Tair Serverless KV 是阿里云瑶池数据库旗下云数据库 Tair 推出的全新产品。它是一款能够自动弹性伸缩的分布式持久化 KV 数据库,接口兼容 Redis。它的优点包括:
用户在使用Tair Serverless KV时无需关注业务负载及资源(规格)配置、无需在业务负载发生变化时,对数据库系统进行配置调整以满足不同阶段的业务需求,例如:在运营活动前升级资源以满足更高的负载需求,在运营活动结束后降配以节约资源使用成本。
Tair Serverless KV能够根据实际的请求负载实现全自动的弹性伸缩,因此能够大幅度降低数据库系统在资源视角的运维管理复杂度。
Serverless 计费模型与常见的“以规格计费”不同,它没有规格的概念,完全以业务系统对数据库的调用次数进行计费,因此在业务低峰期时只需付出极低的计算费用,甚至在没有请求时能够做到计算费用为 0 且无需停机。
Tair Serverless KV 无规格概念,并实现了计算与存储的独立计费。Tair Serverless KV 的计算以“CU”为计量单位,并以实际应用程序调用次数进行计费。大多数的业务模型都存在访问的“波峰”与“波谷”,而按调用次数进行计费的方式能够在业务波谷期实现计算费用的显著降低,因此“在没有产生任何读写请求的时候,计算费用将会为 0。”Tair Serverless KV 的存储没有“可用存储空间”或“已购买存储空间”的概念,它以实际用量的日平均值进行计费。相比常见的以“所购买的存储空间”进行计费的方式,Tair Serverless KV 消除了数据存储中的“剩余空间”概念,因此也不再会发生存储空间的浪费,同时用户也无需关注存储空间的扩容与缩容。在一些特定业务模型带来的数据存储量的大幅度波动场景中,这一计费模型的成本优势将更加显著。
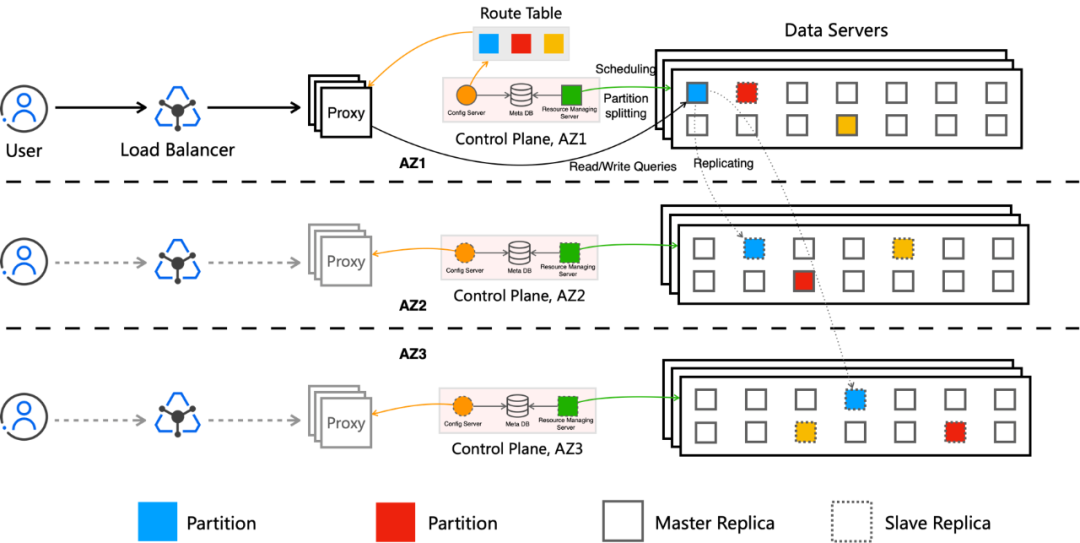
Tair Serverless KV 为分布式架构,包含DataServer, ControlPlane, Proxy/LoadBalancer等关键组件。
数据服务节点,提供数据存储和数据访问的能力。用户的数据分成多个分区(Partition),按照 Key 进行分区管理,并通过Replica存放在多个DataServer上。每个Partition各自有Master Replica和Slave Replica进行数据同步。不同用户的不同Replica会部署在同一个机器上进行隔离存储。数据控制节点,提供了弹性和数据路由的管理。控制节点会实时监控数据节点当前的运行和负载状态,包括每个租户的访问和资源使用情况。当租户需要获取临时弹性的能力,或者被限流后需要扩容CU和存储容量时,会进行自动的调度。控制节点会尽量确保每个DataServer具备足够的垂直扩容能力来应对突发的流量增长。主要负责请求的负载均衡和数据的请求分发,通过ControlPlane生成的分区管理信息,选择数据访问路由到具体的DataServer节点。在上文中提到的相关组件均采用三可用区部署(商业化版本),可以容忍可用区(Availability Zone, AZ)级别的整体故障。
数据分布在多个可用区 AZ 中,在上述的架构介绍中提到每个租户的实例均会被分成多个Partition,每个Partition会由Replica存储在不同的 AZ。
这种分布方式确保了数据冗余和负载均衡,即使一个 AZ 出现故障,其他 AZ 中的数据仍然可用,从而保证了系统的持续运行。
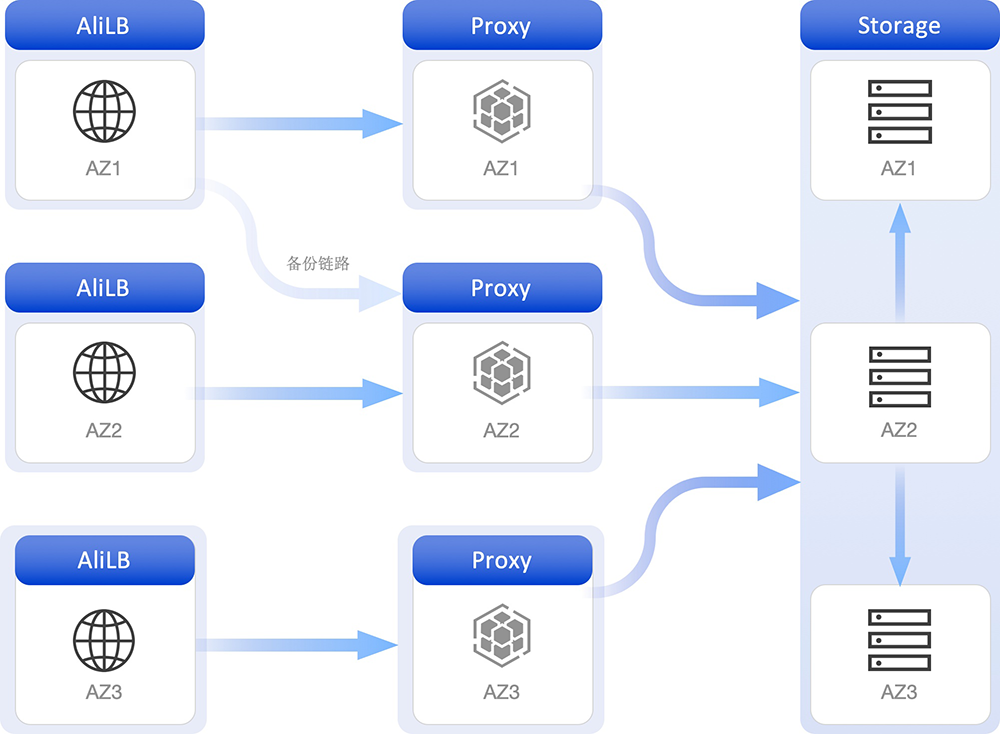
同时负载均衡组件和Proxy也采用多可用区部署的方式。通过这种方式,用户在任意一个可用区可实现就近访问,减少跨可用区数据交换从而降低延迟。
Tair Serverless KV具有多层独立探活、自动故障检测和恢复机制。当检测到某个 AZ 出现故障时,系统会自动将请求路由到其他健康 AZ 的节点,并在故障 AZ 恢复后自动同步数据。
这种机制确保了在故障发生时的透明切换和恢复后的数据一致性,且无需手动干预。
在数据可靠性层面采用三副本模式,写入操作至少完成双副本写入才算成功,任一副本故障切换RPO=0。当其中一个可用区故障或者数据节点出现问题的时候不会影响数据访问。Serverless KV提供自动备份功能,能够定期备份数据并且存储到OSS上,确保数据在意外删除或损坏时可以恢复。通过实时上传增量日志支持按照特定时间点进行恢复(PITR),支持按Key或Key Pattern恢复。适用于确保高级别数据安全,数据回档,数据意外错误等应用场景。
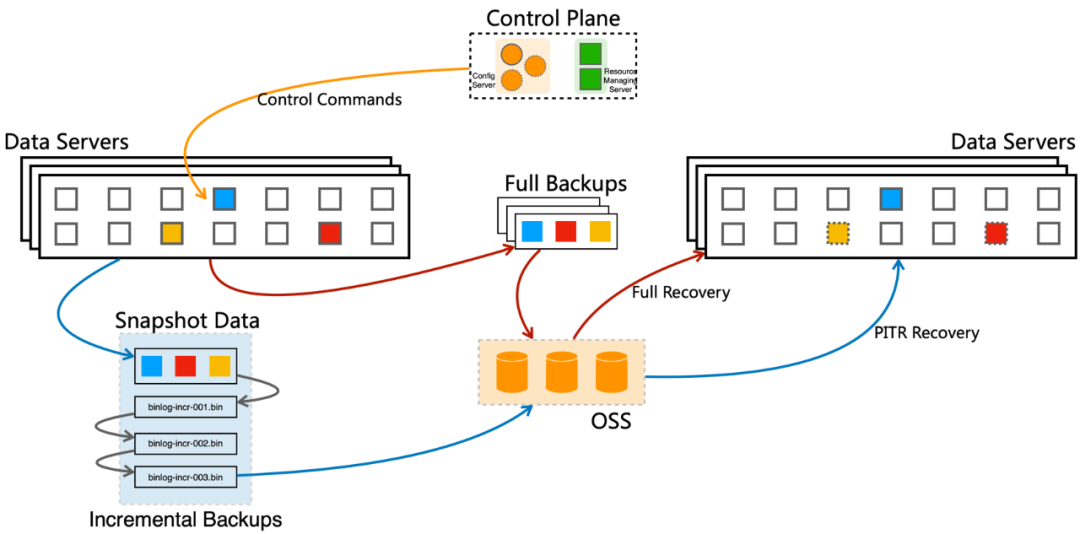 数据备份恢复支持跨区域容灾:通过跨区域数据复制的能力,Tair Serverless KV 可以实现地域级别的容灾,确保在地域级故障时业务能够快速恢复。Tair Serverless KV从单分区,单节点和单实例等多个弹性维度来增强整体服务的扩展能力,下面我们逐一介绍各个维度提供的弹性能力。正常情况下,调度系统会为各分区预留一定的性能资源(称为预留性能水位),当分区流量上升时可立即提供最大2倍于常态流量的吞吐量。同时针对KV系统中经常会出现的流量短期突增,Tair Serverless KV进一步为分区提供一定的突发额度,用于应对吞吐量突增。当分区的流量超过预留性能水位时,则会利用这些突发额度来处理额外的请求。如下图我们假设该分区的常态性能水位为1000CU/s,预留性能水位为常态的2倍即2000CU/s。在吞吐量小于2000CU/s时,不会触发限流。当吞吐量超过2000CU/s时,会先通过消耗突发额度来尽可能响应请求,以满足大部分短期突增。突发额度消耗完后会触发限流,分区将拒绝部分请求以保证吞吐量控制在预留性能水位(2000CU/s)以下。
数据备份恢复支持跨区域容灾:通过跨区域数据复制的能力,Tair Serverless KV 可以实现地域级别的容灾,确保在地域级故障时业务能够快速恢复。Tair Serverless KV从单分区,单节点和单实例等多个弹性维度来增强整体服务的扩展能力,下面我们逐一介绍各个维度提供的弹性能力。正常情况下,调度系统会为各分区预留一定的性能资源(称为预留性能水位),当分区流量上升时可立即提供最大2倍于常态流量的吞吐量。同时针对KV系统中经常会出现的流量短期突增,Tair Serverless KV进一步为分区提供一定的突发额度,用于应对吞吐量突增。当分区的流量超过预留性能水位时,则会利用这些突发额度来处理额外的请求。如下图我们假设该分区的常态性能水位为1000CU/s,预留性能水位为常态的2倍即2000CU/s。在吞吐量小于2000CU/s时,不会触发限流。当吞吐量超过2000CU/s时,会先通过消耗突发额度来尽可能响应请求,以满足大部分短期突增。突发额度消耗完后会触发限流,分区将拒绝部分请求以保证吞吐量控制在预留性能水位(2000CU/s)以下。通过以上方式可以帮助处理短期的负载峰值,提高系统的灵活性。
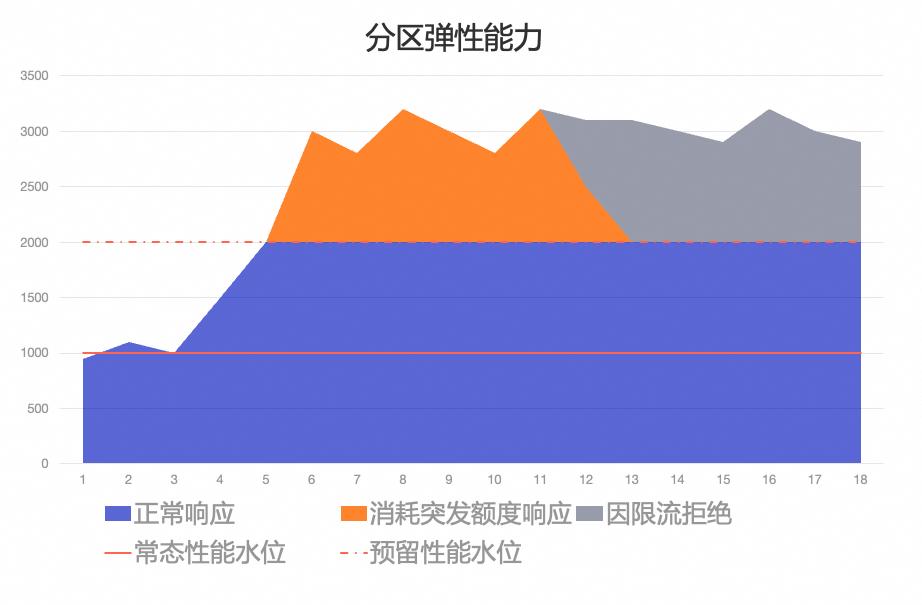 分区弹性能力Serverless KV通过实时监控吞吐量和存储使用情况,主动平衡分配在各存储节点上的分区,从而降低节点过载带来的可用性风险。同时每个数据节点都会独立监控其托管的所有副本的总吞吐量和数据大小。如果吞吐量超出节点最大容量的阈值百分比,控制节点会选择将这些副本从当前节点迁出。控制节点会为这些分区副本寻找在同一或另一个可用区中没有该分区副本的新存储节点,以实现负载均衡和资源优化。在当前分区数量无法满足吞吐需求时,调度系统会自动发起分区扩容。在实际使用中,经常会出现实例维度的各分片访问不均衡的情况。例如在 Redis Cluster 每个分片的请求能力都均等固定的情况下,当一个分片的请求(例如典型热点问题)造成 CPU 用尽,在超过该分片的处理能力后,通常需要扩展整个集群来支撑,这样会导致整体资源的使用浪费,并且扩容时数据搬迁时间较长致使无法快速缓解问题。
分区弹性能力Serverless KV通过实时监控吞吐量和存储使用情况,主动平衡分配在各存储节点上的分区,从而降低节点过载带来的可用性风险。同时每个数据节点都会独立监控其托管的所有副本的总吞吐量和数据大小。如果吞吐量超出节点最大容量的阈值百分比,控制节点会选择将这些副本从当前节点迁出。控制节点会为这些分区副本寻找在同一或另一个可用区中没有该分区副本的新存储节点,以实现负载均衡和资源优化。在当前分区数量无法满足吞吐需求时,调度系统会自动发起分区扩容。在实际使用中,经常会出现实例维度的各分片访问不均衡的情况。例如在 Redis Cluster 每个分片的请求能力都均等固定的情况下,当一个分片的请求(例如典型热点问题)造成 CPU 用尽,在超过该分片的处理能力后,通常需要扩展整个集群来支撑,这样会导致整体资源的使用浪费,并且扩容时数据搬迁时间较长致使无法快速缓解问题。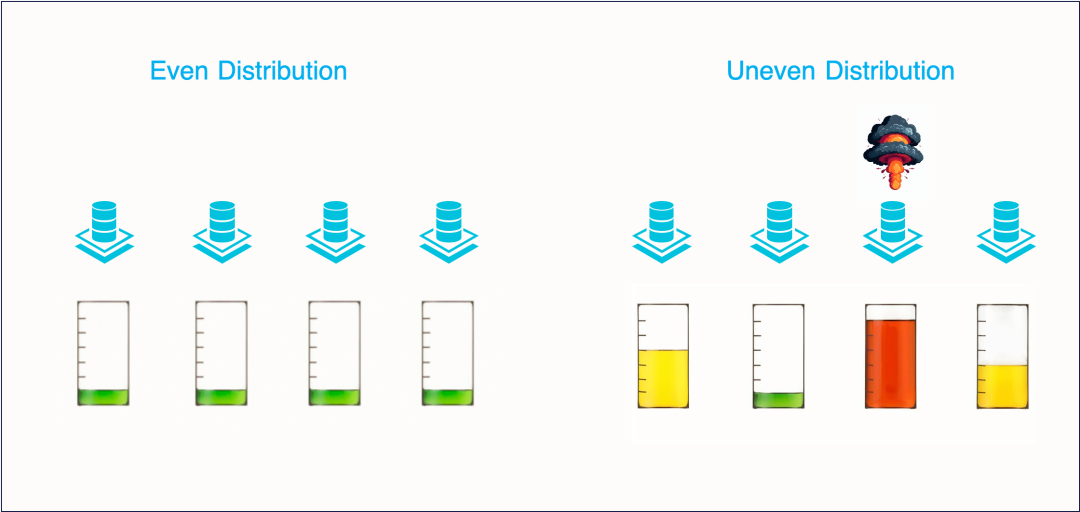 数据访问倾斜
数据访问倾斜
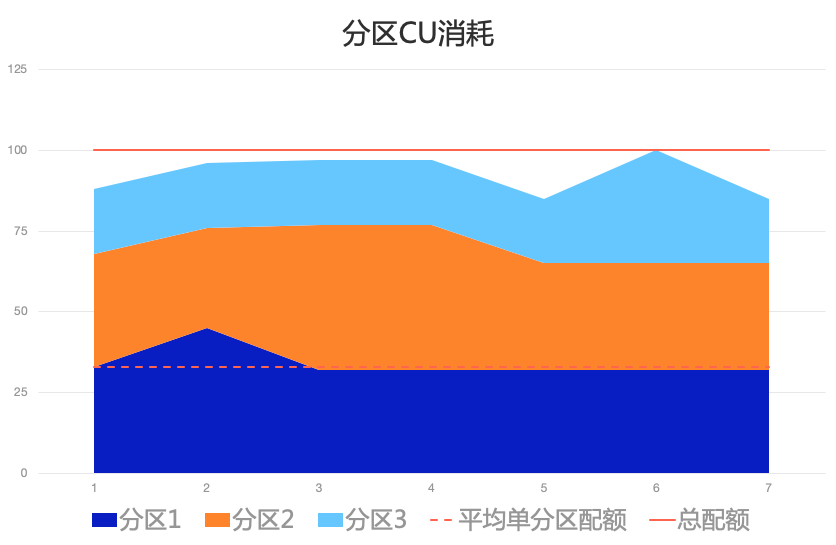
Tair Serverless KV 的CU容量监控与调整机制会主动监控所有分区副本的分配CU容量和已使用CU容量。如果出现单分区副本限流且未超出当前实例整体CU容量,则控制和调度节点会自动增加相关分区的CU分配。如下图所示,该实例共有三个分区,每个分区的处理能力均为25CU,在图中的时间点 2 位置,分区1超过25CU后理论上会被限流,但因为其它分区(2和3)的CU消耗较低,因此控制节点进行了临时调整,使分区 1 获得更多CU来解决分区请求超限的问题。
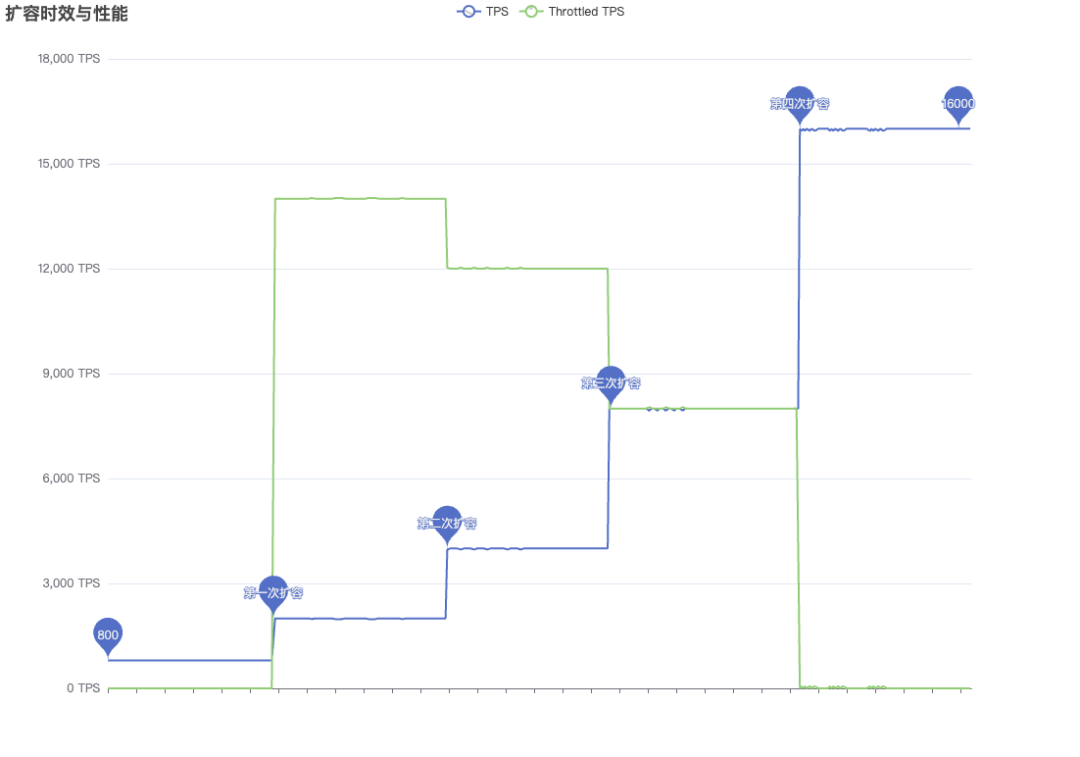
 自适应CU容量调整这里我们通过模拟客户端的TPS(由800激增至2W),来说明实例性能如何逐步的弹性扩展。▶︎ 实例初始状态能够提供 1000CU(为了便于理解,图示中的 1TPS 恰好消耗1CU,下文同理)的写入。当我们以 512B(单次写入数据量) 进行写入并达到 800 TPS 的时候,所有写入均正常(无限流)。▶︎ 当写入量激增至 2W TPS 后, 实例能够立即提供初始CU的2倍支撑,即2000CU的写入能力,而超出服务能力部分的写请求(绿线)则被限流。▶︎ 发生限流后,调度系统将识别到此事件并进行扩容。决策下发扩容指令(扩容一倍)。如上图所示,在限流 5 秒后系统完成了第一次扩容,此时 CU 扩展至 2K,CU 预留水位达到 4K。由于每两次扩容存在 30 分钟左右的等待周期,因此此时系统不会立即进行下一次扩容。▶︎ 在20分钟时间位置,调度系统识别到实例CU能力受限事件,决策下发扩容指令(再次扩容一倍)。在24分钟时间位置,实例完成扩容,此时 CU 扩展至 4K,CU 预留水位达到 8K。▶︎ 此后分系统分别在42分钟时间位置及1小时6分钟时间位置进行扩容,最终实例的 CU 达到16K,CU 预留水位达到 32K,此时写入不再发生限流。Tair Serverless KV以全托管、零运维的弹性能力重新定义了云原生数据库的服务边界。其灵活的CU动态调配与存储按需计费模式,不仅化解了传统数据库资源预配的浪费难题,更通过秒级弹性响应与多级容灾架构,为高波动业务提供了兼具成本效益与稳定性的技术底座。随着公测的正式启动,开发者得以摆脱资源规划的束缚,聚焦业务创新,真正实现“流量无惧峰谷,成本随需而动”的云端数据库体验。
自适应CU容量调整这里我们通过模拟客户端的TPS(由800激增至2W),来说明实例性能如何逐步的弹性扩展。▶︎ 实例初始状态能够提供 1000CU(为了便于理解,图示中的 1TPS 恰好消耗1CU,下文同理)的写入。当我们以 512B(单次写入数据量) 进行写入并达到 800 TPS 的时候,所有写入均正常(无限流)。▶︎ 当写入量激增至 2W TPS 后, 实例能够立即提供初始CU的2倍支撑,即2000CU的写入能力,而超出服务能力部分的写请求(绿线)则被限流。▶︎ 发生限流后,调度系统将识别到此事件并进行扩容。决策下发扩容指令(扩容一倍)。如上图所示,在限流 5 秒后系统完成了第一次扩容,此时 CU 扩展至 2K,CU 预留水位达到 4K。由于每两次扩容存在 30 分钟左右的等待周期,因此此时系统不会立即进行下一次扩容。▶︎ 在20分钟时间位置,调度系统识别到实例CU能力受限事件,决策下发扩容指令(再次扩容一倍)。在24分钟时间位置,实例完成扩容,此时 CU 扩展至 4K,CU 预留水位达到 8K。▶︎ 此后分系统分别在42分钟时间位置及1小时6分钟时间位置进行扩容,最终实例的 CU 达到16K,CU 预留水位达到 32K,此时写入不再发生限流。Tair Serverless KV以全托管、零运维的弹性能力重新定义了云原生数据库的服务边界。其灵活的CU动态调配与存储按需计费模式,不仅化解了传统数据库资源预配的浪费难题,更通过秒级弹性响应与多级容灾架构,为高波动业务提供了兼具成本效益与稳定性的技术底座。随着公测的正式启动,开发者得以摆脱资源规划的束缚,聚焦业务创新,真正实现“流量无惧峰谷,成本随需而动”的云端数据库体验。👇点击文末「阅读原文」免费申请公测