




PolarDB PostgreSQL版(以下简称 PolarDB-PG)是一款阿里云自主研发的企业级数据库产品,采用计算存储分离架构,兼容 PostgreSQL 与 Oracle。PolarDB-PG 的存储与计算能力均可横向扩展,具有高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB-PG 具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载;还具有时空、向量、搜索、图谱等多模创新特性,可以满足企业对数据处理日新月异的新需求。
四、中小企业如何选用数据库
中小企业选用数据库也希望数据能提供对小表数据高速低延迟的响应能力,除了希望满足海量数据存储能力,也希望数据多种支持大数据的集成解决能力。所以理想中的数据库可以提供以下能力。
• 提供快于磁盘架构数十倍的读写速度,支持高速的随机访问,在无锁表结构的支持下,能够满足大并发下的高吞吐高性能。
• 还提供基于内存计算磁盘备份存储的列式存储架构,支持对超大表进行快速存储计算分析。
• 数据库内置多种算法,讲普通SQL查询语句和复杂关联语句进行编译优化为机器代码,提升分析性能。
• 通过数据联邦的集成能力, 通过创建连接器对不同数据源数据进行跨源访问查询,独创的自适应下推优化技术和即时本机代码编译(JUST-IN-TIME)技术,能优化加速跨源访问查询效率。
• 擅长于OLAP应用场景,同时满足HTAP场景需求,支持MYSQL语法协议,易上手,开发难度小。
通过PolarDB与RapidsDB的federation强强联手,可以发挥更大的威力。
在 RapidsDB 的数据库架构里,数据库联邦是一个逻辑的数据容器。数据库管理员可以在RapidsDB 里根据不同业务场景创建多个联邦(federation)对象,每个联邦对象里面再通过创建不同的数据库连接器(connector)对象,在一个联邦对象中组织来自于 RapidsDB 自身,和通过连接器连接的不同数据源。在通过连接器获得指定的各种数据后,用户就可以对一个联邦对象中的数据执行各种查询语句来进行数据分析工作。
以下图为例,如果一个 RapidsDB 数据库里面有“Engineering”和”Sales”两个联邦对象,那么Engineering 这个联邦对象的数据可以这样表现:Engineering (s1, v1, m1.1),Sales (m1.1,m1.2, s2)。这当中,MySQL这个外部数据源有两个数据库:m1.1 和 m1.2,Engineering 联邦只能够访问 m1.1,而 Sales 能够访问 MySQL的两个数据库。
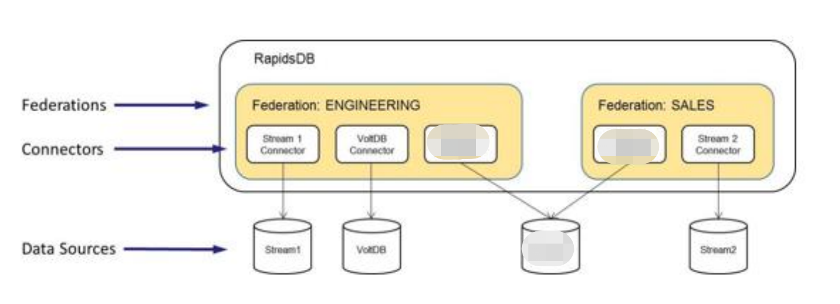
在 RapidsDB 里数据库管理员创建的不同数据库联邦对象,形成了用户能够访问的数据范围
的边界。一个查询语句只能针对一个联邦对象中的数据进行查询,而不能交叉两个或更多
的联邦对象的数据进行查询。
