




相信朋友们在学习MySQL的时候,会听到很多设计的术语。今天就简单的介绍一下回表查询、索引覆盖、索引下推以及最左匹配。
回表查询
这先要从InnoDB的索引实现说起,InnoDB有两大类索引:
聚集索引(clustered index)
普通索引(secondary index)
InnoDB聚集索引和普通索引有什么差异?
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
画外音:所以PK查询非常快,直接定位行记录。
InnoDB普通索引的叶子节点存储主键值。
画外音:注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
通常情况下,需要扫码两遍索引树
。

如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
索引覆盖
借用一下SQL-Server官网的说法。

不管是SQL-Server官网,还是MySQL官网,都表达了:只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
总的来说,没有进行回表查询的的操作就是
索引覆盖
。
如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
索引下推
对于user_table表,我们现在有(username,age)联合索引 如果现在有一个需求,查出名称中以“张”开头且年龄小于等于10的用户信息,语句C如下:"select * from user_table where username like '张%' and age > 10". 语句C有两种执行可能:
1、根据(username,age)联合索引查询所有满足名称以“张”开头的索引,然后回表查询出相应的全行数据,然后再筛选出满足年龄小于等于10的用户数据。过程如下图。

2、根据(username,age)联合索引查询所有满足名称以“张”开头的索引,然后直接再筛选出年龄小于等于10的索引,之后再回表查询全行数据。过程如下图。
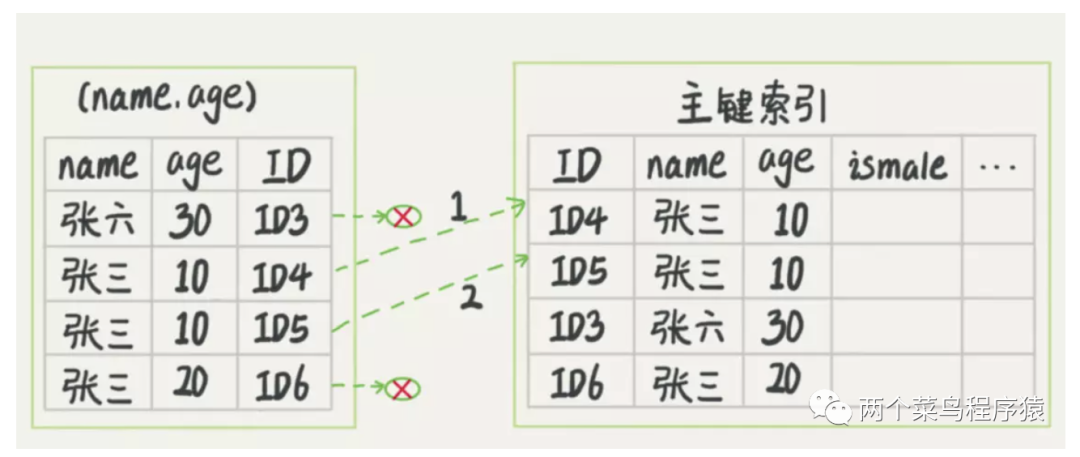
明显的,第二种方式需要回表查询的全行数据比较少,这就是mysql的索引下推
。mysql默认启用索引下推,我们也可以通过修改系统变量optimizer_switch的index_condition_pushdown标志来控制:
复制
注意点:
1、innodb引擎的表,索引下推只能用于二级索引。
就像之前提到的,innodb的主键索引树叶子结点上保存的是全行数据,所以这个时候索引下推并不会起到减少查询全行数据的效果。
2、索引下推一般可用于所求查询字段(select列)不是/不全是联合索引的字段,查询条件为多条件查询且查询条件子句(where/order by)字段全是联合索引。
假设表t有联合索引(a,b),下面语句可以使用索引下推提高效率select * from t where a > 2 and b > 10;
最左匹配
最左匹配原则属于联合索引的知识,当我们使用!=、like、> 或者其他的情况,会导致联合索引不可用的情况。
