




嗯,首先承认,做了回标题党(另外也是因为确实没想到更好的标题,求轻拍)。由于修复及时,最终并没有对线上用户产生任何影响,血案也并没有发生。
工作三年半了,第一次碰到了mysql死锁,老实说当时还挺开心的😆
1.案件回顾
去年平安夜,笔者参与的一个项目如期上线。作为一名老司机,一切都是那么轻车熟路。发布完成的那一刻,嘴角不自觉浮起了一丝不易察觉的微笑,然而我不知道的是,危险正在一步步靠近。
在随后QA同学和产品同学的线上验收过程中,发现有极高的概率会出现支付失败的场景。从当时的日志来看,这是由于数据库死锁引起的,如下图所示:

案发现场死锁日志.png
预发环境验证得好好的,为什么一到线上就会有极高的概率出现死锁呢?笔者仔细分析了出现死锁的sql,发现在上线前对该sql有微小的改动,当时也是为了修复一个有极低概率出现的问题。只是当时修改以后只对相关流程进行了一次验证,而刚好那一次没有出现死锁,所以这个有问题sql就这样被错误地发布到了线上环境。
作为一个美业SAAS产品,开单支付链路是绝对的核心场景,保证该流程的稳定是一等一的大事。考虑到短时间内彻底定位修复该问题不太现实,为了保证线上环境的稳定,笔者当时紧急对这个有问题的sql进行了回滚,由于当时已接近午夜,再加上发布的是一个新功能,所以并没有对线上用户造成任何影响,笔者就这样与一场血案擦肩而过...
线上问题处理首要原则:第一时间解决问题,保留现场事后分析。
2.案情分析
第二天一早,笔者迫不及待仔细分析了日志,找到了发生死锁的两个事务,相关sql简化处理后如下,事务隔离级别为RC:
事务1:
update table_name set colume1 = 2 where kdt_id = 6666 and order_no = 'M1' and pay_no = 'P1' and colume1 in (1, 2, 3) limit 1;复制
事务2:
update table_name set colume1 = 3 where kdt_id = 6666 and order_no = 'M1' and pay_no = 'P1' limit 1;复制
其中表table_name的索引信息如下:
PRIMARY KEY (`id`), KEY `idx_kdt_order` (`kdt_id`,`order_no`), KEY `idx_payno_kdt` (`pay_no`,`kdt_id`), KEY `idx_kdt_asset_detail_no` (`kdt_id`,`asset_detail_no`)复制
同时查看两个update语句的执行计划,发现二者走的是同一个idx_payno_kdt这个二级索引。既然走的是同一个二级索引,按照常规加锁套路,mysql会首先对这个二级索引加锁,然后对主键加锁。两个sql的加锁顺序应该完全一样,既然如此,何来死锁?此时,笔者陷入了漫长的沉思。
3.连环作案?
毕竟是第一次处理死锁案例,几天下来毫无进展。正当我手足无措之时,一封告警邮件映入眼帘。笔者如炬的目光被那个熟悉的朋友给深深地吸引住了——DeadLock。我勒个乖乖,还是个连环案啊。有意思了,二话不说,先拿到触发死锁的sql。
事务1:
UPDATE table_name SET`asset_detail_no`='xx',`ext_pay_info`='xx'`updated_at`='2019-01-02 17:02:57'where `kdt_id`=6666 and `order_no`='M1' and `pay_no`='P1' limit 1;复制
事务2:
UPDATE table_name SET`pay_result`=1,`pay_status`=3,`updated_at`='2019-01-02 17:02:57'where `kdt_id`=6666 and `order_no`='M1' and `pay_no`='P1' limit 1复制
同样,两个update语句都走的是idx_payno_kdt这个二级索引。同时由于上一次的经验,这次马上联系DBA拿到了死锁日志:
------------------------ LATEST DETECTED DEADLOCK ------------------------2019-01-02 17:02:57 0x7f8ed339d700*** (1) TRANSACTION:TRANSACTION 154905880096, ACTIVE 0 sec starting index read mysql tables in use 1, locked 1LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s) MySQL thread id 10519814, OS thread handle 140251427940096, query id 37831367279 10.96.0.7 beauty updating UPDATE table_name SET `asset_detail_no`='xx', `ext_pay_info`='xx', `updated_at`='2019-01-02 17:02:57' where `kdt_id`=6666 and `order_no`='M1' and `pay_no`='P1' limit 1*** (1) WAITING FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 3208 page no 28442 n bits 112 index PRIMARY of table `db_name`.`table_name` trx id 154905880096 lock_mode X locks rec but not gap waiting *** (2) TRANSACTION:TRANSACTION 154905880094, ACTIVE 0 sec starting index read, thread declared inside InnoDB 5000mysql tables in use 1, locked 15 lock struct(s), heap size 1136, 3 row lock(s) MySQL thread id 10521136, OS thread handle 140251405866752, query id 37831367285 10.96.0.16 beauty updating UPDATE `table_name` SET `pay_result`=1, `pay_status`=30, `pay_at`='2019-01-02 17:02:57', `updated_at`='2019-01-02 17:02:57' where `kdt_id`=6666 and `order_no`='M1' and `pay_no`='P1' limit 1*** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 3208 page no 28442 n bits 112 index PRIMARY of table `db_name`.`table_name` trx id 154905880094 lock_mode X locks rec but not gap *** (2) WAITING FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 3208 page no 28233 n bits 160 index idx_payno_kdt of table `db_name`.`table_name` trx id 154905880094 lock_mode X locks rec but not gap waiting *** WE ROLL BACK TRANSACTION (1)复制
有了死锁日志,很多东西都一目了然,其作用简直堪比车祸现场的行车记录仪啊!
从以上死锁日志中我们可以看到死锁究竟是如何发生的:
事务1在等等表的主键锁,而事务2持有主键锁,在等待二级索引idx_payno_kdt上的锁。既然发生了死锁,说明事务1应该是持有了idx_payno_kdt的锁(但是这个在死锁日志中并无记录),从而导致两个事务互相等待对方持有的锁。
4.案件合并
虽然两次死锁发生的sql语句并不完全一样,但都是因为两个事务对同一张表进行update引起的。而且由于show engine innodb status只能记录最近一次发生的死锁,所以我们对第一次死锁已无法拿到更多现场信息。再结合业务场景,笔者决定对两案合并一案进行分析。
线上死锁定位首要原则:第一时间拿到死锁日志协助分析。
在案件2中,我们目前最大的疑问是:事务2怎么拿到主键锁的?是因为发生了index_merge优化吗(具体可参考index_merge引发的死锁排查)?
但是通过查看执行计划,我们发现两个update语句执行计划中的type值都是range,即都没有走index_merge优化,此路不通😔
既然跟index_merge没有关系,还有什么情况可能会导致事务2持有主键锁呢?笔者再次陷入了沉思...
在整个案件的分析过程中,笔者其实一直在跟DBA保持沟通(一个会做饭的暖男,技术很牛逼,积累了很多定位线上mysql问题的经验并以博客形式输出,传送门:For DBA)。期间DBA的一个思路给了我启发,他说因为表table_name中存在多个二级索引,在where条件中,order_no和pay_no分别是两个二级索引中的字段,有可能是在某种条件下,事务2先走了idx_kdt_order索引,从而通过该索引拿到了主键锁。
然而事务2的执行计划清清楚楚明明白白地告诉我们,该update语句只走了idx_payno_kdt这个一个二级索引,那么可能会有什么场景触发其先走idx_kdt_order这个索引呢?
哦对了!笔者突然灵光一现,死锁日志只会记录发生死锁的sql语句,但是一个事务中可能会有多个sql语句,在发生死锁之前的sql语句都不会被记录到死锁日志中!
想到这一点,笔者隐隐感觉真相越来越近了。由于对案件分析已经断断续续持续了10来天,我不用继续翻代码都知道事务2在执行update语句之前还执行了一个select语句,并且刚好走了idx_kdt_order这个索引,该select语句如下:
select * from table_name where kdt_id=6666 and order_no=‘M1' and pay_status in (3, 5) for update;复制
在该语句中,事务2会通过idx_kdt_order这个二级索引持有主键锁,这就完美地解释了我们之前的疑问。正是这个select ... for update语句的存在,导致了两个事务的加锁顺序发生了不一致,从而引发死锁。
我想,案发现场当时的情况应该是这样的:
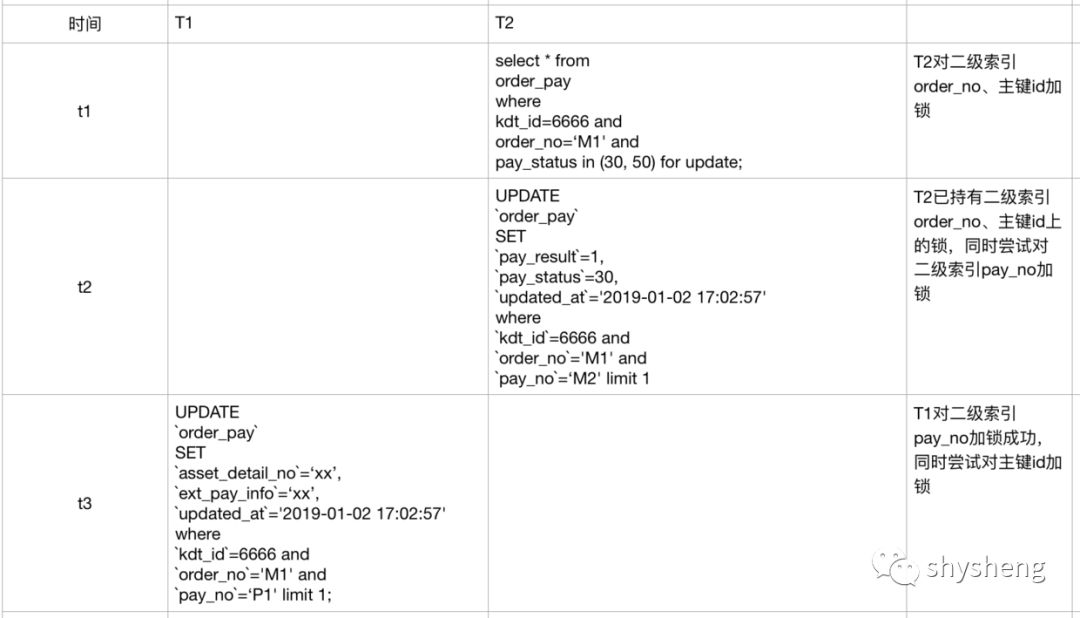
image.png
5.真相大白?No!
至此,案情似乎真相大白了,罪魁祸首正是这个select ... for update语句。然而,事实果真如此吗?
在跟DBA的沟通过程中,笔者还得到一个信息就是,在RC隔离级别下,针对select ... for update语句,如果最终返回结果集为空,那么mysql会对此进行了一些优化,加上的X锁会提前释放(详细分析可参考MySQL加锁处理分析)。
本着实践出真知的原则,笔者在本地mysql对此进行了验证,其中t1与线上环境发生死锁的table_name完全一致,且满足kdt_id=6666 and order_no='M1'条件的记录有两条,但它们的pay_status状态都不是30或者50,也就是说,事务1返回的结果集为空。
事务1:
begin; select * from order_t1 where kdt_id=6666 and order_no='M1' and pay_status in (30, 50) for update;复制
事务2:
begin ; UPDATE t1 SET`updated_at`='2019-01-02 17:02:57'where `kdt_id`=6666 and `order_no`='M1' and `pay_no`='P1' limit 1;复制
先执行事务1,再执行事务2,在RR级别下,事务2确实会被阻塞,但是在RC级别下却不会。
这也完美映证了DBA的说法,针对select ... for update语句,在RC隔离级别下,如果返回结果集为空,那么针对行记录加上的X锁会被提前释放,不会阻塞其它事务加锁。
既然会提前释放,那么案例2中,事务2又是如何获得X锁的呢?真相似乎近在眼前,却又远在天边😔
不过到了这里,案例2虽然依然疑点重重,案例1却似乎柳暗花明了。因为在案例1中,事务2的update之前也有一个类似的select... for update语句如下:
select * from order_t1 where kdt_id=6666 and order_no='M1' for update;复制
只不过与案例2的相比,where条件中没有使用pay_status字段进行过滤,也就是说这个语句的结果集不为空!那么对于案例1来说,事务2在执行udpate语句之前就真的会通过idx_kdt_order持有主键锁,从而触发死锁!
6.真相?吾将上下而求索
到了这里,离第一次出现死锁已过去差不多两个星期,案例1已真相大白,但案例2却依然存疑。
因此笔者决定,要是年会之前还没有水落石出,就打飞的过去活捉DBA现场结对编程😆待真相大白后再来跟小伙伴们分享
