






空间索引作为一种辅助性的空间数据结构,空间索引介于空间操作算法和空间对象之间,它通过筛选作用,大量与特定空间操作无关的空间对象被排除,从而提高空间操作的速度和效率 [1]。
通俗的来讲,空间索引的存在就是为了提高查询效率,避免因为SQL查询缓慢而带来软件使用上的不良体验。PostgreSQL的空间索引主要有以下6种 B-tree、Hash、GiST、SP-GiST 、GIN 和 BRIN,每一种空间索引都对应了一种算法来实现其对应的查询情况。接下来,我们依次来学习以上的索引类型。
B-tree索引:
B-tree索引可以在可排序数据上处理等值和范围查询。默认情况下创建不指定类型的索引,其实现途径就是B-TREE索引。特别地,PostgreSQL的查询规划器会在任何一种涉及到以下操作符的已索引列上考虑使用B-tree索引:
| 小于 | 大于 | 等于 | 小于等于 | 大于等于 |
| < | > | = | <= | >= |
#创建B-TREE索引create index id_idx on table user (name,age)复制
此外,在您的SQL语句中出现了这些条件关键字也会使用B-TREE索引,如:BETWEEN和IN,以及 IS NULL、IS NOT NULL。虽然B-TREE索引不会100%的让您的查询更快,但是在处理可排序的等值和范围查询时使用B-TREE索引总会起到较好的效果。
Hash索引:
Hash作用主要用于处理等值比较,只要您操作的索引列使用了=操作符,则可以选择Hash索引。
# 创建Hash索引CREATE INDEX name ON user USING HASH (sex);复制
GiST索引:
GiST索引根据官网的介绍,它更像是索引类型里的基础设施,查询规划器可以根据不同类型的操作符来使用不同策略的索引。
GisT的操作符如下图所示:
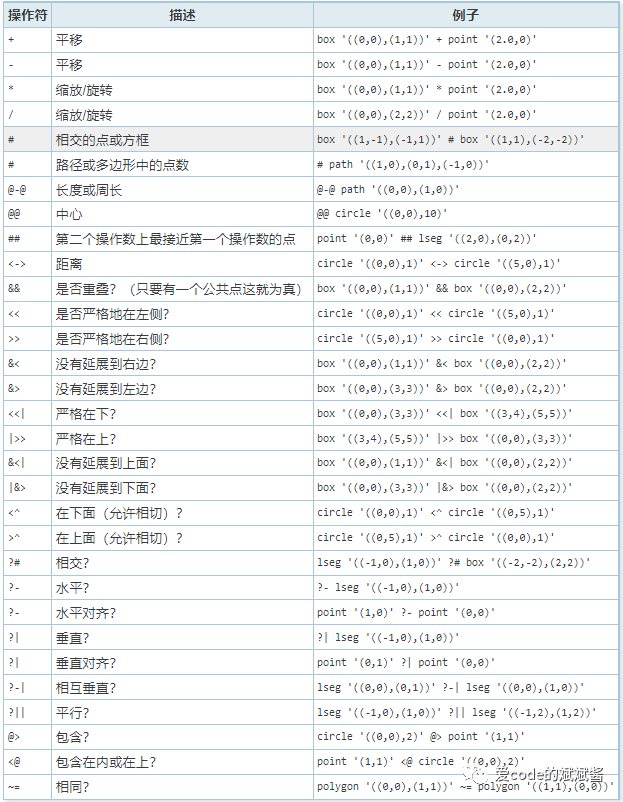
截图来源于PostgreSQL中文社区官网
GisT作为PostgreSQL内置的空间数据索引类型,也有能力去优化最近邻的查询。记得2019年我在公司实习的时候,就遇到了此类需求,前端传给我一个POINT,我需要返回离这个最近的10个GEOMETRY,当时不了解空间索引,经验也不够,后来请教了以为阿里云的数据库专家得以解决这个“简单”的问题,直到现在我依然很感谢这位专家。
#GisT最近邻搜索SELECT * FROM area ORDER BY location <-> point '(108.1,34.1)' LIMIT 10;复制
根据上表的所列出的GisT操作符,我们可以看出<->操作符,其实操作的就是距离, 它能够返回我们给定的GEOMETRY与所操作列的距离,我们只需要对距离结果排序,然后limit,就可以拿到我们想要的结果。可能会有同学担心,如果数据量很大的情况下,性能会不会很差,当然啦,这个您不用担心,GisT索引已经帮我们在底层做好了优化,如果您的数据量确实很大,比如百万级或者千万级,甚至是亿级的话,GisT的能力表现确实会有局限性。这个时候就需要您从额外的角度去优化您的SQL语句,以减轻GisT索引的压力,进而达到您需要的查询性能。
BRIN 索引:
BRIN索引存储有关存放在一个表的连续物理块范围上的值摘要信息,这句话比较抽象,我们后面解释。BRIN索引也适合很多种不同的索引策略类型,这个主要取决于您在SQL使用的BRIN操作符,BRIN的操作符如下表所示:
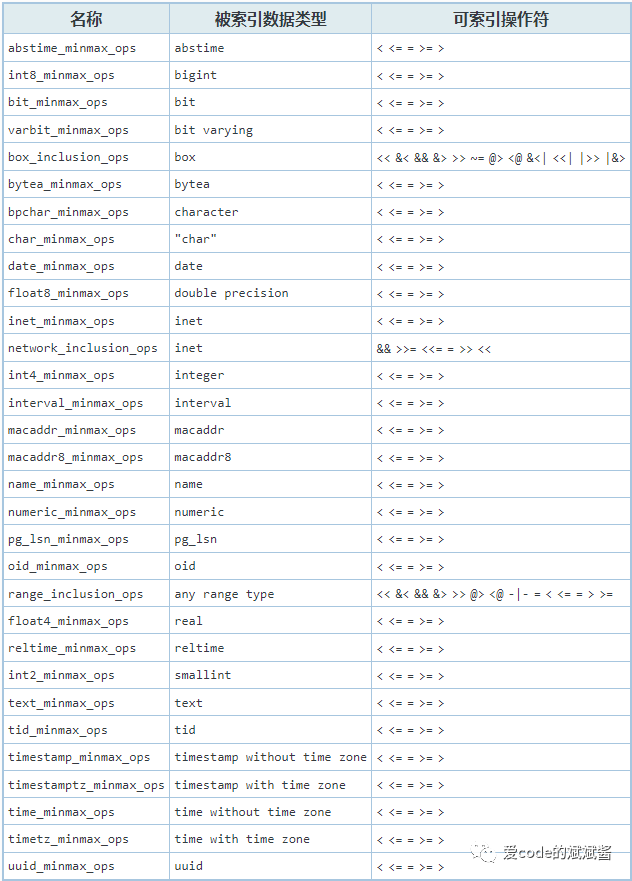
截图来源于PostgreSQL中文社区官网
现在我们解释一下,为什么BRIN索引存储有关存放在一个表的连续物理块范围上的值摘要信息。大家应该都知道计算机的存储实际上是由硬盘上紧密排列的存储块来完成存储功能的,这个和大型存储服务器上的磁盘阵列感觉很类似。同样的PostgreSQL的数据存储,也引入了块的概念。比如,我们删除一张表,并且这张表很大,我们drop这张表的时候,不是我们视觉上这张表一下子就被整个删除了,而是PostgreSQL会在磁盘上按照数据存储块的逻辑这张表所占用的块一个一个删除,才算将这张表删除了。BRIN索引的功能,我推测它存储了每张表下面的每个块的最大值和最小值。依靠这种类似于降级的查询数量来提高查询速度。这个猜想仅代表我的个人观点哈~
多列索引:
多列索引严格来讲并不是一种索引类型,只是上文列出的索引类型的索引方式。目前来讲,只有 B-tree、GiST、GIN 和 BRIN 索引类型支持多列索引,最多可以指定32个列(该限制可以在源代码文件pg_config_manual.h
中修改,但是修改后需要重新编译PostgreSQL)。如果您需要修改多列索引所支持的最大值,这样就需要您在选择软件安装包的时候,得选择源代码编译安装,这个过程虽然不难,但是比较费时,如果您有兴趣可以自己私下研究。
#创建多列索引create index name_sex_age_idx on user (name,sex,age) ;复制
SP-GiST索引:
与GisT索引类似,为支持多种搜索提供了一种基础结构。SP-GiST 允许实现众多不同的非平衡的基于磁盘的数据结构,例如四叉树、k-d树和radix树。根据索引的命名方式就可以看出SP-GisT索引是基于GisT索引改进而来的索引类型。SP-GisT索引的操作符如下表所示:
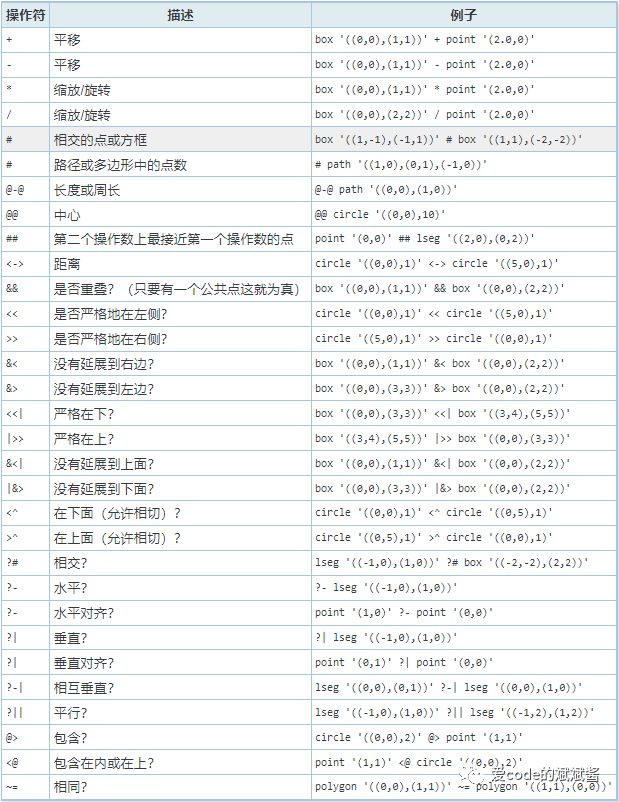
截图来自PostgreSQL中文社区官网
GIN索引:
GIN 索引是"倒排索引",它适合于包含多个组成值的数据值,例如数组。倒排索引中为每一个组成值都包含一个单独的项,它可以高效地处理测试指定组成值是否存在的查询。
与 GiST 和 SP-GiST相似, GIN可以支持多种不同的用户定义的索引策略和特定操作符,通过它一个GIN索引可以被根据索引策略被使用。作为一个例子,PostgreSQL的标准捐献包中包含了用于一维数组的GIN操作符类,它用于支持使用下列操作符的索引化查询:
GIN索引操作符如下表所示:
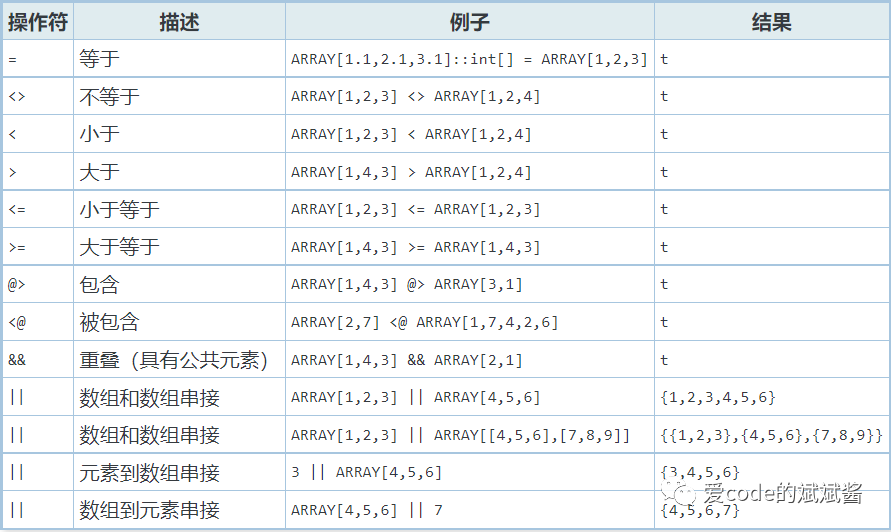
截图来自PostgreSQL中文社区官网
索引和ODER BY:
在目前的索引类型中只有B-TREE索引可以将结果按照特定的顺序返回,其他索引类型的返回结果是以无序排列返回的。但是在实际的工作中,我们肯定会有将索引的结果按照特定顺返回的需求,因此在索引中使用ODER BY的需求就应运而生。
您可以在创建B-tree索引时通过ASC
、DESC
、NULLS FIRST
和NULLS LAST
选项来改变索引的排序,例如:
# 首先将info列为空的第一个结果返回CREATE INDEX test2_info_nulls_low ON test2 (info NULLS FIRST);#将id倒排并返回最后一个为空的结果CREATE INDEX test3_desc_index ON test3 (id DESC NULLS LAST);复制
组合多个索引:
只有查询子句中在索引列上使用了索引操作符类中的操作符并且通过AND
连接时才能使用单一索引。例如,给定一个(a, b)
上的索引,查询条件WHERE a = 5 AND b = 6
可以使用该索引,而查询WHERE a = 5 OR b = 6
不能直接使用该索引。
幸运的是,PostgreSQL具有组合多个索引(包括多次使用同一个索引)的能力来处理那些不 能用单个索引扫描实现的情况。系统能在多个索引扫描之间安排AND
和OR
条件。例如, WHERE x = 42 OR x = 47 OR x = 53 OR x = 99
这样一个查询可以被分解成为四个独立的在x
上索引扫描,每一个扫描使用其中一个条件。这些查询的结果将被“或”起来形成最后的结果。另一个例子是如果我们在x
和y
上都有独立的索引,WHERE x = 5 AND y = 6
这样的查询的一种可能的实现方式就是分别使用两个索引配合相应的条件,然后将结果“与”起来得到最后的结果行[2]。
唯一索引:
索引也可以被用来强制列值的唯一性,或者是多个列组合值的唯一性。当前,只有B-tree能够被声明为唯一。
# 唯一索引CREATE UNIQUE INDEX name ON table (column [, ...]);复制
表达式索引:
一个索引列并不一定是底层表的一个列,也可以是从表的一列或多列计算而来的一个函数或者标量表达式。这种特性对于根据计算结果快速获取表中内容是有用的。
# 创建表达式索引CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1));复制
如果我们将该索引声明为UNIQUE
,它将阻止创建在col1
值上只有大小写不同的行,这种特性使得我们的查询会变得更为简洁,并且具备一定的容错能力。
# 创建表达式索引CREATE UNIUQE INDEX test1_lower_col1_idx ON test1 (lower(col1));复制
我们再来看一个表达式索引的例子:
# 通过表达式在三个不同列上创建的索引CREATE INDEX people_names ON people ((first_name || ' ' || last_name));复制
部分索引:
部分索引返回的结果中只包含那些符合该谓词的表行的项。
# 创建部分索引CREATE INDEX age_idx ON user(age)WHERE NOT (age> int 18 ANDage < int 60);复制
以上就是PostgreSQL最常用的索引类型,如果您有什么使用上的问题,欢迎私信交流~
参考文献:
[1] 胡运发.数据索引与数据组织模型及其应用:复旦大学出版社,2012-07-01
[2] postgreSQL中文社区.PostgreSQL 11.2 版本在线手册 ...(中文版本)
