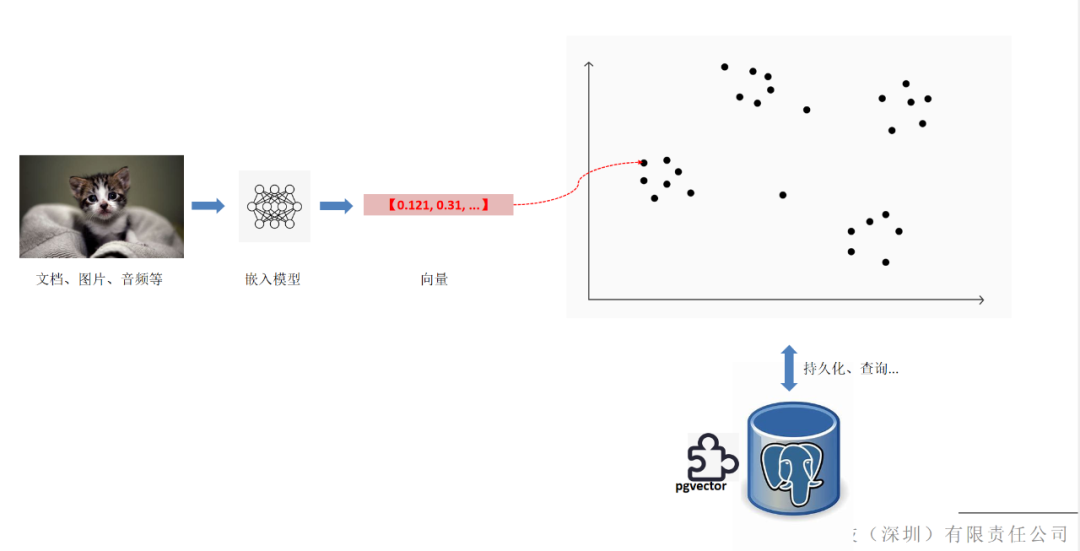
随着ChatGPT等大型语言模型(LLM)的逐渐普及,向量数据库作为增强ChatGPT知识库的利器也被推到应用前线,进入到大家的视野。而pgvector作为PostgreSQL的插件,提供了向量存储和查询的功能,使得PostgreSQL也一跃成为强大的向量数据库。本文我们将介绍pgvector的用法和其背后的实现原理,期望大家能够对向量化数据库有一个直观的了解。本文金句:pgvector作为PostgreSQL的插件,提供了向量存储和查询的功能,使得PostgreSQL也一跃成为强大的向量数据库。在介绍这个插件之前,我们先介绍⼀个数学概念,即embedding,中⽂翻译叫做“嵌⼊”。它是⼀种数据处理的⼿段,通常⽤于将复杂的数据结构,如⽂本、图⽚、⾳频等,映射成低维度的向量(下文称之为“嵌入向量”),嵌入向量每⼀个维度都对应着原某一隐含的特征,因此这一映射关系就像是将原始复杂数据结构的特征“嵌入”到了这个向量中一样。而嵌入向量的这种特征,使得我们可以通过计算向量之间的距离(例如l2距离、cosine距离等)就能衡量复杂数据结构之间的相似程度了。pgvector使得PG能够持久化这些嵌⼊向量,并提供了用于加速“相似度向量查找”的索引。所谓相似向量查找,是指从一堆已经持久化的嵌入向量中找到与给定向量距离最近的Top N个向量。这个功能在很多业务场景中有用到,例如推荐、人脸识别、大语言模型等等,因此pgvector提供的加速功能是非常有现实意义。在详细介绍pgvector的工作原理之前,我们先举两个使用pgvector的例子,让大家对pgvector有一个感性的认识。第⼀个例子是pgvector和chatgpt联合使⽤,构建⼀个公司的智能客服机器人。我们知道chatpgt是⼀个通⽤的模型,它已经接受了百万篇⽂档的训练,能够理解⼈类的语⾔,并能基于训练时接受到的信息回答⼈们的问题。但是,它的知识库并不是实时更新的, 如果你问最新资讯信息,或者某个它尚未接触过的产品的问题,那么它可能会得出⼀个错误的答案。鉴于chatgpt优秀的语⾔理解能⼒,⼀个可行的⽅案是,我们将相关的资料或⽂档作为与chatgpt聊天的上下⽂,让它基于给定资料或者⽂档回答用户问题,这样就能够让chatgpt瞬间成为相关产品的“专家”了。但这个方案需要解决两个问题,首先是 chatgpt上下⽂的⼤⼩限制,如果资料或者文档的大小超过了这个限制,chatgpt就可能会因为缺少相关信息而无法正确回答;第二个问题是chatgpt是基于token数量收费的,如果每个问题都向它提供全量文档是非常不经济的。因此根据⽤户的提问,有选择性地挑选相关⽂档作为与chatgpt交互的上下⽂是⾮常有必要的。下面的流程图便是完整的解决方案:1.⾸先需要根据主题将产品⽂档拆分一系列的子文档;2.使用chatgpt的文本嵌入模型对每个⼦⽂档进⾏嵌⼊,得到相应的嵌⼊向量;3.将各个⼦⽂档及其对应的嵌⼊向量都持久化到装载了pgvector插件的pg数据库中;1.使用chatgpt的文本嵌入模型对用户的提问进行嵌入,得到提问的嵌入向量;2.使用提问的嵌入向量去pg数据库中进行相似向量查找,得到嵌入向量与之距离最近的子文档;3.将子文档、用户的提问,以及额外的角色引导信息构成prompt提交给chatgpt;经过以上步骤我们就能实现一个经济可行的智能客服机器人啦!在这个例子中加载了pgvector插件的pg负责持久化拆分之后的子文档及其嵌入向量,并提供快速的相似向量查找功能,为chatgpt提供最需要的上下文。第二个例子是一个非常有意思的小应用,且提供了代码供读者自行实验。https://github.com/zettadb/techtalk/blob/main/pgvector%E7%9A%84%E5%BA%94%E7%94%A8%E5%92%8C%E5%8E%9F%E7%90%86/clip.ipynb这个例⼦⽤到了OpenAI于2021年推出的⼀个深度学习模型Clip。Clip模型有⼀个⾮常有意思的特性,即它能够对图⽚和⽂本分别进⾏嵌⼊,且得到的嵌入向量位于同⼀个嵌⼊空间,也就是说如果⽂本描述信息和图⽚相关,那么它们的嵌入向量的也是相近的。在这个例⼦⾥⾯,我们里面clip模型实现了这样一个应用,即给出一句话,从监控视频中得到与这句话最相关的监控画面。下面是这个应用的结构图:这个应用会对⼀个监控视频进⾏帧采样,得到⼀系列的监控画面,接着对这些监控画面使用CLIP提供的图像编码器进⾏嵌⼊,得到相应的嵌⼊向量,然后我们将这些画面(或者帧编号)与嵌⼊向量持久画到PG中。当⽤户想要从这个监控视频中查找什么时,⽐如想要找⼀个⾛丢的⼩孩,可以将⼩孩的特征⽤⽂字的形式表达出来,应用使用CLIP模型提供的文本编码器对⽂字进⾏嵌⼊,得到⽂字的嵌⼊向量,⽤其去数据库做相似向量查找,就能得到想要最符合描述的图⽚了。可以看到,这个应用的逻辑和前面智能客服机器人的逻辑是很相似的,这也说明了相似向量查找是一个应用场景非常广泛的功能。接下来我们着重标记出这个项目是如何使用pgvector插件提供的功能的。
首先是代码中创建的表vedio_features,它是项目用于持久化监控画面(实际使用时可只记录监控画面的帧编号)及其嵌入向量的,其中feature字段便是用于存储嵌入向量的,它是一个维度为1024的vector类型,vector类型便是pgvector插件引入到pg数据库的新类型。cur.execute(
"""CREATE TABLE IF NOT EXISTS vedio_features(
id
bigserial primary key,
image
bytea,
feature vector(1024));"""
)
复制
如下代码所示,应用在vedio_features表的feature列上创建的用来加速相似向量查找的索引。这个索引的类型是ivfflat,是pgvector插件引入到pg数据库当中的新的索引类型之一。索引使用的method是vector_cosine_ops,表示使用cosine距离来衡量向量之间的距离。lists是什么呢?这里留一个悬念,后面在讲解pgvector原理时我们再详细讲述。cur.execute(
"""CREATE INDEX ON vedio_features
USING ivfflat (feature vector_cosine_ops) WITH (lists =
100);"""
)
复制
下面则是使用文本的嵌入向量去pg数据库进行相似向量查找的代码。其中操作符<=>是pgvector插件引入的操作符之一,用来计算两个向量之间的cosine距离。因此代码中的sql表示的意思是按照与给定的文本嵌入向量的cosine距离对监控画面的嵌入向量进行排序,从而获取与文本描述最贴近的前5个对应监控画面。在没有索引加持的情况下,这条sql需要遍历所有嵌入向量,当数据量特别大的情况下,性能是非常堪忧的。而有了前面创建的ivfflat索引的帮助,数据库就能够快速响应用户的查询请求了。cur.execute(
"""SELECT image FROM vedio_features
ORDER
BY feature <=> %s::vector limit 5;""",
(np.array(search_feat.detach()).tolist(),),
)
复制
事务调度算法解决的问题就是当多个事务正在等待对同一个对象的锁时,哪一个应首先获得锁。其中有两种算法,FCFS和CATS, MySQL8.0版本之前,InnoDB一直采用的是FCFS算法,之后则开始采用CATS算法。
通过前⾯的两个例子,相信读者对pgvector已经有了直观的了解,总的来说,pgvector插件提供了三个最主要的功能:接下来的篇幅我们将继续介绍pgvector是如何实现这些功能的,让大家对pg数据库的扩展性有一个更深的体会。
3.1 类型
作为⼀个⾼度可扩展的数据库,PG数据库是允许⽤户⾃定义数据类型、操作符、函数、索引,甚⾄优化器和执⾏器等。对于自定义数据类型,如果能够简单组合已有的类型来得到想要的新类型,通过PG给的create type语法只需一步就能创建出来。而对于复杂的数据类型,例如pgvector引入的vector类型,也只需简单的几个步骤就能创建出来,具体如下:1、⾸先需要定义vector的内存结构、文本和二进制表示形式。先说内存结构,如果是定长结构体,可随心所欲地定义,只要成员变量不是指针即可;对于向vector这类变长的的结构体,则需要遵循PG默认的变长数据类型的内存布局规范,只有这样才能和PG已有处理变长数据类型的机制兼容。具体来说,就是结构体的第⼀个字段需要是⼀个一字节或四个字节的头部,⽤来编码结构体的长度、是否压缩等信息,因此vector的第⼀个字段是⼀个int32的类型,⽽其他字段才是vector独有的数据。PG自带了很多用于处理变长数据类型的宏(例如设置长度,获取长度等),这里就不再具体介绍了。typedef struct Vector {
int32 vl_len_; /* varlena header (do not touch directly!) */
int16 dim; /* number of dimensions */
int16 unused;
float x[FLEXIBLE_ARRAY_MEMBER];
} Vector;
复制
应用程序往往是通过文本形式的sql进行或者安全的二进制协议(即prepare/execute)与数据库打交道的,因此任何数据类型也需要有与之对应的文本和二进制表示形式。vector的文本形式是方括号括住一串浮点数,例如“[0.1221, 1.312,
-3.31]”;二进制格式则是一个byte序列,依次存放了vector结构体的dim、unused、x字段二进制数据。2、定义vector内存结构体与⽂本或者⼆进制形式进⾏转换的函数。3、定义用来解析类型修饰器(type
modifier,简称typmod)的函数。PG允许为类型定义其修饰器,为进一步定义类型提供额外的信息,例如vector(12)中的12便是类型修饰器,用来确定vector的维度信息。PG并没有限定修饰器的长度,只是约定必须能编码成一个int存放到系统表中,因此需要开发者定义对应的函数来解析类型修饰器并编码成一个int数值。4、通过create
type正式定义vector类型。create type语句中不仅指定了新类型的名称,还指定了步骤2中定义各种转换函数,pg数据库正是根据这些转换函数来创建和表示vector数据类型的。当然还要一些其他的信息,具体看下面的注释。CREATE TYPE vector (
INPUT = vector_in, # 文本形式转成vector
OUTPUT = vector_out, # vector转成文本形式
RECEIVE = vector_recv, # 二进制形式转成vector
SEND = vector_send, # vector转成二进制形式
TYPMOD_IN = vector_typmod_in, # 解析类型修饰符,即vector(12)中的12
STORAGE = extended # 表示当长度较短是可存在主表,否则存储到外表
);
复制
经过前面几个步骤已经成功创建了vector类型,但仍然存在一个问题,即PG并不了解类型及其维度的真正含义,当用户插入一个维度不符合列定义的数据时,PG只是机械地调用步骤4注册的函数创建了一个内存中的结构体,并直接将其持久化到表文件中,并不会检查维度信息是否正确。此时,如下所示的sql在执行时并不会报错:CREATE TABLE t (a vector(2));
INSERT INTO t VALUES ('[0.12, -0.213, 0.782]');
复制
为了解决这个问题,还需要定义vector自己到自己的类型转换函数。这是因为PG在接收到其类型有修饰器的数据时,它并不确定数据是否符合类型修饰器的限制,此时它会尝试查找并调用类型自己到自己的转换函数,并传入目标类型的修饰器,用来检查或者调整数据,使其满足修饰器表达的含义。因此pgvector还定义了vector类型的转换函数,想要了解更多关于create
cast的信息可以参考pg官网:CREATE CAST (vector AS vector)
WITH FUNCTION vector(vector, integer, boolean) AS IMPLICIT;
复制
3.2 操作符
为了能对vector类型的数据进行更加丰富的操作,而不是简单的读写,还需要定义与vector类型相关的函数或操作符。在PG数据库中中自定义函数或操作符是非常简单的,通过create function/operator语法就能创建新的函数或者操作符,相关资料可以参考pg官网,这里就不再赘述了。
pgvector为vector类型定义了⼀系列的函数和操作符,其中3个函数和操作符是和向量距离相关的: | | |
| L2
Euclidean(两个向量相减得到的新向量的长度) | | |
| Negative
Inner product(两个向量内积的负值) | | vector_negative_inner_product |
| | |
定义了这些操作符和函数之后,我们就能够通过sql来进行相似向量查找了,例如:-- 使用操作符
SELECT * FROM vedio_features ORDER BYfeature <=> '[0.212, 0.312, 0.312]' LIMIT 5;
-- 使用函数
SELECT * FROM vedio_features ORDER BYcosine_distance(feature, '[0.212, 0.312, 0.312]') LIMIT 5;
复制
3.3 索引
在执行前面上一小节的sql进行相似向量查找时,需要遍历所有的数据,如果数据量很⼤,性能就会成为⼀个很⼤的问题。如何提升sql执行的性能呢?由于嵌⼊向量的维度⼀般都比较⼤,很难实现准确且⾼效的相似向量查找算法,因此目前业界常用的搜索算法都是“近似”的实现,在准确性和速度之间进行取舍。pgvector目前实现了两个相似向量的近似搜索算法,分别是ivfflat算法和hnsw算法,而与之对应的索引则分别称为ivfflat索引和hnsw索引。接下来的篇幅我们将着重讲解其中的ivfflat算法的实现。3.4 ivfflat算法
- 先对数据集随机采用n*50个样本,n为聚类的数量;
- 根据与每个聚类质心的距离,将整个数据集分割成n个大的聚类;
- 进⾏相似向量查找时,先计算输入向量与每个聚类的质⼼的距离,然后只在距离最近的聚类内进⾏查找。
这样一来就不需要扫描全部数据,大大提升了搜索的性能。那么聚类的数量是怎么确定的呢?这是通过创建索引时,索引的lists属性来决定的。例如如下所示的sql,通过"with (lists=100)"指定了100个聚类:CREATE INDEX ON <table name> USING ivfflat (<column name> <index method>) WITH (lists = 100);
复制
需要注意的是,使⽤较⾼的lists值,虽然能⼤⼤降低搜索空间,提升查询速度,但也会因为排除了某些向量⽽导致召回率的下降;同时与质⼼的⽐较开销也会成⽐例增加。当你还在为确定lists值而犹豫不决时,这里推荐一个方法:当数据量小于一百万的时候,则保证每个聚类中包含1000个向量;当数据量超过一百万时,则lists值设置为数据量的平方根。为什么说ivfflat是一个近似的相似向量搜索算法呢?如下图所示,当我们给定红色点表示的向量进行相似向量搜索时,按理说最佳的相似向量应该是位于淡绿⾊区域且位于边界附近的向量,但是由于红色的点位于淡紫色区域内,只能从该区域内搜索距离最近的向量,导致错过了最佳相似向量。为了缓解该问题,ivfflat算法还有⼀个运⾏时参数probes,是用来控制搜索的聚类数量的。例如使用如下语句将probes设置为2时,就会查找距离输入向量最近的前两个聚类。3.5 ivfflat索引的物理结构
了解完ivfflat算法的原理之后,我们再来看看ivfflat索引的物理结构是如何组织的。如下图所示,ivfflat索引共分为两层,每一层都是有若干个物理页面构成的单向“链表”,其中第⼀层存储的是每⼀个聚类的质⼼向量,且每个质心都拥有一个指向第二层“指针”,而第⼆层存储的则是每个聚类内部的所有向量。
3.6 ivfflat的注意事项
- 对空表建立索引时,则会随机创建聚类的质心。由于随机指定的质心会影响搜索的准确性,建议数据灌入完之后再创建ivfflat索引。
- 聚类的质心一旦确定,即便后续数据发生翻天覆地的变化,都不会改变。如果数据的分布发生了改变,建议使用reindex命令重新创建索引。
- ivfflat索引只能用于优化排序。在PG数据库中索引可以分为search和order两种类别,例如我们常见的btree索引就是属于search类别的,可以用来快速查找符合某些过滤条件的元组;而ivfflat则属于order类别,专门用来对格式为”常量 OP 索引列”的表达式进行排序的,其中OP即前面提到过的3种计算向量间距离的操作符之一。虽然pgvector提供了与这些操作符等价的函数,如果order by之后使用的是这些函数,仍然不会使用ivfflat索引进行优化,即便这些函数名看起来更加的直白易懂。
- 可能返回少于预期的结果集。由于使用ivfflat索引时,只会扫描距离输入向量最为接近的top n个聚类,即便用户预期的结果集大小大于top n个聚类,仍然只返回top n个聚类内的数据,这似乎是有悖于sql标准的。由于相似向量搜索往往也只关心前几个最为相似的向量,这也不会带来什么严重的问题,但我们仍然要知道它这一特性,否则可能会被这样的结果惊吓到。
本篇文章分享了两个使用pgvector的例子,并介绍pgvector的原理和实现细节,期望各位读者能够在冗长的文字中有所收获。由于篇幅原因,仍然有些细节仍然没有讲到,比如postgresql提供的用于定义新索引类型的各种机制,以及pgvector的另外一种索引类型hnsw等,这些细节期望在后续分享中再给大家进行更为详尽的分析。q1:有没有对向量进行异构计算的计划?比如利用GPU对向量进行异构计算加速。a1:PG是一个扩展性非常强数据库,如果与向量相关的计算量非常大,完全可以定制相应的算子将这些计算推到GPU上完成,这在pg数据库下并不复杂。a2:执行是通过采用原数据数据,然后使用knn聚类算法计算出来的。如果已有的数据量少于聚类数,则会随机产生质心向量。q3:如果每个聚类区域中的向量数量很大,那么搜索会很慢,你们有什么办法解决吗?a3:ivfflat索引可以通过调整lists和probes参数,减少搜索的向量。也可以尝试pgvector另外的一种索引hnsw,相比ivfflat索引,其搜索的向量数也会少很多。a4:不是不建议继续插入数据,而是建议数据变化较大时重建索引。https://doc.kunlunbase.com/zh/Klustron_Instruction_Manual.htmlhttps://doc.kunlunbase.com/zh/Klustron_Quickly_Guide.htmlhttps://doc.kunlunbase.com/zh/Klustron-function-experience-example.htmlhttps://doc.kunlunbase.com/zh/product-usage-and-evaluation-guidelines.html同时欢迎大家扫码👇添加小助手(备注:加入Klustron技术交流群)欢迎大家在交流群共同探讨更多问题及主题。