




实时数据湖业务场景

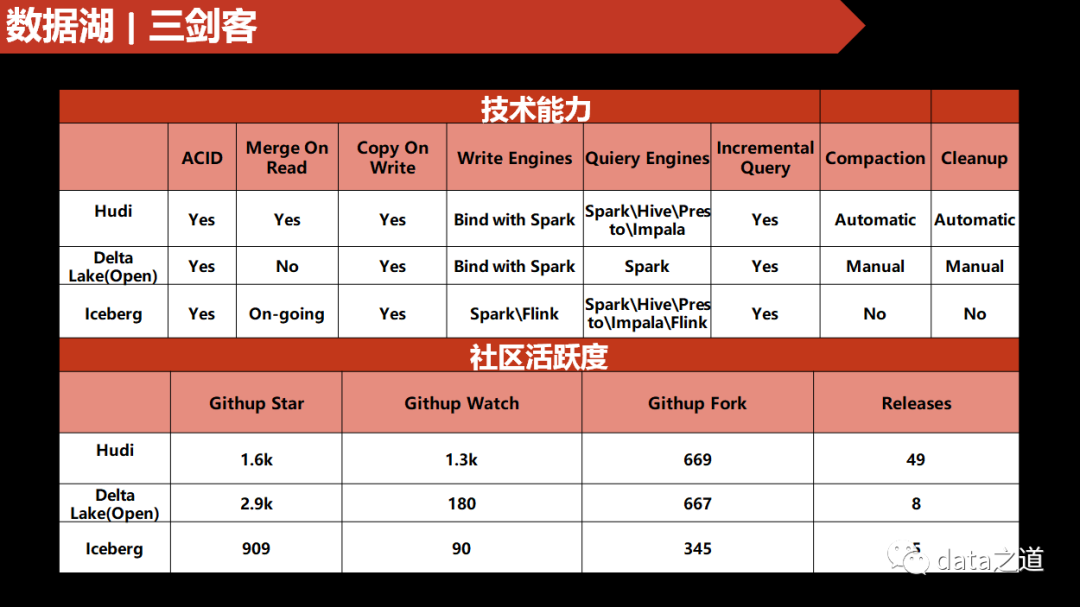
实时数据湖解决方案对比
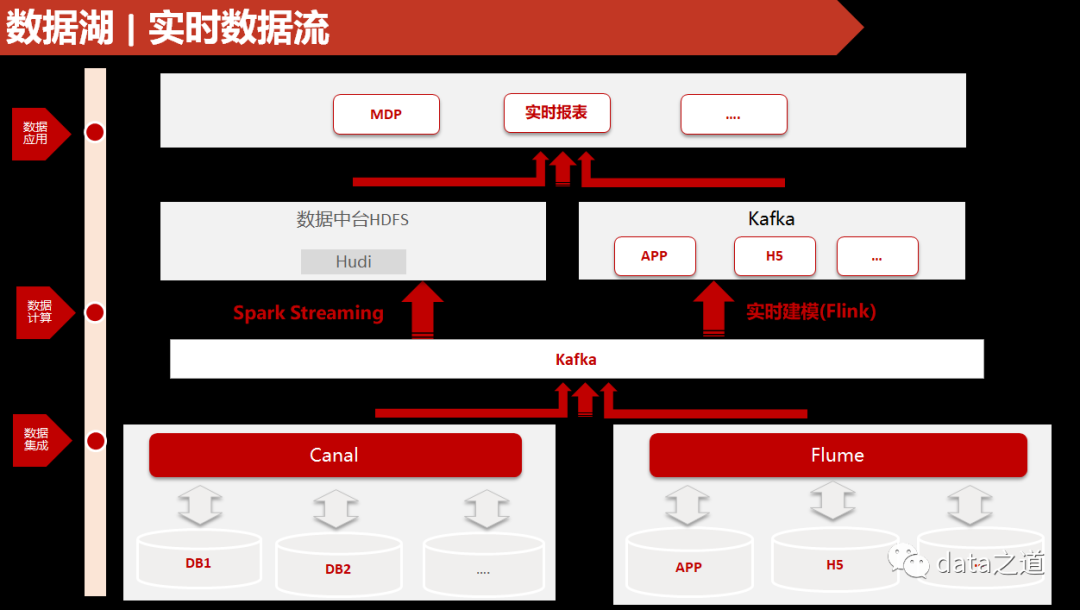
实时数据流管道
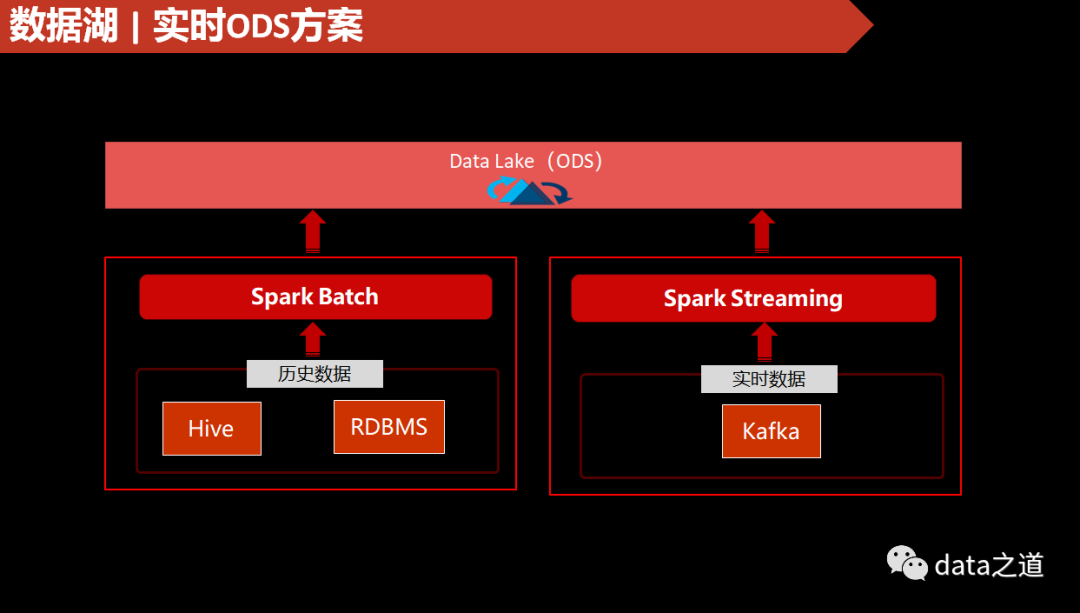
DFS上实时数据流解决方案
Hudi表存储类型对比
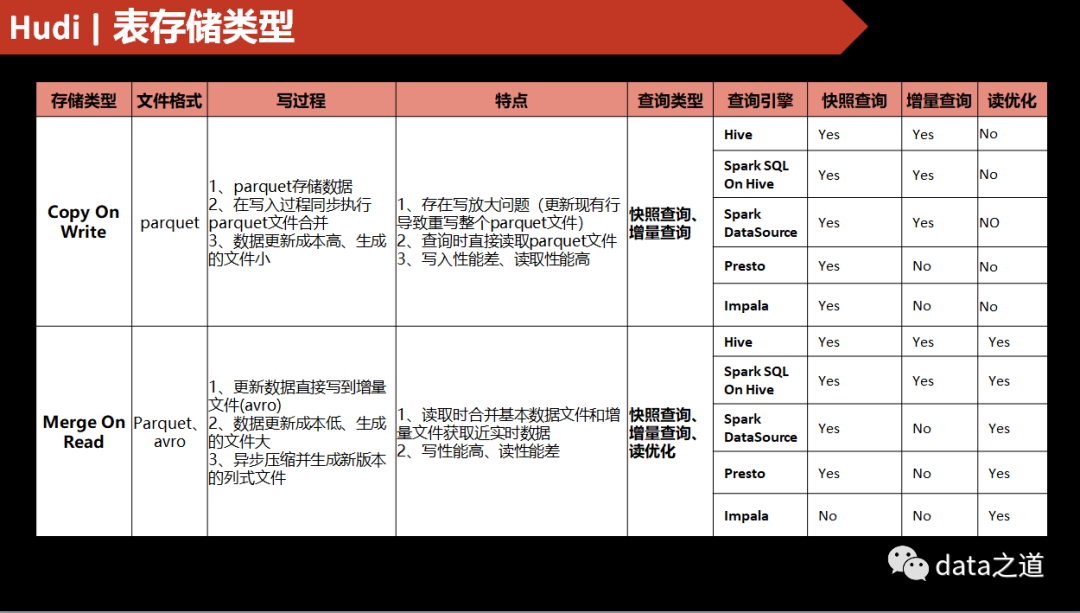
一旦首次数据写入时确定了Hudi存储格式,不能再修改。COW存储格式不需要压缩:
ERROR HoodieCompactor: org.apache.hudi.HoodieNotSupportedException: Compaction is not supported on a CopyOnWrite table
Hudi操作类型使用场景

并发:
hoodie.bulkinsert.shuffle.parallelism
hoodie.insert.shuffle.parallelism
hoodie.upsert.shuffle.parallelism
hoodie.delete.shuffle.parallelism
设置并发的数量,spark会用coalesce或reduceByKey对RDD进行重新分区,分区数就是并发数。
在bulk_insert里有个设置排序的参数,默认是全局排序,即对读取到的所有数据根据排序字段进行排序,全局排序是用rdd.sortBy实现的:
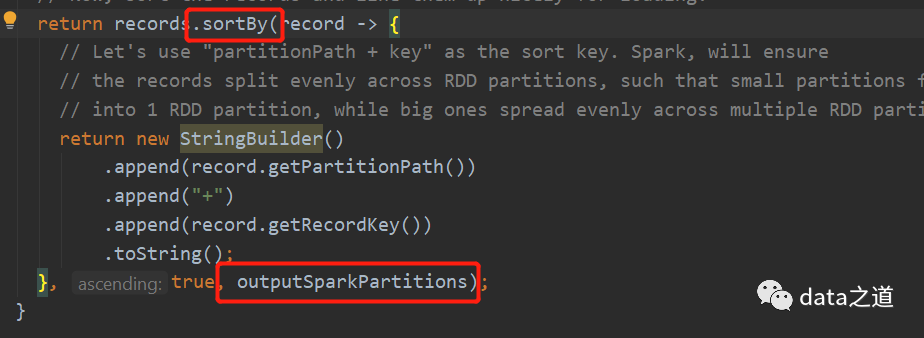
如果时分区排序,就先用coalesce(outputSparkPartitions)重分区,然后在mapPartition转换内对每个分区内的数据排序:
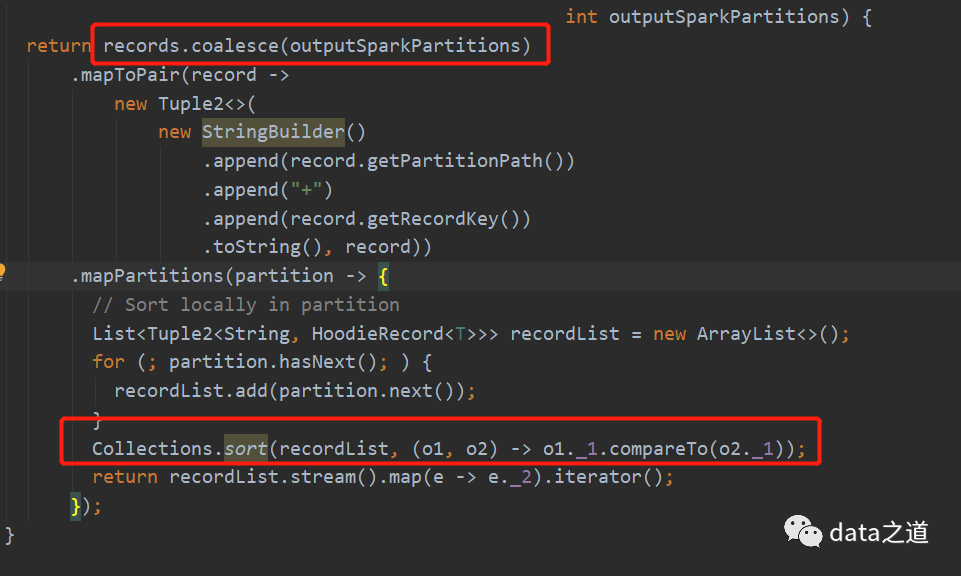
很明显第二种方式效率会更好高。
Hudi查询类型

代码--批量同步Hive表到Hudi
import spark.sqlval df = sql(sparkSql)val originCount = sql(s"select count(1) from ${cliConfig.sourceTableName}").take(1)(0)LOG.info(s"Origin Count:$originCount")val writerClientOpts = initWriterClientOpts(cliConfig)val dfWriter = df.write.format("hudi") // 指定Spark写入类型.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,cliConfig.tableType).option(DataSourceWriteOptions.OPERATION_OPT_KEY,cliConfig.operation).option(HoodieWriteConfig.TABLE_NAME, cliConfig.targetTableName).option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, cliConfig.recordkeyField) // 主键.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, cliConfig.precombineField) // 记录更新时间:Hudi表Merge时的依据.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, cliConfig.partitionField).option(DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY,true).options(writerClientOpts)val sparkSaveMode=if(cliConfig.operation.equals(DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL)) {SaveMode.Overwrite}else {SaveMode.Append}dfWriter.mode(sparkSaveMode).save(cliConfig.targetBasePath)spark.stop()
参数说明:
hoodie.datasource.write.partitionpath.field:在分区表的情况下,起作用;指定分区表的partition字段,如果没有配置,那partition默认字段"partitionpath";如果分区字段在查询的表里不存在,那分区的默认值是"default"。也就说,hudi表是分区表,默认分区字段partitionpath,并且只有一个“default”分区
hoodie.table.name:指定hudi 表名,hudi表名在hudi元数据文件里存储
如果目标路径已经存在,Hudi会认为表元数据已经有了,否则会报org.apache.hudi.exception.TableNotFoundException: Hoodie table not found in path
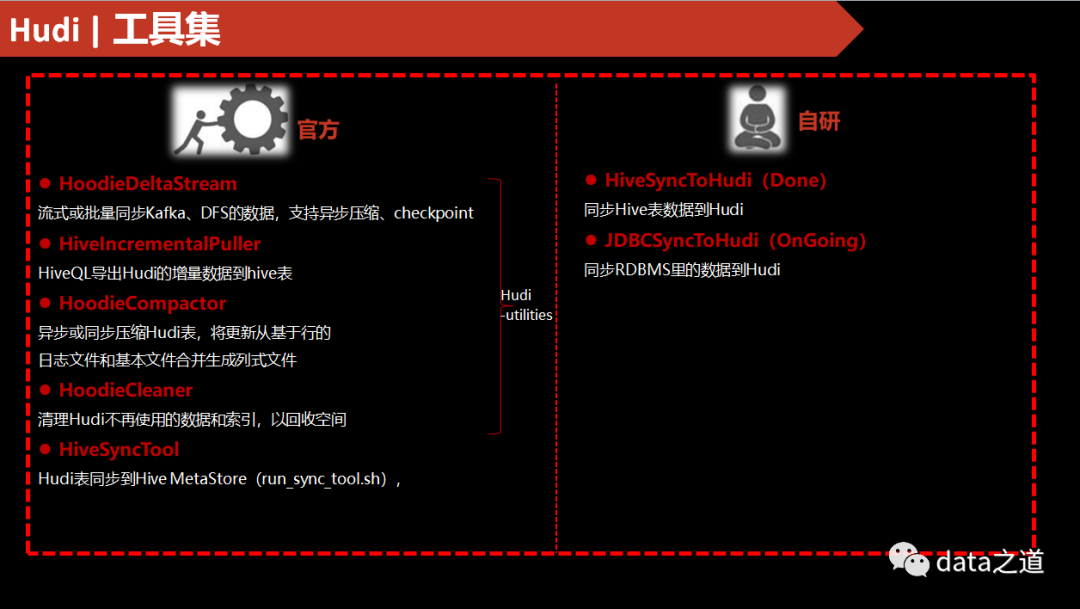
脚本--实时同步Kafka到Hudi表
用HoodieDeltaStreamer 工具,可以实时同步Kafka数据到Hudi表:
spark-submit --master yarn \--deploy-mode client \--queue root.kp.swift \--name DeltaStreamer_ods \--driver-memory 2G \--executor-cores 2 \--num-executors 4 \--executor-memory 4G \--jars /opt/hudi/libs/hudi-spark-bundle_2.11-0.6.0.jar,/opt/hudi/libs/spark-avro_2.11-2.4.4.jar \--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /opt/hudi/tools/hudi-utilities-bundle_2.11-0.6.0.jar \--continuous \--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \--hoodie-conf hoodie.deltastreamer.schemaprovider.source.schema.file=hdfs:///apps/hive/warehouse/ods.db/ods_product/kafka-schema.avro \--hoodie-conf hoodie.deltastreamer.schemaprovider.target.schema.file=hdfs:///apps/hive/warehouse/ods.db/ods_product/kafka-schema.avro \--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \--props hdfs:///apps/hive/warehouse/ods.db/ods_product/kafka-source.properties \--target-base-path /apps/hive/warehouse/ods.db/ods_product/ \--op UPSERT \--commit-on-errors \--table-type COPY_ON_WRITE \--target-table ods.ods_product\--transformer-class org.apache.hudi.utilities.transform.SqlQueryBasedTransformer \--source-ordering-field last_updated_stamp \--checkpoint ods_product,0:15523,1:15562,2:15815,3:15601
参数说明:
checkpoint可以指定初始化消费Kafka的offset。当首次用HoodieDeltaStreamer写Hudi表,此时Hudi表元数据中还没有checkpoint信息,如果没有指定checkpoint参数,会使用auto.offset.reset的配置项,默认LATEST,即从最新的offset开始消费;如果配置了checkpoint,不管hudi表有没有checkpoint信息,都根据参数指定的checkpoint开始消费。
target-table指定的是在hudi元数据中的hudi表名称
schemaprovider-clas指定schema解析器
source/target.schema.file,如果用的文件schema解析,该参数指定avro格式的schema配置文件
source-ordering-field排序列,用于merge数据
transformer-class 数据转换类,定义一个spark sql,加工源表数据
props:指定一个配置文件,配置参数统一放到这个文件里配置;props配置文件里的参数,会被--hoodie-conf指定的参数替换,如果不指定,可能会报默认加载的配置文件找不到得异常
HoodieDeltaStreamer有checkpoint功能,会把当前消费的Kafka偏移量放到Hudi Table元数据(deltastreamer.checkpoint.key)。
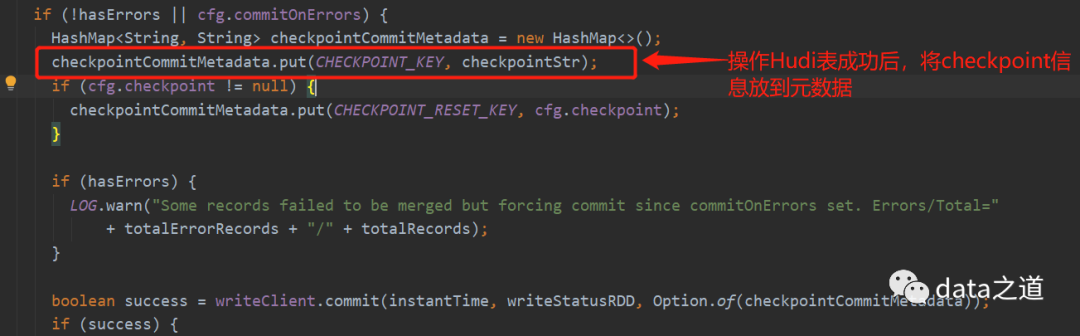

提交的spark应用名规则:delta-streamer-$targetTableName
kafka-source.properties配置文件样例:
hoodie.upsert.shuffle.parallelism=2hoodie.insert.shuffle.parallelism=2hoodie.bulkinsert.shuffle.parallelism=2hoodie.datasource.write.recordkey.field=product_idhoodie.datasource.write.partitionpath.field=""hoodie.deltastreamer.source.kafka.topic=product_pricebootstrap.servers=ip1:9092,ip2:9092auto.offset.reset=earliestgroup.id=hudi_ods
代码--增量查询
val beginInstantTime = "20201213200000"spark.read.format("hudi").option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL).option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, beginInstantTime).load(s"$hudiTablePath").createOrReplaceTempView(hudiTableName)spark.sql(s"select count(1) from ${hudiTableName} limit 10").show()
上面代码用的SparkDataSource的方法,这种方法不支持对Merge On Read表的增量查询;可以把Hudi表同步到Hive,然后用Spark SQL查hive里的数据,Spark Sql支持Copy On Write和Merge On Read的增量查询;
BEGIN_INSTANTTIME_OPT_KEY指定增量查询时间。
「在一起看」👇
