(一)获取数据
1、创建数据库表
正如前文所述,数据分析的工具多种多样,并且每种工具内部保存数据的结构也不一样。比如Excel就是表格、Python里比较常见的有Pandas的DataFrame,或者Numpy的数组等。在SQL的世界里,所有的数据都是以数据库表的形式保存,所以我们要先创建一张数据库的表,用来保存鸢尾花的数据。SQL里创建数据库表,需要用到CREATE TABLE这个命令(语法规则可参考下图中的链接)。PolarDB for PG数据库因为是基于开源的PG数据库,对SQL标准的支持还是比较好的。

如上图所示,创建一张叫flowers的表,包含5个字段,前4个字段的类型是float8,就是double类型的浮点数,分别是花萼与花瓣的长度与宽度;最后一个字段类型是text,就是任意长度的字符串,用来保存花的品种。
上图中右侧的代码是给数据库表和字段添加注释,用来说明表和字段的用途。给数据库的表和字段添加注释是一个非常好的习惯,可以帮助理解数据,以及每个字段的含义。推荐大家在创建数据库表或新增字段时,及时地给表或字段加上注释。
2、导入数据到数据库表
创建了表之后,如何将数据导进来呢?在数据量小的时候,可以通过手工逐行insert数据,但是如果数据量大,手工insert就几乎不可能。比如鸢尾花的数据一共有150行,手工 insert 150次是一件很费劲的事情。好在 PolarDB 提供了一个COPY的命令,可以批量地导入或者批量导出数据。如下图所示:
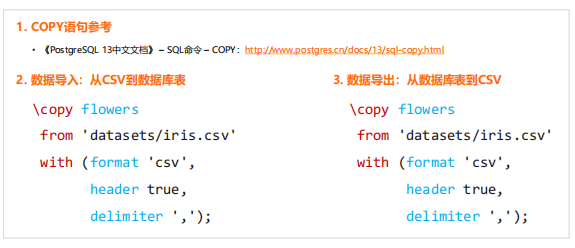
其中左边的代码是从CSV文件里导入数据到flowers表中;右边的代码是把flowers表的数据导出到test.csv这个文件里。with子句指定数据的格式信息,比如上图中指定格式是CSV格式、包含表头、分隔符是逗号。
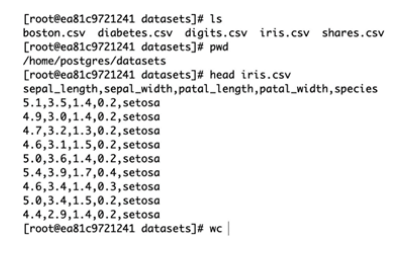
安装完插件后,在Docker容器内/home/postgres/datasets目录下,已经预置了一些CSV文件,其中iris.csv就是本案例中用到的鸢尾花数据,如下图所示:
接着,这个数据导入到PolarDB里面来。先通过PSQL连接到PolarDB数据库,当前数据库是空的,里面没有任何一张表,所以通过建表语句,先创建一张数据库表。如下图所示:
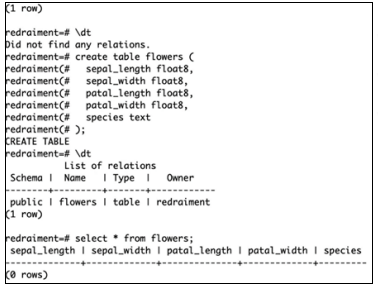
然后再添加注释,通过\d+ flowers可以看到数据库表的定义。如下图所示:

最后,通过COPY命令把CSV的数据导进来:其中格式是CSV格式、header为true(即包含了标题),以及分隔符是逗号。如下图所示:
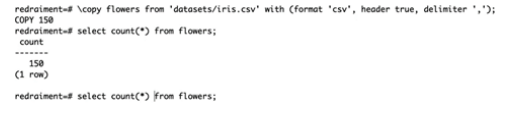
提示导进来了150行数据,通过select * from flowers可查看数据:

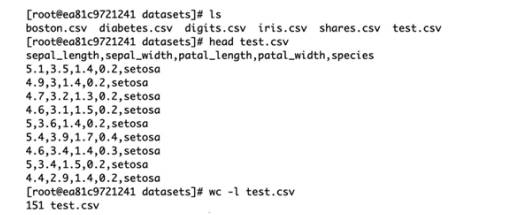
再试试把表中的数据导出到一个新的文件里面。如下图所示:

导出成功后,切换到Shell里,可以看到datasets目录里多出了一个叫test.csv的文件,并且有151行内容(包含标题)。