




最近在搞Oracle 执行计划相关,主要是想探究一下系统统计信息对于执行计划的影响。
根据以下Mos 文档 -How To Calculate CPU Cost (Doc ID 457228.1),可以看到基于CPU 消耗的成本计算公式为:
Cost = (#SRds * sreadtim +#MRds * mreadtim +#CPUCycles / cpuspeed)/sreadtim复制
以下为各个名词的解释,
single block readtime in ms (SREADTIM )
multiblock readtime in ms (MREADTIM)
average multiblock_read_count in number of blocks (MBRC)
#SRDs - number of single block reads
#MRDs - number of multi block reads
#CPUCycles - number of CPU Cycles
cpuspeed - CPU cycles per second (this is Oracle CPU speed and is not directly comparable to hardware CPU speed)
其实这部分内容还有欠缺,应该是还要加上直接路径读的消耗上去,为了简便,忽略一些细节以及些许差异,不纠结百分百的准确。
以上公式可以转换为:
Cost = (#SRds * sreadtim + #MRds * mreadtim + #CPUCycles/cpuspeed)/sreadtim=IO cost + CPU cost=(#SRds * sreadtim + #MRds * mreadtim)/sreadtim + (#CPUCycles/cpuspeed)/sreadtim=#SRds+#MRds * (mreadtim/sreadtim)+(#CPUCycles/cpuspeed)/sreadtim复制
可以认为分为两部分,一部分是IO 的消耗,一部分是CPU 消耗。
计算全表扫描消耗的时候,可以进一步的去掉#SRds,也就是单块读的计算。
Cost = #MRds * (mreadtim/sreadtim)+(#CPUCycles/cpuspeed)/sreadtim复制
由于CPU消耗其实不大,我们也可以近似的认为,全表扫描的消耗都集中在
#MRds * (mreadtim/sreadtim)
我们知道#MRds 对于一个表来说是固定的(数据块是固定大小),那么mreadtim/sreadtim 的比值就变得很重要。那么这两个值如何计算呢?在以下mos 文档中有提及
<Document 1106073.1> What is the difference between '_db_file_optimizer_read_count' and 'db_file_multiblock_read_count'?
得到以下几个值:
(The NOWORKLOAD case, the following are used in the formula:MBRC = _db_file_optimizer_read_count (if system stat MBRC is not gathered)SREADTIM = IOSEEKTIM + db_block_size/IOTFRSPEEDMREADTIM = IOSEEKTIM + MBRC * db_block_size/IOTFRSPEED))With WORKLOAD stats, then:io_cost = max(1, ceil(blocks/MBRC * MREADTIM/SREADTIM))复制
Relationship to Calculation of Full Table Scan Cost
If MBRC is set, it will be used by the optimizer to calculate the cost of a full table scan.
When MBRC is not set, then _DB_FILE_OPTIMIZER_READ_COUNT will be used instead.
When DB_FILE_MULTIBLOCK_READ_COUNT is 0 or default, then the value of _DB_FILE_OPTIMIZER_READ_COUNT is set to 8.
When DB_FILE_MULTIBLOCK_READ_COUNT is set to any other value, then _DB_FILE_OPTIMIZER_READ_COUNT will derive its value from there.
那么我们可以得到在NOWORKLOAD 的情况下,
MBRC=_db_file_optimizer_read_count = 8
SREADTIM = IOSEEKTIM + db_block_size/IOTFRSPEED
MREADTIM = IOSEEKTIM + MBRC * db_block_size/IOTFRSPEED
那么决定SREADTIM和MREADTIM 比值的关键因素和变量应该是IOTFRSPEED(默认值为4096,以NOWORKLOAD模式收集系统统计信息的时候,会改变这个值)。根据计算方法,可以容易的看到,SREADTIM和MREADTIM 的极小值为IOSEEKTIM,同时在IOTFRSPEED增大的情况下,MREADTIM 和SREADTIM 的比值会不断的接近。
下面简单的模拟一下:
declareIOSEEKTIM number :=10;--_db_file_optimizer_read_countdb_file_optimizer_read_count number :=8;db_block_size number:=8192;IOTFRSPEED number:=4096;MBRC number:=8;begindbms_output.put_line('SREADTIM is :'||to_char(IOSEEKTIM+(8192/IOTFRSPEED)));dbms_output.put_line('MREADTIM is :'||to_char(IOSEEKTIM+(MBRC*8192/IOTFRSPEED)));end;/

可以看到在IO 能力很强的机器上收集noworkload 的系统统计信息,会导致系统认为多块读和一次单块读的时间差不多。回到全表扫描的IO消耗计算公式。
#MRds * (mreadtim/sreadtim)
在MREADTIM 和SREADTIM 近乎相等的情况下,全表扫描的消耗相当于多块读的次数。而在默认的IOTFRSPEED=4096的情况下,全表扫描的消耗=#MRds*(26/12) 也就是多一倍的预估成本消耗。
以下计算公式可以较为接近(因为忽略了一些变量和计算比较的消耗)的计算全表扫描的cost
for full table scan costCOST= IO-cost + CPU-cost/( SREADTIM*CPUSPEED*1000)=IO-cost + (4500 + 0.32*blocksize) * NBLOCKS+NUM_ROWS*130+nrows*20)/(SREADTIM*CPUSPEED*1000)=IO-cost + (4500 + 0.32*blocksize) * NBLOCKS+NUM_ROWS*130+nrows*20)+(cpu filter eval=50*num_rows)/(SREADTIM*CPUSPEED*1000)=NBLOCKS * MREADTIM/(SREADTIM * MBRC) + (4500 + 0.32*blocksize) * NBLOCKS+NUM_ROWS*130+nrows*20)+/(SREADTIM*CPUSPEED*1000)复制
此处就简单的直接用auto trace 贴一下。
默认情况下:
SQL> select PNAME,PVAL1 from AUX_STATS$ where sname='SYSSTATS_MAIN';PNAME PVAL1------------------------------ ----------CPUSPEEDNW 1391IOSEEKTIM 10IOTFRSPEED 4096SREADTIMMREADTIMCPUSPEEDMBRCMAXTHRSLAVETHR9 rows selected.
对T1 表收集统计信息:
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>'IVAN',TABNAME=>'T1',METHOD_OPT=>'FOR ALL COLUMNS SIZE 1',NO_INVALIDATE => FALSE,DEGREE=>8,CASCADE=>TRUE);SQL> select /*+ full(t1) */* from t1 where id<1800000;Execution Plan----------------------------------------------------------Plan hash value: 3617692013--------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |--------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1000K| 27M| 1293 (2)| 00:00:01 ||* 1 | TABLE ACCESS FULL| T1 | 1000K| 27M| 1293 (2)| 00:00:01 |--------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter("ID"<1800000)复制
可以看到此时的cost 为1293.
计算得到:

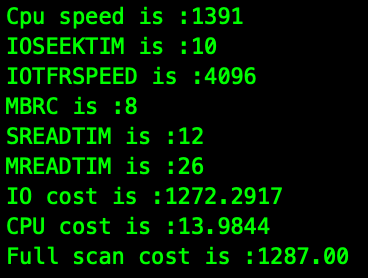
修改IOTFRSPEED 为 默认值的10倍.
exec dbms_stats.set_system_stats('IOTFRSPEED',4096*10);Execution Plan----------------------------------------------------------Plan hash value: 3617692013--------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |--------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1000K| 27M| 693 (4)| 00:00:01 ||* 1 | TABLE ACCESS FULL| T1 | 1000K| 27M| 693 (4)| 00:00:01 |--------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter("ID"<1800000)复制
计算得出:

可以看到cost 消耗降低了接近一半。
这样的变化,对于一个OLTP系统,应该是很不合适的,对于一些索引成本消耗大一点的执行计划,可能都会改变执行计划,选择到全表扫描。
总结而言:通过对全表扫描的计算方法的了解,可以在以后修改某些系统参数的时候,更加有把握,照顾其他方面的影响。其次收集系统统计信息,应该慎重!
评论

 1 1
1 1 0 点赞
0 点赞 1 1
1 1