




常规检查点与增量检查点
为了理解常规检查点和增量检查点的概念,首先需要介绍一下脏缓冲列表(LRUW List)。前面提到,当数据在Buffer Cache中被修改之后,Dirty Buffer会被转移到LRUW List,以便将来执行的检查点可以将这些修改过的Buffer写出到数据文件上。
但是注意,由于LRUW List上的Buffer并没有严格顺序,有的Buffer反复被修改,在写出之前,可能会被从LRUW移动回AUXILIARY lru list,当这样的Dirty Buffer再次回到LRUW列表时,会倍添加到链表尾部,也就是说一个Buffer在LRUW链表上的位置可能发生变化,所以当检查点发生时,Oracle需要将脏缓冲列表上的数据全部写出到数据文件。
为了区分,在Oracle8之前,Oracle实施的这类检查点通常被称为常规检查点(Conventional Checkpoint),由于检查点时需要写出全部的脏数据,所以也被称为完全检查点(Complete Checkpoint)。
常规检查点按特定的条件触发(log_checkpoint_interval,log_checkpoint_timeout参数设置及log switch等条件触发),触发时会同时更新数据文件头以及控制文件记录检查点信息。
从Oracle8开始,Oracle演进了新的算法,进而引入了增量检查点(Incremental Checkpoint)的概念。
和以前的版本相比,在新版本中,主要的变化是引入了检查点队列(Buffer Checkpoint Queue - CKPTQ)机制。在数据库内部,每一个脏数据块都会被记录到检查点队列,按照LRBA(Low RBA - 第一次对此数据块修改对应的Redo Byte Address)的顺序来排列,如果一个数据块进行过多次修改,该数据块在检查点队列上的顺序并不会发生变化(相对于LRBA,后面修改的RBA被称为HRBA)。
检查点队列的内存存储空间在Shared Pool内存中分配:
SQL> select * from v$sgastat where upper(name) like '%CHECKPOINT%'; POOL NAME BYTES ------------ -------------------------- ---------- shared pool Checkpoint queue 410624 shared pool log_checkpoint_timeout 12360复制
当执行增量检查点时,DBWR从检查点队列按照Low RBA的顺序写出,此时先修改的数据就可以被按顺序优先写出,实例检查点因此可以不断增进,阶段性的,CKPT进程使用非常轻量级的控制文件更新协议,将当前的最低RBA(也即Low Cache RBA)写入控制文件,为了减少频繁增量检查点的性能影响,CKPT在进行轻量级更新时,并不会改写控制文件中数据文件的检查点信息以及数据文件头信息,而只是记录控制文件检查点SCN(Controlfile Checkpointed at scn)并且根据增量检查点的写出增进RBA信息,同时不需要更改数据文件头信息。
通过增量检查点,数据库可以将以前的全量写出变更为增量渐进写出,从而可以极大的减少对于数据库性能的影响;而检查点队列则进一步的将RBA和检查点关联起来,从而可以通过检查点来确定恢复的起点。
增量检查点的进度可以通过X$KCBBES表来查询,该表的含义为:
X$KCBBES— [K]ernel [C]ache [B]uffer Management Buffer Event Statistics复制
该视图记录了内存中Buffer的写出统计,其中INDX为 4的条目即增量检查点写出的Buffer数量:
SQL> desc x$kcbbes Name Null? Type ----------------------------- -------- ---------------------------- ADDR RAW(8) INDX NUMBER INST_ID NUMBER REASON NUMBER PRIORITY NUMBER SAVECODE NUMBER SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - 64bit Production SQL> select * from x$kcbbes where reason >0; ADDR INDX INST_ID REASON PRIORITY SAVECODE ---------------- ----- ---------- --------- ---------- ---------- 00002B37AA4429E8 2 1 480 199 71 00002B37AA4429E8 4 1 199 0 7 00002B37AA4429E8 9 1 6 0 0 00002B37AA4429E8 11 1 784125 0 0 00002B37AA4429E8 12 1 284 0 0复制
反复查询该视图可以观察增量检查点的进度,如果REASON值增加则意味着检查点在增进,如果不变,则意味着检查点未发生(注意,即便是增量检查点其发生也可能间隔较长时间)。
SQL> select * from x$kcbbes where indx=4; ADDR INDX INST_ID REASON PRIORITY SAVECODE ---------------- ---------- ---------- ---------- ---------- ---------- 00002AC45797C2F8 4 1 5884 0 7 SQL> select * from x$kcbbes where indx=4; ADDR INDX INST_ID REASON PRIORITY SAVECODE ---------------- ---------- ---------- ---------- ---------- ---------- 00002AC4579578A0 4 1 5893 0 7复制
检查点队列在数据库内部通过Latch保护:
SQL> select name,gets,misses from v$latch where name='checkpoint queue latch'; NAME GETS MISSES ------------------------------------ ---------- ---------- checkpoint queue latch 14710851 0复制
Checkpoint Queue Latch存在多个子Latch,可以通过V$LATCH_CHILDREN视图查询:
SQL> select name,gets,misses from v$latch_children where name='checkpoint queue latch'; NAME GETS MISSES ---------------------------------------- ---------- ---------- checkpoint queue latch 917660 0 checkpoint queue latch 917660 0 checkpoint queue latch 917660 0 checkpoint queue latch 917660 0 checkpoint queue latch 917660 0 checkpoint queue latch 917660 0 checkpoint queue latch 917660 0 checkpoint queue latch 917660 0 checkpoint queue latch 917660 0 checkpoint queue latch 917660 0 checkpoint queue latch 924547 0 checkpoint queue latch 927484 0 checkpoint queue latch 920711 0 checkpoint queue latch 920711 0 checkpoint queue latch 920711 0 checkpoint queue latch 920711 0复制
除了检查点队列(CKPTQ)之外,数据库中还存在另外一个队列和检查点相关,这就是文件检查点队列-FILE QUEUE,通常缩写为FILEQ,文件检查点队列的引入提高了表空间检查点(Tablespace Checkpoint)的性能。
每个Dirty Buffer同时链接到这两个队列, CKPTQ包含实例所有需要执行检查点的Buffer,FILEQ包含属于特定文件需要执行检查点的Buffer,每个文件都包含一个文件队列,在执行表空间检查点请求时需要使用FILEQ,通常当对表空间执行Offline等操作时会触发表空间检查点。
在Buffer Chache中,每个Buffer的Header上都存在CKPTQ以及FILEQ队列信息,通过如下命令可以转储Buffer Cache信息(注意应当仅在测试环境中尝试):
alter session set events 'immediate trace name buffers level 10';复制
以下BH信息来自Oracle9i 9.2.0.4数据库环境:
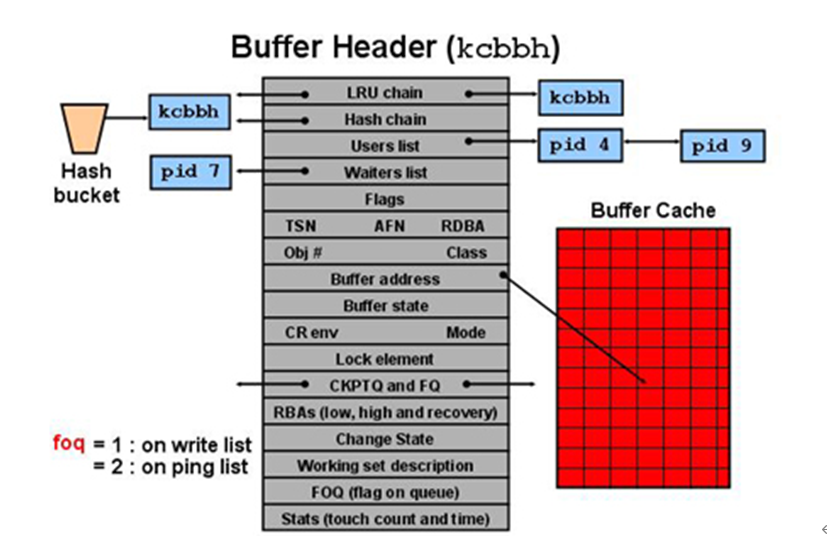
BH (0x0x55fba950) file#: 2 rdba: 0x0080008c (2/140) class 34 ba: 0x0x553d8000 set: 3 dbwrid: 0 obj: -1 objn: 0 hash: [54ee90b0,57476608] lru: [55fbaa54,55fba8dc] LRU flags: ckptq: [55feb234,55ffce68] fileq: [55ffcf2c,55ffce70] st: XCURRENT md: NULL rsop: 0x(nil) tch: 31 flags: buffer_dirty gotten_in_current_mode block_written_once redo_since_read LRBA: [0x1d.38e.0] HSCN: [0x081b.dc808434] HSUB: [1] RRBA: [0x0.0.0] buffer tsn: 1 rdba: 0x0080008c (2/140) scn: 0x081b.dc808434 seq: 0x01 flg: 0x00 tail: 0x84340201 frmt: 0x02 chkval: 0x0000 type: 0x02=KTU UNDO BLOCK复制
注意摘录信息中的CKPTQ和FILEQ,这就是检查点队列和文件队列。每个队列后面记录了两个地址信息,分别是前一块以及下一块的地址,通过这个信息CKPTQ和FILEQ构成了双向链表。注意仅Dirty Buffer才会包含CKPTQ信息,否则为NULL,信息类似:ckptq: [NULL] fileq: [NULL]。
同样对上一个跟踪文件进行grep信息输出,来看一下这两个队列:
[oracle@jumper udump]$ grep ckptq eygle_ora_1467.trc |grep -v NULL ckptq: [55fba708,56374c18] fileq: [55fba710,56374c70] ckptq: [55ffccf0,55ffd504] fileq: [55ffccf8,55ffd50c] ckptq: [55fbaab4,55fba880] fileq: [55fbaabc,55fba888] ckptq: [55fba880,55fba7c4] fileq: [55fba888,55fba7cc] ckptq: [55ffd09c,55ffcfe0] fileq: [55ffd0a4,55ffcfe8] ckptq: [55fba64c,55feb234] fileq: [55fba654,55fbaa00] ckptq: [55feb3ac,55ffcf24] fileq: [574d0c08,55ffcf2c] ckptq: [55fba9f8,574d0bb0] fileq: [55fbaa00,574d0c08] ckptq: [55feb234,55ffce68] fileq: [55ffcf2c,55ffce70] ckptq: [55fba7c4,55fba708] fileq: [55fba7cc,55fba710] ckptq: [56374c18,55ffd09c] fileq: [56374c70,55ffd0a4] ckptq: [55ffcfe0,55ffccf0] fileq: [55ffcfe8,55ffccf8] ckptq: [55ffcf24,55fba9f8] fileq: [55feb3b4,574d0bdc] ckptq: [574d0bb0,55fba64c] fileq: [574d0bdc,55feb23c]复制
简单整理一下CKPTQ,其顺序就是(对于):
55fbaab4->55fba880->55fba7c4->55fba708->56374c18->55ffd09c->55ffcfe0->55ffccf0->55ffd504 55feb3ac->55ffcf24->55fba9f8->574d0bb0->55fba64c->55feb234->55ffce68复制
在SGA中存在一块内存区域用于记录这个检查点队列:
SQL> select name,bytes from v$sgastat where upper(name) like '%CHECKPOINT%'; NAME BYTES ---------------------------------------- ---------- Checkpoint queue 282304复制
从Oracle10g开始,数据库中额外增加了对象检查点队列(Object Queue - OBJQ)用于记录对象检查点信息:
BH (0x273f092c) file#: 1 rdba: 0x00401009 (1/4105) class: 1 ba: 0x271ec000 set: 6 blksize: 8192 bsi: 0 set-flg: 2 pwbcnt: 133 dbwrid: 0 obj: 517 objn: 517 tsn: 0 afn: 1 hash: [5ebae9b8,5ebae9b8] lru: [273f0a30,273f08d0] lru-flags: ckptq: [243ea704,277f0c14] fileq: [5e4b08d4,277f0c1c] objq: [277f0c94,273f0874] st: XCURRENT md: NULL tch: 2 flags: buffer_dirty gotten_in_current_mode block_written_once redo_since_read LRBA: [0x38.11a97.0] HSCN: [0x81b.8f844f3e] HSUB: [1] buffer tsn: 0 rdba: 0x00401009 (1/4105) scn: 0x081b.8f844f3e seq: 0x01 flg: 0x02 tail: 0x4f3e0601 frmt: 0x02 chkval: 0x0000 type: 0x06=trans data复制
下图是Buffer Header的结构示意图,对照以上Buffer Header转储信息可以更加清晰的了解BH的结构:
共享池中分配了相关内存用于OBJECT QUEUE:
SQL> select * from v$sgastat where name like 'object queue%'; POOL NAME BYTES ------------ -------------------------- ---------- shared pool object queue hash table d 6080 shared pool object queue hash buckets 139264 shared pool object queue 49056复制
了解了几种队列之后,下面让我们来看一下控制文件以及增量检查点的协同工作。以下输出来自Oracle 11g测试环境,两次Level 8级控制文件转储,时间间隔有8分钟左右(去除了一点次要信息)。
第一部分重要信息是控制文件的Seq号,控制文件随着数据库的变化而增进版本:
[oracle@localhost trace]$ diff 11gtest_ora_24951.trc 11gtest_ora_25106.trc < DUMP OF CONTROL FILES, Seq # 1781 = 0x6f5 --- > DUMP OF CONTROL FILES, Seq # 1782 = 0x6f6 42c28 < Control Seq=1781=0x6f5, File size=594=0x252 --- > Control Seq=1782=0x6f6, File size=594=0x252复制
接下来是控制文件检查点SCN,增量检查点不断增进的内容之一:
85c71 < Controlfile Checkpointed at scn: 0x0000.00095a4c 07/07/2008 11:27:56 --- > Controlfile Checkpointed at scn: 0x0000.00095ae6 07/07/2008 11:33:46复制
检查点记录之后是RBA信息,检查点和Redo相关联在这里实现,通过以下信息可以注意到,通过增量检查点之后,Dirty Buffer数量从47降低到7,而Low Cache RBA从0x1d.4b1.0增进到0x1d.518.0,LOW Cache RBA是下一次恢复的起点,而On Disk RBA则是指已经写入磁盘(Redo Log File)的RBA地址,这是前滚恢复能够到达的终点,增量检查点的作用由此体现:
114,116c100,102 < THREAD #1 - status:0x2 flags:0x0 dirty:47 < low cache rba:(0x1d.4b1.0) on disk rba:(0x1d.515.0) < on disk scn: 0x0000.00095a78 07/07/2008 11:28:18 --- > THREAD #1 - status:0x2 flags:0x0 dirty:7 > low cache rba:(0x1d.518.0) on disk rba:(0x1d.525.0) > on disk scn: 0x0000.00095ada 07/07/2008 11:33:07复制
最后一部分是Heartbeat心跳信息,每3秒更新一次用于验证实例的存活性,第一章中已经有所提及:
118c104 < heartbeat: 659472703 mount id: 1478358445 --- > heartbeat: 659472842 mount id: 1478358445复制
通过以上分析可以清晰的看到增量检查点的实施过程,因为增量检查点可以连续的进行,所以检查点RBA可以比常规检查点更接近数据库的最后状态,从而在数据库的实例恢复中可以极大的减少恢复时间。
而且,通过增量检查点,DBWR可以持续进行写出,从而避免了常规检查点出发的峰值写入对于I/O的过度争用,通过下图可以清楚的看到这一改进的意义:
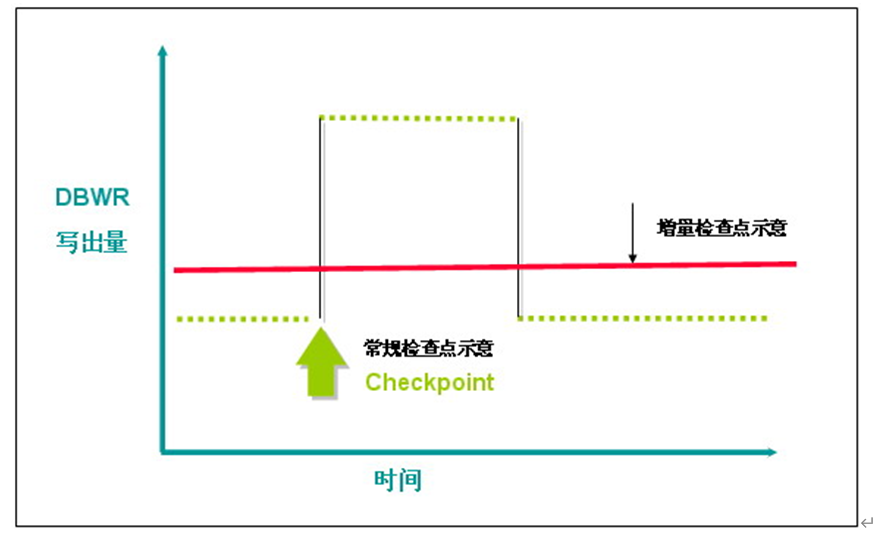
显而易见的是,增量检查点明显优于常规的完全检查点,所以在引入检查点队列之后,数据库正常情况下执行的都是增量检查点,从Oracle8i开始,完全检查点仅在以下两种情况下出现:
- ALTER SYSTEM CHECKPOINT
- SHUTDOWN (除ABORT方式外)
LOG SWITCH事件同样触发的是增量检查点,但是在LOG SWITCH触发的检查点会促使数据文件头与控制文件信息的同步(数据文件头的写操作并非每次Log Switch检查点都会发生)。
如前所述,我们知道每个Buffer都可能和ckptq、fileq、objq相关联,从而检查点也就有了不同的分类,常见的分类有:Full Checkpoint、Thread Checkpoint、File Checkpoint、Object Checkpoint、Parallel Query Checkpoint、Incremental Checkpoint、Log Switch Checkpoint.
