




数据库在写入或更新资料时,要确保事务始终保持ACID的特性。当系统发生故障时,数据库通过事务日志回放来保证故障恢复后数据不丢失。
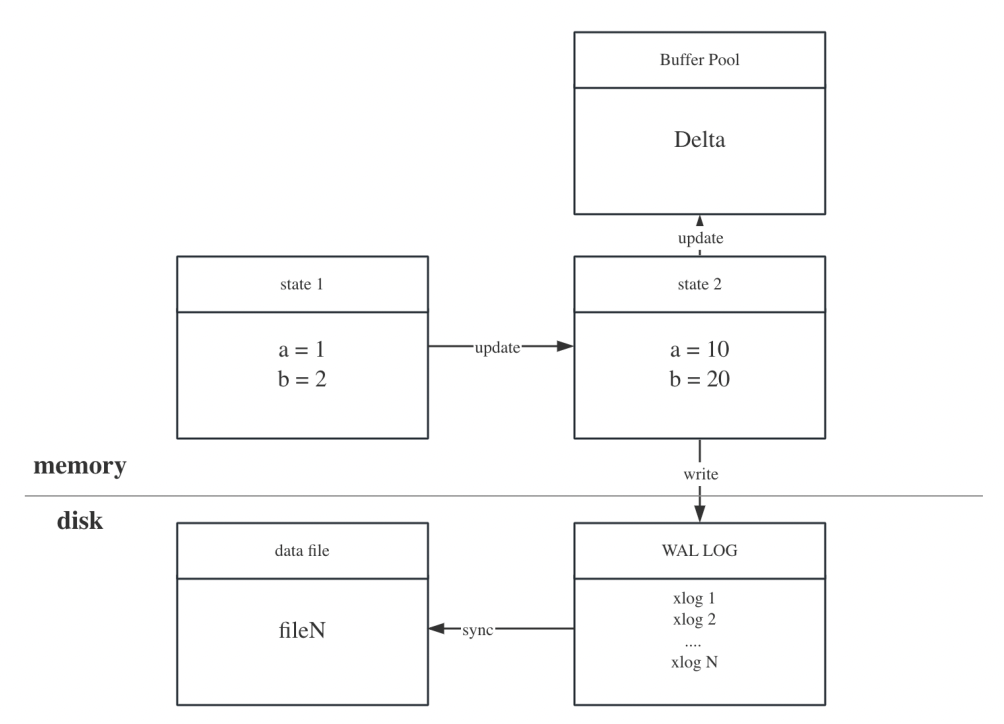 图1:单机WAL log流程示意图
图1:单机WAL log流程示意图
 图2:联机WAL log流程示意图
图2:联机WAL log流程示意图
不同的数据库对WAL log实现的需求点也有所区别,主要体现在四个方面:
首先是格式,一般由meta+data两个部分组成。meta部分记录了关联资源的元信息,data是资源自定的裸数据。meta和data可以分开存储,也可以统一存储。分开存储时,单条WAL log需要先读取完整的meta,再按需求解data;统一存储时,可以一条条解。举个例子,在分开存储时,数据组成往往是meta1+meta2.. metaN+data1+data2...dataN;而在统一存储时,数据组成往往是meta1+data1+meta2+data2...metaN+dataN。 其次,在修改数据时有undo log和redo log两种方式。undo log从后往前写,redo log从前往后写。PostgreSQL采用的是redo log。 此外,循环校验码信息(CRC)分为完整数据和分段数据两种。分段CRC的优点是当出现错误时,能够快速定位到坏的块数据,且损坏的范围很小,但代价是速度较慢;相比之下,完整数据的CRC读写速度更快,但如果单个meta损坏,则可能导致整个WAL log都损坏,恢复成本较高。 最后,是否需要落盘,这主要取决于具体场景,如果只做同步和备份,可以考虑不落盘。
在PostgreSQL中,WAL log由头部、块头部、块私有数据块、自定义资源数据块四部分组成。
 图3:PostgreSQL中WAL log构成图
图3:PostgreSQL中WAL log构成图
WAL log在执行过程中,数据量会不断地累积,当达到一定数量后,会对系统性能产生影响,因此需要定时清理WAL log数据。
如图4所示,在GPDB中,数据恢复的过程包含了数据重放。数据库启动时,会有startup进程打开checkpoint redo文件,开始按顺序读取xlog,进行恢复操作。

在联机场景下,primary/master集群完成数据恢复后,会退出recovery,这时WAL sender进程仍会不断会向从节点发送xlog信息。 此时,在mirror/standby集群中 startup进程则不会退出,而是会通过WAL receiver不断地接收xlog信息,并在startup进程中进行replay操作。
 图5:replay操作流程示意图
图5:replay操作流程示意图
如图5所示,备库不断地从主库同步相应的日志数据,并在备库应用每个WAL record,流复制每次传输WAL日志的record;主库启动WAL sender进程,主要负责将主服务器产生的WAL日志记录发送给从库。
相应地,从库启动WAL receiver进程,与对应的WAL sender进程通讯,负责接收主库发送的WAL日志记录;同时,从库启动startup进程,负责将WAL receiver进程接收到WAL日志记录在从库上replay,从而达成主从的数据同步。在GPDB中,默认支持同步复制,同时也支持异步复制。
示例:insert场景下WAL log的变化
 图6:insert场景下WAL log的变化
图6:insert场景下WAL log的变化
在此前的PostgreSQL版本中,rmgr是一个静态的enum。如果要增加新的Resource Managers,需要在内核里去定义。
PostgreSQL中的WAL机制的核心思想是:先日志落盘,后数据落盘。在写数据到磁盘里成为固定数据之前,先写入到日志里。
相关阅读:
PostgreSQL 技术内幕(八)源码分析——投影算子和表达式计算
PostgreSQL 技术内幕(六)Greenplum 排序算子
PostgreSQL 技术内幕(五)Greenplum-Interconnect模块
PostgreSQL 技术内幕(二)Greenplum-AO表
欢迎大家扫描下方二维码,添加企微小助手联系我们,获取HashData产品与活动的最新资讯!


HashData研发、行业销售、工程服务等岗位正在火热招聘中!扫描下图二维码,可获取职位详细信息,加入我们的团队!

评论

 0 点赞
0 点赞 1 1 1 1
1 1 1 1 0 点赞
0 点赞 0 点赞 0 点赞
0 点赞 0 点赞


