




一. 为什么做曝光控量
找到行业突破点是每个产业都会面临的问题。
当今短视频行业,泛品类短视频行业的格局基本已经形成,机会存在于特定品类短视频垂直领域中。
当一个短视频流产品用户群体稳定后,对不同类别的短视频偏好也基本确定了,这时会出现两个问题
1. 是头部类别曝光量集中的问题
2. 是扩展新的短视频类别后流量分配不足的问题
这两个问题导致特定品类的短视频质量信号获取变得困难。
曝光控量的目标就是快速验证各个不同类别短视频在大全用户群体中的偏好,选出头部偏好品类,大力扩展库存并推广。
综上,本项目的核心目标是短视频各个类别的曝光占比定量控制。
二、总体设计
项目总体设计由三个逻辑核心构成:
1. 各品类曝光量占比的实时统计,类别欠曝光和过曝光计算
2. 引擎根据类别播控信息,做视频的插入和屏蔽
3. 实时曝光控量数据图表展示
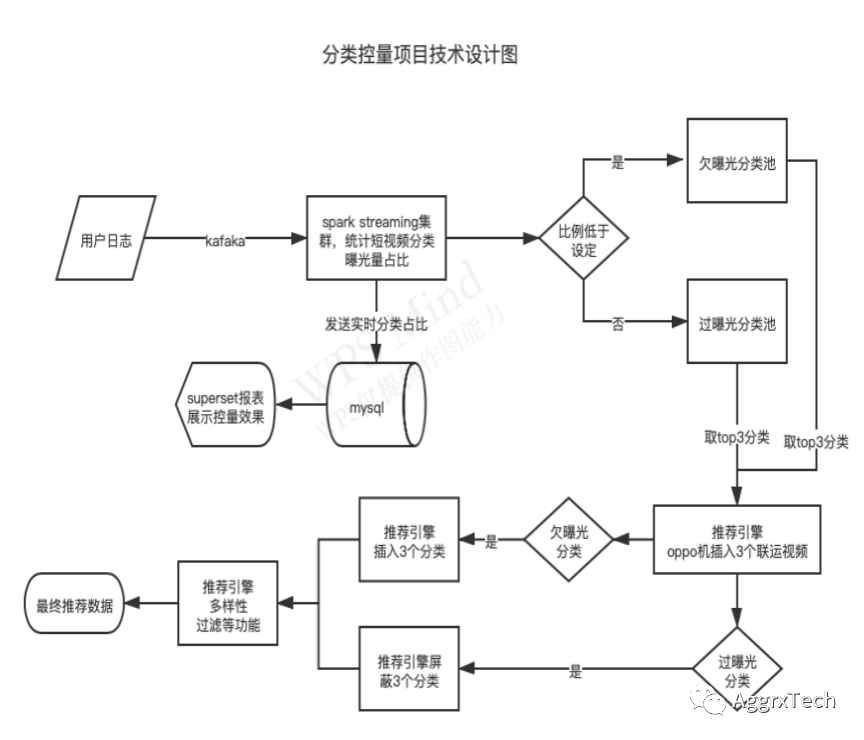
三. 方案实施
3.1 分类过曝光欠曝光实时计算
分类控量计算具体流程如下图所示

3.1.1基于spark steaming的日志获取和解析
用户行为日志为常规的json格式,实时获取kafka中的日志后,解析json,依据曝光条件,取得特定场景下的视频曝光。
由于采用了对视频曝光采用小批量整合上报模式,故解析曝光时,使用的是jsonArray的形式。getKey函数,依据输入的参数判定视频是否是短视频,是否属于短视频信息流,并生成对应key。
val gatherid = obj.getString("gatherid")val gatheridArr = JSON.parseArray(gatherid)val aidArr = for(i <- (0 until gatheridArr.size()).toArray) yield{val objAid = gatheridArr.getJSONObject(i)val bucket = if(objAid.containsKey("bucket")) objAid.getString("bucket") else ""val vt = if(objAid.containsKey("vt")) objAid.getString("vt") else ""val aid = if(objAid.containsKey("aid")) objAid.getString("aid") else ""val key = getKey(aid,vt,bucket,obj)(key,(1,0))}aidArr.filterNot(_._1=="")复制
3.2.2短视频类别曝光控量判定
同一批次的数据中,存在同一视频多次曝光的情况
我们先将相同视频的曝光量合并,然后映射成对应分类的曝光量,最后将分类曝光量合并
//视频曝光量,映射为分类曝光量userInfo.mapPartitions(it => {val short2category = bcShort2category.valueit.map{case(keyAid,(exp,click)) => {val aid = keyAid.split("_").lastval category = short2category.getOrElse(aid,"")(category,(exp,click))}}}).reduceByKey((a,b) => (a._1+b._1,a._2+b._2))复制
经过上述操作后,我们得到了当前批次数据中,每个分类的曝光量。然后取出存在redis中的当日分类曝光数据做累加,并重新写入redis备用。
每个分类的曝光控量,按自然日统计播控,故设置redis过期时间为0点前。跨天后,数据重新累计
// 每天 0 点差15s的时候redis存储过期,第二天重新开始计数val expiresTime = ((millisOfDay - todayMillis)*0.99).toLongval redisPrefix = "category_exp_"partition.foreach { case (category, (exp, click)) =>try{//获取redis中存储的分类曝光量,并累加最新批次的分类曝光量,然后重新写入redis中val redisExp = jedis.get(redisPrefix+category)val newExp = if(redisExp==null) exp else exp+redisExp.toIntjedis.psetex(redisPrefix+category,expiresTime,newExp+"")}catch {case ex: Throwable => {println("categoryLimit write reids error:%s".format(ex.toString + "\n" + ex.getStackTrace.map(_.toString).mkString("\n")))jedis.close()jedis = DQRedisClient.pool.getResource}}复制
经过上述计算后,得到了当日短视频流内,每个分类的曝光量。
由此可计算出每个分类的曝光量占比,和设定的曝光量占比做对比后,可得出哪些分类过曝光,哪些分类欠曝光。
为了避免过于频繁的播控,将控量阈值设置为0.5%,曝光量超过设置的阈值,则判定为过曝光,需要做过滤处理。曝光量低于阈值,则判定为欠曝光,需要增加曝光量。
//获取设定的分类曝光限定,和实际曝光占比做比较,计算得到过曝光和欠曝光分类val categoryLimit = bcCategoryLimit.valueval categroyLimitExp = categoryLimit.map{case(category,ratio) => {val redisExp = jedis.get(redisPrefix+category)val exp = if(redisExp==null) 0 else redisExp.toInt(category,ratio,exp)}}val allExp = categroyLimitExp.map(_._3).sum.toDoubleval categoryControl = categroyLimitExp.map{case(category,ratio,exp) => {val onlineRatio = exp/allExp//正差值,欠曝光;负差值,过曝光val controlRatio = ratio - onlineRatio(category,controlRatio,ratio,onlineRatio,exp)}}.sortBy(-_._2)//计算得到欠曝光超过0.5%的分类,取3个分类val topExpArr = categoryControl.filter(_._2>=0.005).take(3)//如果欠曝光超过0.5%的分类补足3个,则随机取欠曝光小于0.5%的分类补足3个val randomExpArr = categoryControl.filter(x => x._2<0.005 && x._2>0).map(x => (x,rand.nextInt(30))).sortBy(_._2).map(x => {println("rand:%s %s".format(x._2,x._1));x._1}).take(3-topExpArr.size)//生成欠曝光分类数组val expArr = topExpArr.++(randomExpArr).map(x =>"SUBCID_%s_10".format(x._1))//生成过曝光分类数组,取3个分类做过滤控制val filterArr = categoryControl.filter(x => x._2 < -0.005).takeRight(3).map(x => "SUBCID_%s_10".format(x._1))val jsonInfo = getControlJson(area,expArr,filterArr,"SUBCATEGORY")//分类控量信息写入redis中,供引擎使用val kvRocks = DQKVRocksClient.pool.getResourcekvRocks.setex("category_exp_control",3600,jsonInfo.toString)复制
自此分类曝光控量的计算部分已经完成。播控数据写入redis,引擎在每次处理信息流请求时,读取播控信息,做对应的过滤和插入操作。
3.2 分类播控在引擎的实现
具体的分类播控在引擎端实现。针对每个用的信息流请求,引擎从redis获取分类播控信息。在多维特征召回用户推荐排序结果后,过滤掉其中过曝光的分类,并在固定位置插入3个欠曝光的分类。
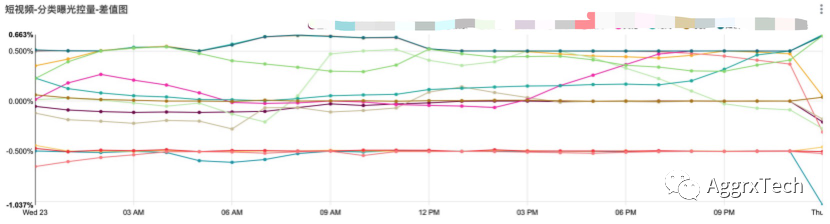
3.3 分类播控的报表展示
分类曝光占比数据每15秒(spark streaming的数据批次窗口时间)写入一次mysql,记录字段为“日期、小时、分类、曝光占比、设定占比、曝光量”,报表的时间精度是小时级别,这样的选择既可以保证效果监控,又可以减少数据存储量。
四、总结
内容冷启动是所有产品都会遇到的需求,项目通过spark streaming实时计算+引擎实时干预推荐排序+superset实时展示播控效果的方式实现控量需要。
文中项目的需求是分类粒度的曝光控量,在相同计算框架下,同样可以进行不同粒度的内容测试,例如游戏分类中的不同游戏测试。
文中的计算框架同样支持内容加减权操作,即在已有排序的基础上,通过加减权影响排序的方式控制内容曝光量,加减权的优点是对分发效果影响较小,缺点是内容控量占比准确度较低。
曝光控量项目的实现是基于常规计算框架,实现的过程中存在很多不同的选择和优化,欢迎小伙伴共同讨论,提出宝贵建议,谢谢。
