUN-12 12,879,847,825,800复制
当数据库的SCN超过合理值意外增长后,将会出现ORA-00600 2552错误。以下信息就是在数据库出现SCN异常之后抛出的警告:
Mon May 14 17:55:54 2012 Errors in file /t3/orat3/product/admin/ora1020410/bdump/ora1020410_mmon_25386.trc: ORA-00600: internal error code, arguments: [2252], [2988], [9], [], [], [], [], [] Mon May 14 17:56:06 2012 Errors in file /t3/orat3/product/admin/ora1020410/bdump/ora1020410_smon_23805.trc: ORA-00600: internal error code, arguments: [2252], [2988], [13], [], [], [], [], []复制
SCN的大小问题在很长时间内并未得到关注,但是自2012年初,Oracle发布了一个重要的补丁修正,声明数据库可能遇到SCN异常增长导致耗尽的问题,这一问题应当引起关注.
2. SCN的获取方式
可以通过如下几种方式获得数据库的当前或近似SCN。
2.1.从Oracle9i开始
可以通过可以使用dbms_flashback.get_system_change_number来获得
SQL> select dbms_flashback.get_system_change_number from dual; GET_SYSTEM_CHANGE_NUMBER ------------------------ 2982184复制
2.2.Oracle9i前
可以通过查询x$ktuxe获得系统最接近当前值的SCN:
X$KTUXE-------------[K]ernel [T]ransaction [U]ndo Transa[x]tion [E]ntry (table) SQL> select max(ktuxescnw*power(2,32)+ktuxescnb) from x$ktuxe; MAX(KTUXESCNW*POWER(2,32)+KTUXESCNB) ------------------------------------ 2980613复制
2.3.从Oracle10g开始
在v$database视图中增加了current_scn字段,通过查询该字段可以获得数据库的当前SCN值:
SQL> select current_scn from v$database; CURRENT_SCN ----------- 612842复制
2.4.从内存中取得SCN信息
通过oradebug工具可以直接读取内存中用于记录SCN的内存变量:
SQL> oradebug setmypid Statement processed. SQL> oradebug DUMPvar SGA kcsgscn_ kcslf kcsgscn_ [2000C848, 2000C868) = 00000000 000959EA 00000000 00000000 00000000 00000000 00000000 2000C654 SQL> select to_number('959EA','xxxxxx') SCN from dual; SCN --------------------------- 612842复制
3. SCN的进一步说明
系统当前SCN并不是在任何的数据库操作发生时都会改变,SCN通常在事务提交或回滚时改变,在控制文件,数据文件头,数据块,日志文件头,日志文件change vector中都有SCN,但其作用各不相同。
3.1.数据文件头中包含了该数据文件的检查点信息
其中包括Checkpoint SCN,表示该数据文件最近一次执行检查点操作时的SCN。
从控制文件的dump文件中,我们可以得到以下内容:
DATA FILE #1: (name #4) /opt/oracle/oradata/conner/system01.dbf creation size=32000 block size=8192 status=0xe head=4 tail=4 dup=1 tablespace 0, index=1 krfil=1 prev_file=0 unrecoverable scn: 0x0000.00000000 01/01/1988 00:00:00 Checkpoint cnt:273 scn: 0x0000.0023aff1 11/22/2004 17:10:11 Stop scn: 0xffff.ffffffff 11/22/2004 16:58:49 Creation Checkpointed at scn: 0x0000.00000008 10/20/2004 20:59:35 thread:1 rba:(0x1.3.10) 。。。。。复制
对于每一个数据文件都包含一个这样的条目,记录该文件的检查点SCN的值以及检查点发生的时间,这里的Checkpoint SCN、Stop SCN以及Checkpoint Cnt都是非常重要的数据结构,我们将会在下面检查点部分详细介绍。
同样可以通过命令转储数据文件头,观察其具体信息及检查点记录等:
SQL> alter session set events 'immediate trace name file_hdrs level 8'; Session altered. SQL> @gettrcname TRACE_FILE_NAME ---------------------------------------------------------------------------------- /opt/oracle/admin/conner/udump/conner_ora_5862.trc复制
从跟踪文件中摘取SYSTEM表空间的记录作为参考(摘要信息):
DATA FILE #1: (name #4) /opt/oracle/oradata/conner/system01.dbf creation size=32000 block size=8192 status=0xe head=4 tail=4 dup=1 tablespace 0, index=1 krfil=1 prev_file=0 unrecoverable scn: 0x0000.00000000 01/01/1988 00:00:00 Checkpoint cnt:319 scn: 0x0000.002e3016 12/03/2004 06:42:18 Stop scn: 0xffff.ffffffff 12/01/2004 23:37:33 Creation Checkpointed at scn: 0x0000.00000008 10/20/2004 20:59:35 thread:1 rba:(0x1.3.10) Offline scn: 0x0000.001cff67 prev_range: 0 Online Checkpointed at scn: 0x0000.001cff68 11/16/2004 14:10:35 thread:1 rba:(0x1.2.0) Hot Backup end marker scn: 0x0000.00000000 aux_file is NOT DEFINED FILE HEADER: Software vsn=153092096=0x9200000, Compatibility Vsn=134217728=0x8000000 Db ID=3152029224=0xbbe02628, Db Name='CONNER' Activation ID=0=0x0 Control Seq=1093=0x445, File size=32000=0x7d00 File Number=1, Blksiz=8192, File Type=3 DATA Tablespace #0 - SYSTEM rel_fn:1 Creation at scn: 0x0000.00000008 10/20/2004 20:59:35 Backup taken at scn: 0x0000.001aca21 11/14/2004 09:08:34 thread:1 reset logs count:0x20541edb scn: 0x0000.001cff68 recovered at 12/01/2004 23:07:30 status:0x4 root dba:0x004001a1 chkpt cnt: 319 ctl cnt:318 Checkpointed at scn: 0x0000.002e3016 12/03/2004 06:42:18 thread:1 rba:(0x35.2.10) Backup Checkpointed at scn: 0x0000.001aca21 11/14/2004 09:08:34 thread:1 rba:(0xc6.4fff.10)复制
注意,在以上输出中,FILE HEADER部分之前信息来自控制文件,之后信息来自数据文件头,在数据库的启动过程中,需要依赖两部分信息进行比对判断,从而确保数据库的一致性和判断是否需要进行恢复。
3.2.日志文件头中包含了Low SCN,Next SCN
这两个SCN标示该日志文件包含有介于Low SCN到Next SCN的重做信息,对于Current的日志文件(当前正在被使用的Redo Logfile),其最终SCN不可知,所以Next SCN被置为无穷大,也就是ffffffff。
我们来看一下日志文件的情况:
SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM ------- -------- ---------- ---------- ---------- --- -------- ------------- --------- 1 1 50 10485760 1 YES ACTIVE 2973017 02-DEC-04 2 1 51 10485760 1 NO CURRENT 2984378 02-DEC-04 3 1 49 10485760 1 YES INACTIVE 2966611 01-DEC-04 SQL> select dbms_flashback.get_system_change_number from dual; GET_SYSTEM_CHANGE_NUMBER ------------------------ 2984476 SQL> alter system switch logfile; System altered. SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM ------- -------- ---------- ---------- ---------- --- -------- ------------- --------- 1 1 50 10485760 1 YES INACTIVE 2973017 02-DEC-04 2 1 51 10485760 1 YES INACTIVE 2984378 02-DEC-04 3 1 52 10485760 1 NO CURRENT 2984481 02-DEC-04复制
我们看到,SCN 2984476显然位于Log Group#为2的日志文件中,该日志文件包含了SCN自2984378至2984481的redo信息。Oracle在进行恢复时就需要根据低SCN和高SCN来确定需要的恢复信息位于哪一个日志或归档文件中。
如果通过控制文件转储,我们可以在控制文件中找到关于日志文件的信息:
LOG FILE #1: (name #1) /opt/oracle/oradata/conner/redo01.log Thread 1 redo log links: forward: 2 backward: 0 siz: 0x5000 seq: 0x00000011 hws: 0x2 bsz: 512 nab: 0x2 flg: 0x1 dup: 1 Archive links: fwrd: 0 back: 0 Prev scn: 0x0000.0023ac36 Low scn: 0x0000.0023afee 11/22/2004 17:10:06 Next scn: 0x0000.0023aff1 11/22/2004 17:10:11 LOG FILE #2: (name #2) /opt/oracle/oradata/conner/redo02.log Thread 1 redo log links: forward: 3 backward: 1 siz: 0x5000 seq: 0x00000012 hws: 0x2 bsz: 512 nab: 0x19 flg: 0x1 dup: 1 Archive links: fwrd: 0 back: 0 Prev scn: 0x0000.0023afee Low scn: 0x0000.0023aff1 11/22/2004 17:10:11 Next scn: 0x0000.0023b01e 11/22/2004 17:10:54 LOG FILE #3: (name #3) /opt/oracle/oradata/conner/redo03.log Thread 1 redo log links: forward: 0 backward: 2 siz: 0x5000 seq: 0x00000013 hws: 0x1 bsz: 512 nab: 0xffffffff flg: 0x8 dup: 1 Archive links: fwrd: 0 back: 0 Prev scn: 0x0000.0023aff1 Low scn: 0x0000.0023b01e 11/22/2004 17:10:54 Next scn: 0xffff.ffffffff 01/01/1988 00:00:00复制
从以上信息可以注意到,Log File 3是当前的日志文件,该文件拥有的Next SCN为无穷大。同样我们可以通过直接dump日志文件的方式来进行转储:
SQL> select * from v$logfile; GROUP# STATUS TYPE MEMBER ------- -------- ------- ------------------------------------------------------ 1 ONLINE /opt/oracle/oradata/conner/redo01.log 2 ONLINE /opt/oracle/oradata/conner/redo02.log 3 ONLINE /opt/oracle/oradata/conner/redo03.log SQL> alter system dump logfile '/opt/oracle/oradata/conner/redo01.log'; System altered.复制
在trace文件中我们可以看到关于SCN的详细的内容:
DUMP OF REDO FROM FILE '/opt/oracle/oradata/conner/redo01.log' Opcodes *.* DBA's: (file # 0, block # 0) thru (file # 65534, block # 4194303) RBA's: 0x000000.00000000.0000 thru 0xffffffff.ffffffff.ffff SCN's scn: 0x0000.00000000 thru scn: 0xffff.ffffffff Times: creation thru eternity FILE HEADER: Software vsn=153092096=0x9200000, Compatibility Vsn=153092096=0x9200000 Db ID=3152029224=0xbbe02628, Db Name='CONNER' Activation ID=3154332244=0xbc034a54 Control Seq=1084=0x43c, File size=20480=0x5000 File Number=1, Blksiz=512, File Type=2 LOG descrip:"Thread 0001, Seq# 0000000050, SCN 0x0000002d5d59-0x0000002d89ba" thread: 1 nab: 0x15be seq: 0x00000032 hws: 0x2 eot: 0 dis: 0 reset logs count: 0x20541edb scn: 0x0000.001cff68 Low scn: 0x0000.002d5d59 12/02/2004 11:25:40 Next scn: 0x0000.002d89ba 12/02/2004 15:29:42 Enabled scn: 0x0000.001cff68 11/16/2004 14:10:35 Thread closed scn: 0x0000.002d5d59 12/02/2004 11:25:40 Log format vsn: 0x8000000 Disk cksum: 0xd79c Calc cksum: 0xd79c复制




